从前端点击到后端响应过程
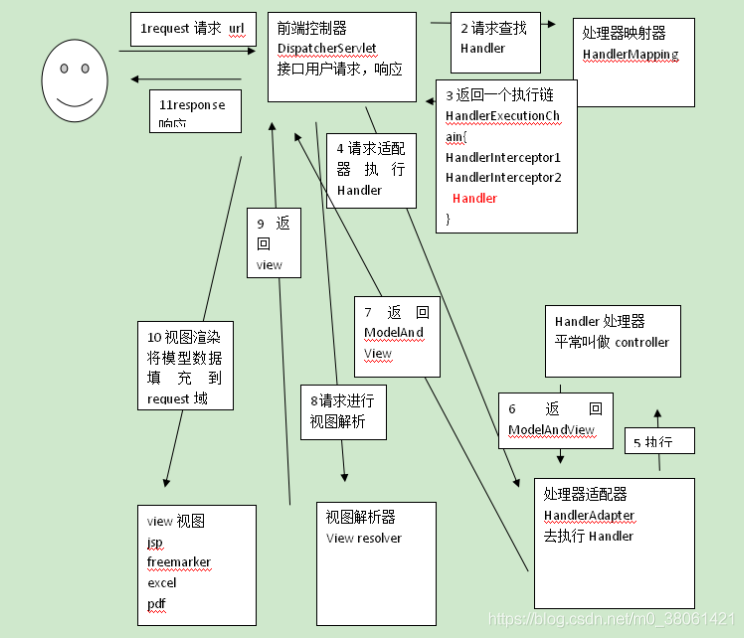
- 发起请求到前端控制器(DispatcherServlet)
- 前端控制器请求HandlerMapping(处理器映射器)查找Handler(可以根据xml配置或注解进行查找)
- 处理器映射器(HandlerMapping)向前端控制器返回Handler
- 前端控制器调用处理器适配器(HandlerAdapter)去执行Handler
- 处理器适配器去执行Handler
- Handler执行完后返回ModelAndView
- 处理器适配器向前端控制器返回ModelAndView(ModelAndView是Springmvc框架的一个底层对象,包括Model和view)
- 前端控制器请求视图解析器(View Resolver)去进行视图解析根据逻辑视图名解析成真正的视图(jsp)
- 视图解析器向前端控制器返回View
- 前端控制器进行视图渲染,视图渲染将模型数据(在ModelAndView对象中)填充到request域
- 前端控制器向用户响应结果
Spring bean的生命周期
- 启动spring容器,也就是创建beanFactory(bean工厂),一般用的是beanFactory的子类applicationcontext,applicationcontext比一般的beanFactory要多很多功能,比如aop、事件等。通过applicationcontext加载配置文件,或者利用注解的方式扫描将bean的配置信息加载到spring容器里面。
- 加载之后,spring容器会将这些配置信息(java bean的信息),封装成BeanDefinition对象。BeanDefinition对象其实就是普通java对象之上再封装一层,赋予一些spring框架需要用到的属性,比如是否单例,是否懒加载等等。
然后将这些BeanDefinition对象以key为beanName,值为BeanDefinition对象的形式存入到一个map里面,
将这个map传入到spring beanfactory去进行springBean的实例化。
传入到spring beanfactory之后,利用BeanFactoryPostProcessor接口这个扩展点去对BeanDefinition对象进行一些属性修改。
- 开始循环BeanDefinition对象进行springBean的实例化,springBean的实例化也就是执行bean的构造方法(单例的Bean放入单例池中,但是此刻还未初始化),在执行实例化的前后,可以通过InstantiationAwareBeanPostProcessor扩展点(作用于所有bean)进行一些修改。
- spring bean实例化之后,就开始注入属性,首先注入自定义的属性,比如标注@autowrite的这些属性,再调用各种Aware接口扩展方法,注入属性(spring特有的属性),比如BeanNameAware.setBeanName,设置Bean的ID或者Name;
初始化bean,对各项属性赋初始化值,初始化前后执行BeanPostProcessor(作用于所有bean)扩展点方法,对bean进行修改。
初始化前后除了BeanPostProcessor扩展点还有其他的扩展点,执行顺序如下:
(1). 初始化前 postProcessBeforeInitialization()
(2). 执行构造方法之后 执行 @PostConstruct 的方法
(3). 所有属性赋初始化值之后 afterPropertiesSet()
(4). 初始化时 配置文件中指定的 init-method 方法
(5). 初始化后 postProcessAfterInitialization()
先执行BeanPostProcessor扩展点的前置方法postProcessBeforeInitialization(),
再执行bean本身的构造方法
再执行@PostConstruct标注的方法
所有属性赋值完成之后执行afterPropertiesSet()
然后执行 配置文件或注解中指定的 init-method 方法
最后执行BeanPostProcessor扩展点的后置方法postProcessAfterInitialization()此时已完成bean的初始化,在程序中就可以通过spring容器拿到这些初始化好的bean。
- 随着容器销毁,springbean也会销毁,销毁前后也有一系列的扩展点。销毁bean之前,执行@PreDestroy 的方法销毁时,执行配置文件或注解中指定的 destroy-method 方法。
Spring 解决循环依赖
构造器注入是无法解决循环依赖得,set方式和注解注入方法可以;原因是构造器注入的方式,在bean实例化时,就必须获取到依赖对象,而set方式可以在对象实例化后,初始化前即可引用”半成品”的引用对象,注解方式同理;
Spring解决循环依赖使用了三级缓存singletonObjects:单例池(一级缓存),容器内(HashMap)存储完整的对象earlySingletonObjects:半成品池(二级缓存),容器内存储“半成品”对象singletonFactories:工厂池(三级缓存),存储了ObjectFactory<?>用于后续循环引用提前生成代理对象(getEarlyBeanReference())
源码解析
singletonFactories容器内新增是在实例化对象之后,填充属性、初始化之前的: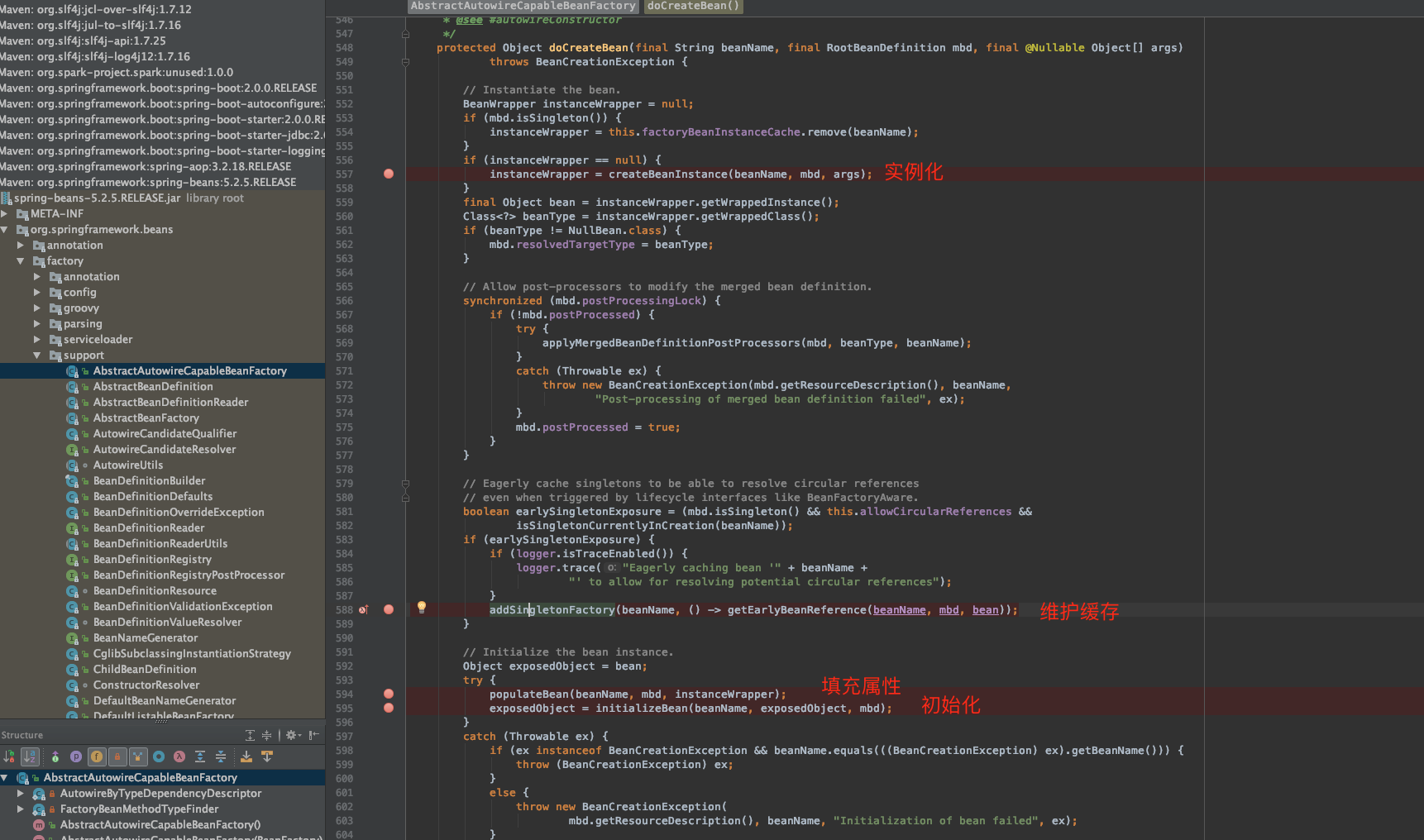
singletonFactories容器内删除是在调用getSingleton方法时候,如果1、2级缓存都不存在,则通过三级缓存的ObjectFactory调用getObject()方法(内部方法实现是addSingleton()方法的getEarlyBeanReference()提前生成暴露出来的对象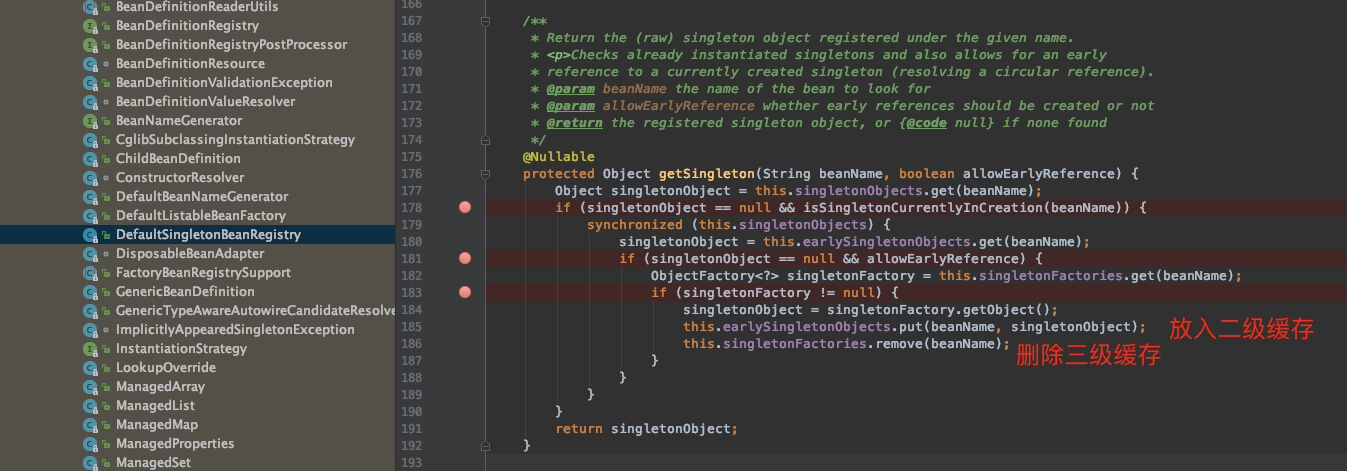
所以当A引用B,B引用A的时候:A实例化后先将自己以<beanName, ObjectFactory>方式放入三级缓存,然后A在populateBean()方法时候发现没有创建B对象,继而去创建B,在创建B的过程中又发现缺少A,调用getSingleton()在三级缓存中发现了A,然后通过getObject()提前生成A(此时A还没有填充属性和初始化),至此B创建完了,A继续填充属性,初始化,至此A创建完成。
为什么要设计三级缓存?
根据上面的解决循环依赖的方式,为什么spring不直接在实例化之后把对象引用对象放到二级缓存,还要浪费重新创建一个ObejctFactory对象工厂存到三级缓存内?
原因是代理对象:如果你直接把实例化对象放到二级缓存,那么B引用的A是其本身,但有可能A在初始化后还需要被BeanPostProcessor处理,生成一个在容器中真正使用的代理对象,而B理应也是引用A的代理对象而不是A本身。
如果为了解决代理对象问题,那我们在实例化后先统一校验,需要生成代理对象的都先生成,然后放入到二级缓存中。这样的设计功能上是可行的,但是我个人认为违背了Spring的bean的创建流程规则:bean实例化-填充属性-初始化-AOP后置处理。本身大部分没有循环依赖的对象都不必提前暴露生成半成品对象;
我们看下Spring三级缓存内的ObjectFactory的getObject方法内部底层实现: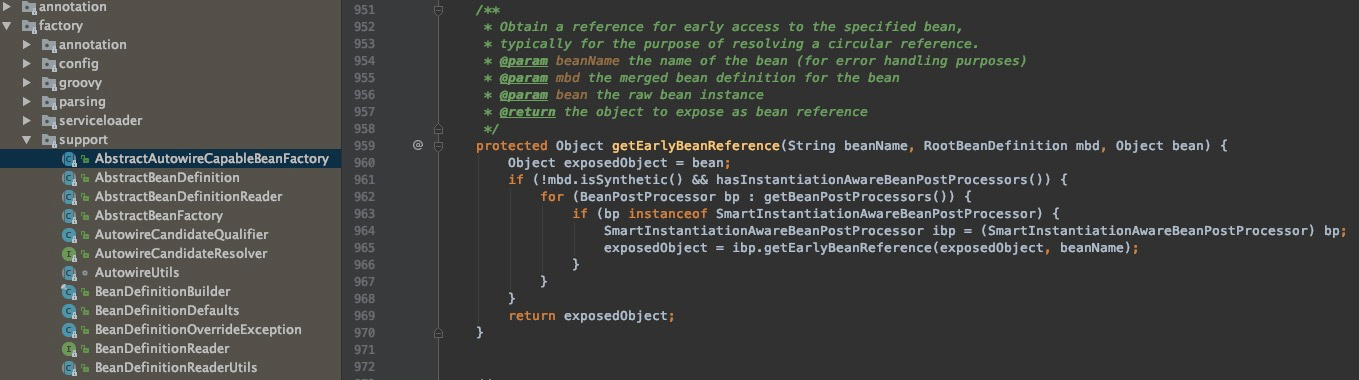
当需要提前暴露的时候,检查该Bean是否需要进行AOP后置处理,返回实例化bean或代理bean。
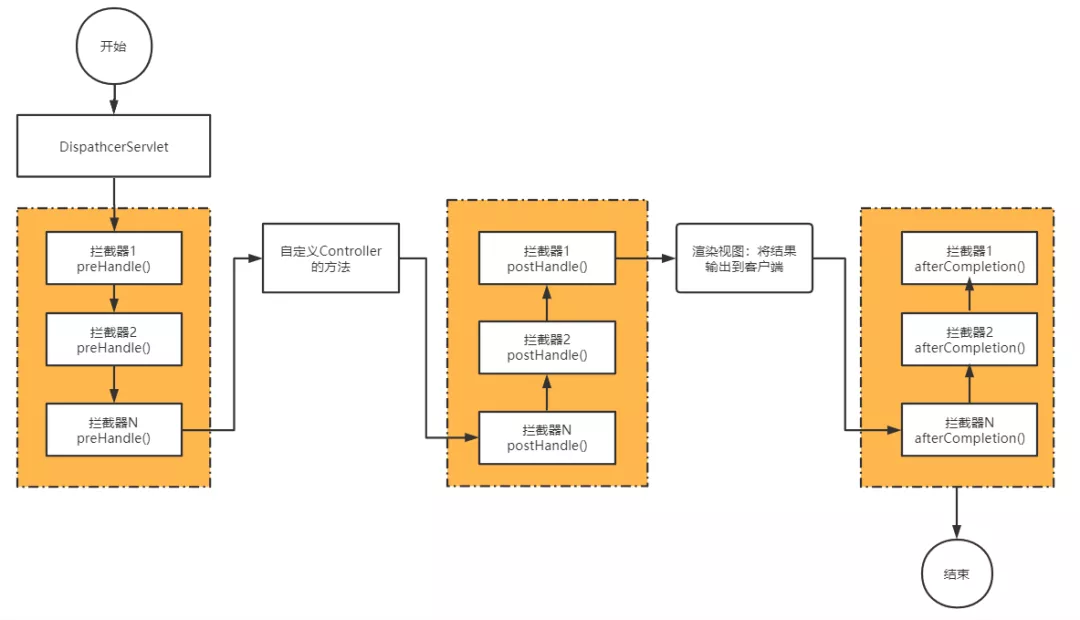
如果方法异常了还能执行拦截器的后置方法吗?【1】
结论:业务方法执行在handler()中,handler()抛出异常,后面的postHandler()都不会执行,但是afterCompletion()无论handler()是否抛出异常都一定会执行。
详情:SpringMVC中使用org.springframework.web.servlet.HandlerInterceptor接口表示拦截器。接口代码如下:
public interface HandlerInterceptor {/*** 调用时机:HandlerMapping确定合适的处理程序对象之后,HandlerAdapter调用处理方法之前**/default boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)throws Exception {return true;}/*** 调用时机:HandlerAdapter调用处理程序之后,DispatcherServlet呈现视图(渲染视图)之前**/default void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,@Nullable ModelAndView modelAndView) throws Exception {}/*** 调用时机:请求处理完成之后的回调(渲染视图之后),即结果输出到客户端之后。* 适合做一些清理工作,该方法参数包含Exception,说明无论是否抛出异常都会执行。* 不会执行的情况:对应的preHandler没有返回true或者异常,该方法不会执行**/default void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler,@Nullable Exception ex) throws Exception {}}
多个拦截器执行流程如下图,抛出异常情况举例:假如有拦截器1、2、3,preHandle方法中打印pre1、pre2、pre3,postHandle方法中打印post1、post2、post3,afterCompletion方法中打印after1、after2、after3
- 如果全部拦截器都执行执行结束,打印结果应该为:
pre1, pre2, pre3, post3, post2, post1, after3, after2, after1 - 如果拦截器2的
preHandle返回false或者抛出异常,则打印结果为:pre1, pre2, after1 - 如果handler方法抛出异常,则打印结果为:
pre1, pre2, pre3, after3, after2, after1
log4j和logback【2】
slf4j是Java程序提供的日志输出的统一接口,并不是一个具体的实现日志方案。所以需要搭配具体的日志实现方案,比如apache的org.apache.log4j.Logger,jdk的java.util.logging.Logger。
Log4j
由三个重要的组件构成:日志记录器(Logger)、输出端(Appenders)和日志格式化器(Layout)
Logger:控制启用/禁用哪些日志语句,并对日志信息进行级别限制Appenders:指定日志打印到控制台还是文件Layout:控制日志信息显示格式
输出日志的5个级别:Debug、Info、Warn、Error、Fatal(灾难性错误,最高级别)
LogBack
Logback被认为是Log4J的升级,性能相对更好。
由三个重要的模块构成:logback-core、logback-classic、logback-access
logback-core:另外两个模块的基础,提供了关键的通用功能logback-classic:作用等同于Log4J,是Log4J的改良版本logback-access:与Servlet容器交互的模块,提供一些与Http访问相关的功能
有三个重要组件构成:日志记录器(Logger)、输出端(Appenders)和日志格式化器(Layout),和Log4J相同
参考
【1】拦截器太强大了,吃透它(SpringMVC系列):https://mp.weixin.qq.com/s?src=11×tamp=1633923834&ver=3367&signature=9z1zcit7TJ34cRcKm328S97dp44p2TfSV9dRGO9Ths46*P3dipAUiA64AeINhCQIYiYDkPuU3C3mcqd-dQbiJ3Nd00VyKt4WqgzU2WEWSSIEz4uch1wJnpO6lLEpaK5E&new=1
【2】别小看 Log 日志,它难住了我们组的架构师!:https://mp.weixin.qq.com/s?src=11×tamp=1634010098&ver=3369&signature=zy2FaN5yzvbF5b3v6l7uwaR6uVBOrlDGH1VW7RIQaF-BmZXbfBhU1k3Bv3qYw9sYdagy1GrKreA2er7TDZixREuhoMwaqcMo7Q1Mx1Bsr7-gXPiBYrbGdPISQ8CDqw&new=1

若有收获,就点个赞吧
0 人点赞
