14 | Lock和Condition(上):隐藏在并发包中的管程
并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。Java SDK 并发包通过 Lock 和 Condition 两个接口来实现管程,其中 Lock 用于解决互斥问题,Condition 用于解决同步问题。
再造管程的理由
破坏死锁的其中一个方案,破坏不可抢占条件,但是synchronized 没有办法解决。原因是synchronized 申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。
如果我们重新设计一把互斥锁去解决这个问题,那该怎么设计呢?我觉得有三种方案。
- 能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
- 支持超时。如果线程在一段时间之内没有获取到锁,不是进入阻塞状态,而是返回一个错误,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
- 非阻塞地获取锁。如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
这三种方案可以全面弥补 synchronized 的问题。到这里相信你应该也能理解了,这三个方案就是“重复造轮子”的主要原因,体现在 API 上,就是 Lock 接口的三个方法。详情如下:
// 支持中断的APIvoid lockInterruptibly() throws InterruptedException;// 支持超时的APIboolean tryLock(long time, TimeUnit unit) throws InterruptedException;// 支持非阻塞获取锁的APIboolean tryLock();
如何保证可见性
class X {private final Lock rtl = new ReentrantLock();int value;public void addOne() {// 获取锁rtl.lock();try {value+=1;} finally {// 保证锁能释放rtl.unlock();}}}
Java SDK 里面 Lock 的使用,有一个经典的范例(如上),就是try{}finally{},可见性是如何保证的? Java 里多线程的可见性是通过 Happens-Before 规则保证的,而 synchronized 之所以能够保证可见性,也是因为有一条 synchronized 相关的规则:synchronized 的解锁 Happens-Before 于后续对这个锁的加锁。那 Java SDK 里面 Lock 靠什么保证可见性呢?
- 顺序性规则:对于线程 T1,value+=1 Happens-Before 释放锁的操作 unlock();
- volatile 变量规则:由于 state = 1 会先读取 state,所以线程 T1 的 unlock() 操作 Happens-Before 线程 T2 的 lock() 操作;
- 传递性规则:线程 T1 的 value+=1 Happens-Before 线程 T2 的 lock() 操作。 ```shell
class SampleLock { volatile int state; // 加锁 lock() { // 省略代码无数 state = 1; } // 解锁 unlock() { // 省略代码无数 state = 0; } }
> **可重入锁**,顾名思义,指的是线程可以重复获取同一把锁。> **可重入函数**,指的是多个线程可以同时调用该函数(说明线程安全)。<br /><a name="z9WER"></a>## 课后思考```shellclass Account {private int balance;private final Lock lock = new ReentrantLock();// 转账void transfer(Account tar, int amt){while (true) {if(this.lock.tryLock()) {try {if (tar.lock.tryLock()) {try {this.balance -= amt;tar.balance += amt;} finally {tar.lock.unlock();}}//if} finally {this.lock.unlock();}}//if}//while}//transfer}
出现活锁问题了,两个线程同时执行,线程A获取了u1.trylock,线程B获取了u2.trylock,线程A尝试获取u2.trylock,不能成功,线程A结束,同时线程B尝试获取u1.trylock,不能成功,线程B结束,又开始新的一轮,这样一直循环下去!
15 | Lock和Condition(下):Dubbo如何用管程实现异步转同步?
Java 语言内置的管程里只有一个条件变量,而 Lock&Condition 实现的管程是支持多个条件变量的,这是二者的一个重要区别。
利用两个条件变量快速实现阻塞队列例子:
public class BlockedQueue<T>{final Lock lock = new ReentrantLock();// 条件变量:队列不满final Condition notFull = lock.newCondition();// 条件变量:队列不空final Condition notEmpty = lock.newCondition();// 入队void enq(T x) {lock.lock();try {while (队列已满){// 等待队列不满notFull.await(); // 是会释放lock锁的}// 省略入队操作...//入队后,通知可出队notEmpty.signal();} finally {lock.unlock();}}// 出队void deq(){lock.lock();try {while (队列已空){// 等待队列不空notEmpty.await();}// 省略出队操作...//出队后,通知可入队notFull.signal();} finally {lock.unlock();}}}
Dubbo 源码分析
TCP 协议本身就是异步的,我们工作中经常用到的 RPC 调用,在 TCP 协议层面,发送完 RPC 请求后,线程是不会等待 RPC 的响应结果的。可能你会觉得奇怪,平时工作中的 RPC 调用大多数都是同步的啊?这是怎么回事呢?
RPC异步转同步:当 RPC 返回结果之前,阻塞调用线程,让调用线程等待;当 RPC 返回结果后,唤醒调用线程,让调用线程重新执行。
// 创建锁与条件变量private final Lock lock = new ReentrantLock();private final Condition done = lock.newCondition();// 调用方通过该方法等待结果Object get(int timeout) {long start = System.nanoTime();lock.lock();try {while (!isDone()) {done.await(timeout);long cur = System.nanoTime();if (isDone() || cur-start > timeout) {break;}}} finally {lock.unlock();}if (!isDone()) {throw new TimeoutException();}return returnFromResponse();}// RPC结果是否已经返回boolean isDone() {return response != null;}// RPC结果返回时调用该方法private void doReceived(Response res) {lock.lock();try {response = res;if (done != null) {done.signal();}} finally {lock.unlock();}}
16 | Semaphore:如何快速实现一个限流器?
信号量模型
信号量模型还是很简单的,可以简单概括为:一个计数器,一个等待队列,三个方法。在信号量模型里,计数器和等待队列对外是透明的,所以只能通过信号量模型提供的三个方法来访问它们,这三个方法分别是:init()、down() 和 up()。你可以结合下图来形象化地理解。
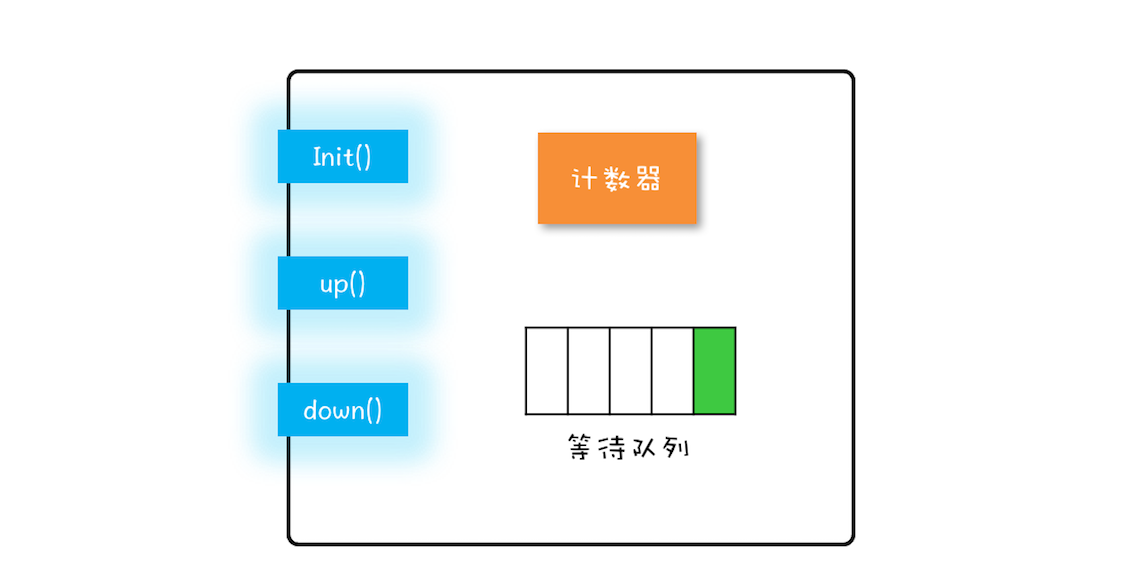
这三个方法详细的语义具体如下所示。
- init():设置计数器的初始值。
- down():计数器的值减 1;如果此时计数器的值小于 0,则当前线程将被阻塞,否则当前线程可以继续执行。
- up():计数器的值加 1;如果此时计数器的值小于或者等于 0,则唤醒等待队列中的一个线程,并将其从等待队列中移除。
信号量模型里面,down()、up() 这两个操作历史上最早称为 P 操作和 V 操作,所以信号量模型也被称为 PV 原语。另外,还有些人喜欢用 semWait() 和 semSignal() 来称呼它们,虽然叫法不同,但是语义都是相同的。在 Java SDK 并发包里,down() 和 up() 对应的则是 acquire() 和 release()。
如何使用信号量
static int count;//初始化信号量static final Semaphore s = new Semaphore(1);//用信号量保证互斥static void addOne() {s.acquire();try {count+=1;} finally {s.release();}}
快速实现一个限流器
既然有 Java SDK 里面提供了 Lock,为啥还要提供一个 Semaphore ?其实实现一个互斥锁,仅仅是 Semaphore 的部分功能,Semaphore 还有一个功能是 Lock 不容易实现的,那就是:Semaphore 可以允许多个线程访问一个临界区。
对象池的示例代码
class ObjPool<T, R> {final List<T> pool;// 用信号量实现限流器final Semaphore sem;// 构造函数ObjPool(int size, T t){pool = new Vector<T>(){};for(int i=0; i<size; i++){pool.add(t);}sem = new Semaphore(size);}// 利用对象池的对象,调用funcR exec(Function<T,R> func) {T t = null;sem.acquire();try {t = pool.remove(0);return func.apply(t);} finally {pool.add(t);sem.release();}}}// 创建对象池ObjPool<Long, String> pool = new ObjPool<Long, String>(10, 2);// 通过对象池获取t,之后执行pool.exec(t -> {System.out.println(t);return t.toString();});
信号量和管程
信号量在 Java 语言里面名气并不算大,但是在其他语言里却是很有知名度的。Java 在并发编程领域走的很快,重点支持的还是管程模型。 管程模型理论上解决了信号量模型的一些不足,主要体现在易用性和工程化方面,例如用信号量解决我们曾经提到过的阻塞队列问题,就比管程模型麻烦很多
17 | ReadWriteLock:如何快速实现一个完备的缓存?
我们介绍了管程和信号量这两个同步原语在 Java 语言中的实现,理论上用这两个同步原语中任何一个都可以解决所有的并发问题。Java SDK 并发包里为什么还有很多其他的工具类呢?原因很简单:分场景优化性能,提升易用性。
针对读多写少这种并发场景,Java SDK 并发包提供了读写锁——ReadWriteLock,非常容易使用,并且性能很好。
Cache 这个工具类
class Cache<K,V> {final Map<K, V> m = new HashMap<>();final ReadWriteLock rwl = new ReentrantReadWriteLock();// 读锁final Lock r = rwl.readLock();// 写锁final Lock w = rwl.writeLock();// 读缓存V get(K key) {r.lock();try {return m.get(key);}finally {r.unlock();}}// 写缓存V put(K key, V value) {w.lock();try {return m.put(key, v);}finally {w.unlock();}}}
18 | StampedLock:有没有比读写锁更快的锁?
ReadWriteLock 支持两种模式:一种是读锁,一种是写锁。而 StampedLock 支持三种模式,分别是:写锁、悲观读锁和乐观读。其中,写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个 stamp;然后解锁的时候,需要传入这个 stamp。相关的示例代码如下。
final StampedLock sl = new StampedLock();// 获取/释放悲观读锁示意代码long stamp = sl.readLock();try {//省略业务相关代码} finally {sl.unlockRead(stamp);}// 获取/释放写锁示意代码long stamp = sl.writeLock();try {//省略业务相关代码} finally {sl.unlockWrite(stamp);}
StampedLock 的性能之所以比 ReadWriteLock 还要好,其关键是 StampedLock 支持乐观读的方式。 ReadWriteLock 支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;而 StampedLock 提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
但是 StampedLock 的功能仅仅是 ReadWriteLock 的子集,在使用的时候,还是有几个地方需要注意一下。StampedLock 在命名上并没有增加 Reentrant,想必你已经猜测到 StampedLock 应该是不可重入的。事实上,的确是这样的,StampedLock 不支持重入。这个是在使用中必须要特别注意的。另外,StampedLock 的悲观读锁、写锁都不支持条件变量,这个也需要你注意。
StampedLock 读模板:
final StampedLock sl = new StampedLock();// 乐观读long stamp = sl.tryOptimisticRead();// 读入方法局部变量......// 校验stampif (!sl.validate(stamp)){// 升级为悲观读锁stamp = sl.readLock();try {// 读入方法局部变量.....} finally {//释放悲观读锁sl.unlockRead(stamp);}}//使用方法局部变量执行业务操作......
StampedLock 写模板:
long stamp = sl.writeLock();try {// 写共享变量......} finally {sl.unlockWrite(stamp);}
19 | CountDownLatch和CyclicBarrier:如何让多线程步调一致?
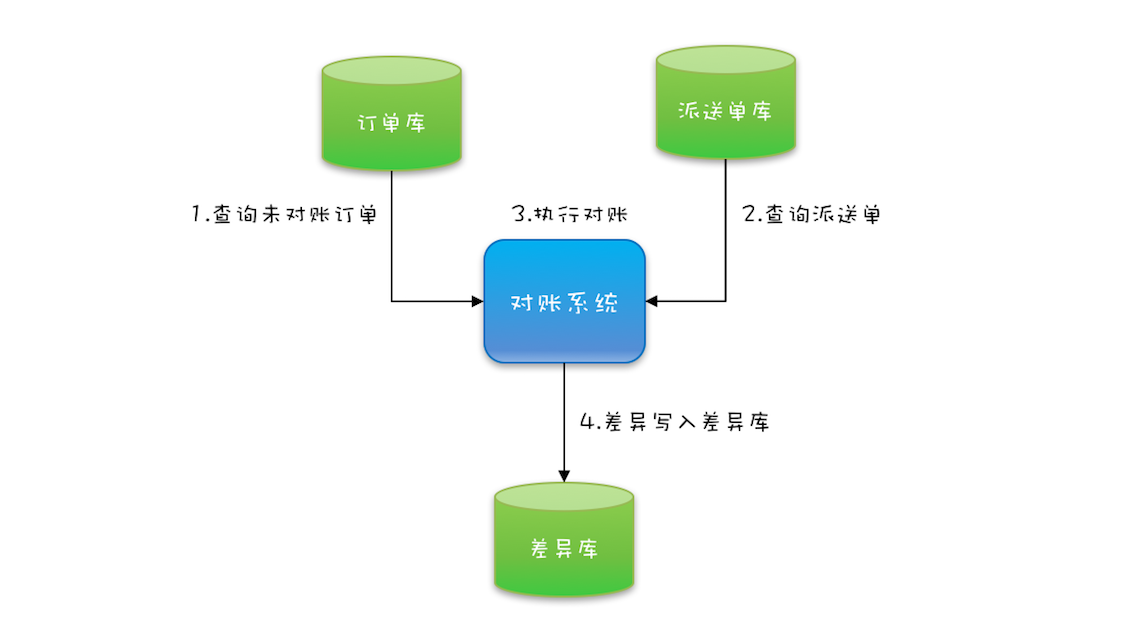 需求如图
需求如图
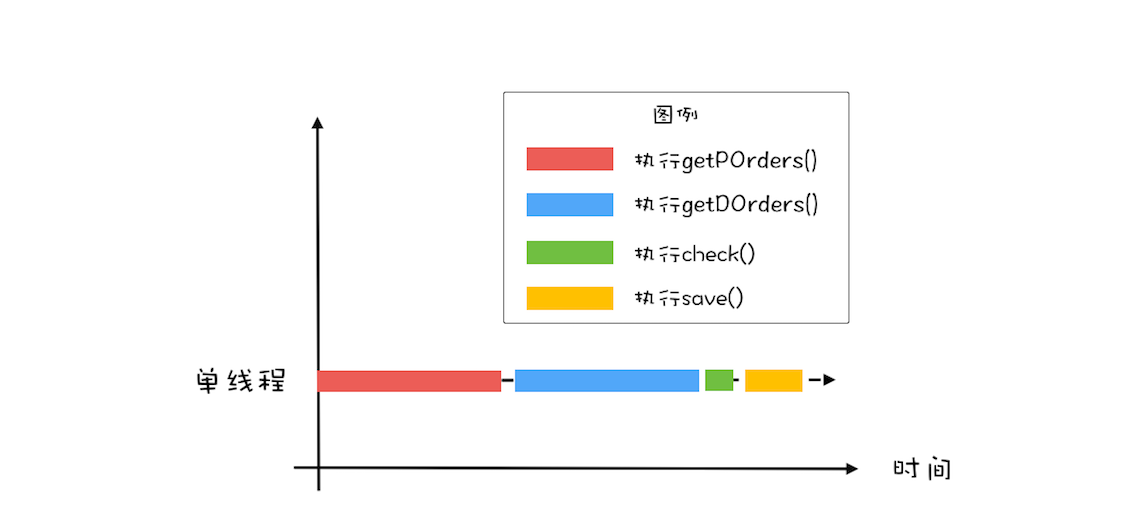
- 代码块同步执行,效率过低
- 将1和2开子线程,异步执行
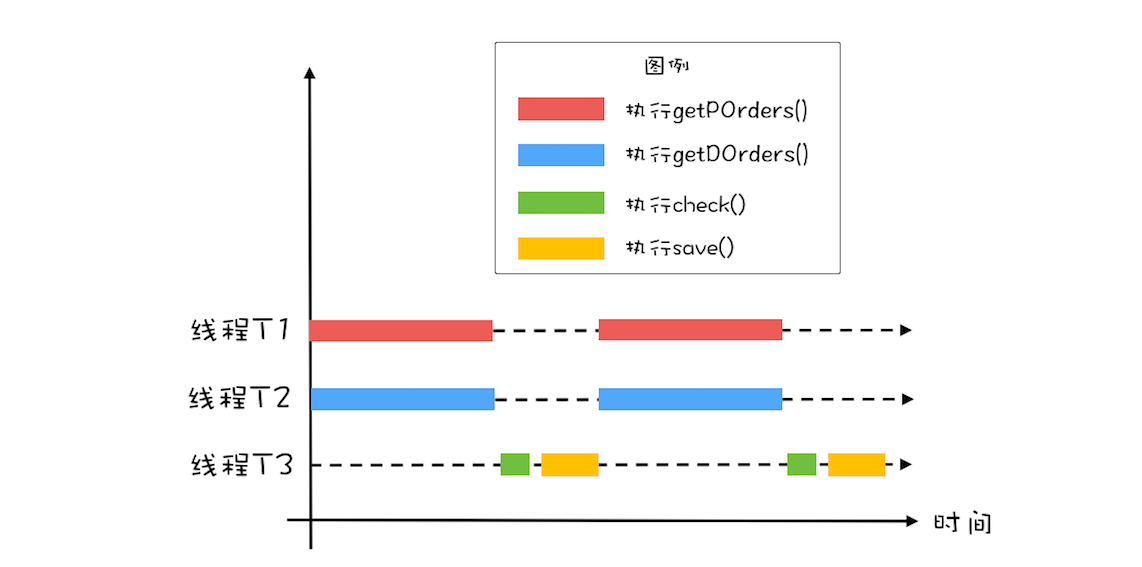
while(存在未对账订单){// 查询未对账订单Thread T1 = new Thread(()->{pos = getPOrders();});T1.start();// 查询派送单Thread T2 = new Thread(()->{dos = getDOrders();});T2.start();// 等待T1、T2结束T1.join();T2.join();// 执行对账操作diff = check(pos, dos);// 差异写入差异库save(diff);}
- 用 CountDownLatch 实现线程等待。2方案中while 循环里面每次都会创建新的线程,而创建线程可是个耗时的操作。所以最好是创建出来的线程能够循环利用。但是线程池就无法使用Thread.join来实现了,因为线程不会销毁。 ```java
// 创建2个线程的线程池 Executor executor = Executors.newFixedThreadPool(2); while(存在未对账订单){ // 计数器初始化为2 CountDownLatch latch = new CountDownLatch(2); // 查询未对账订单 executor.execute(()-> { pos = getPOrders(); latch.countDown(); }); // 查询派送单 executor.execute(()-> { dos = getDOrders(); latch.countDown(); });
// 等待两个查询操作结束 latch.await();
// 执行对账操作 diff = check(pos, dos); // 差异写入差异库 save(diff); }
4. 进一步优化:在执行对账操作的时候,可以同时去执行下一轮的查询操作。用 CyclicBarrier 实现线程同步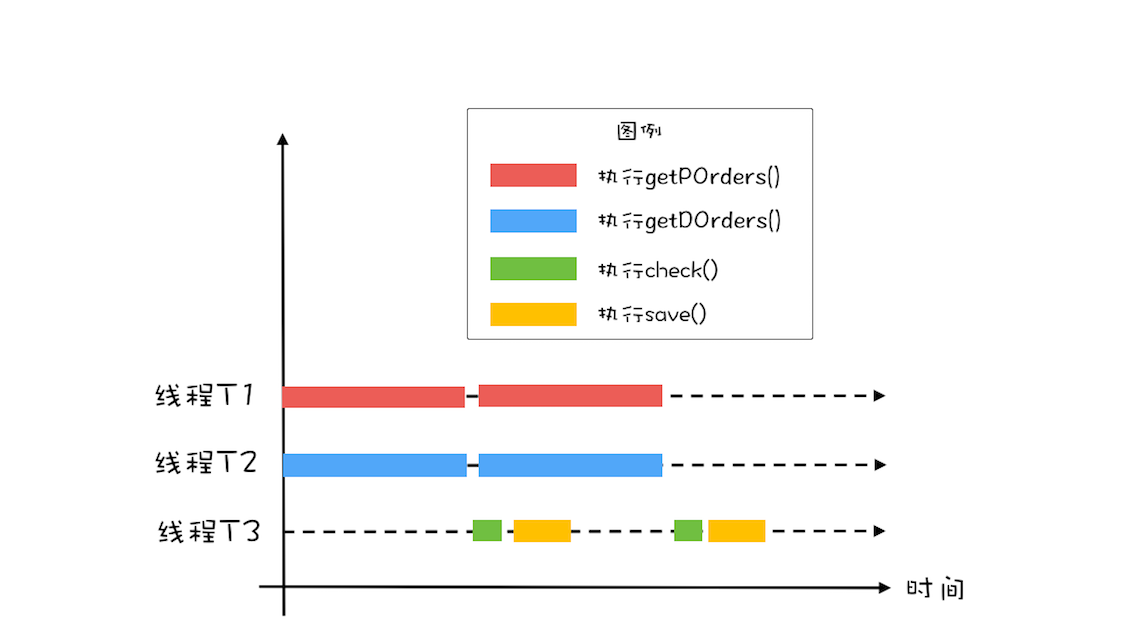```java// 订单队列Vector<P> pos;// 派送单队列Vector<D> dos;// 执行回调的线程池Executor executor = Executors.newFixedThreadPool(1);final CyclicBarrier barrier =new CyclicBarrier(2, ()->{executor.execute(()->check());});void check(){P p = pos.remove(0);D d = dos.remove(0);// 执行对账操作diff = check(p, d);// 差异写入差异库save(diff);}void checkAll(){// 循环查询订单库Thread T1 = new Thread(()->{while(存在未对账订单){// 查询订单库pos.add(getPOrders());// 等待barrier.await();}});T1.start();// 循环查询运单库Thread T2 = new Thread(()->{while(存在未对账订单){// 查询运单库dos.add(getDOrders());// 等待barrier.await();}});T2.start();}
20 | 并发容器:都有哪些“坑”需要我们填?
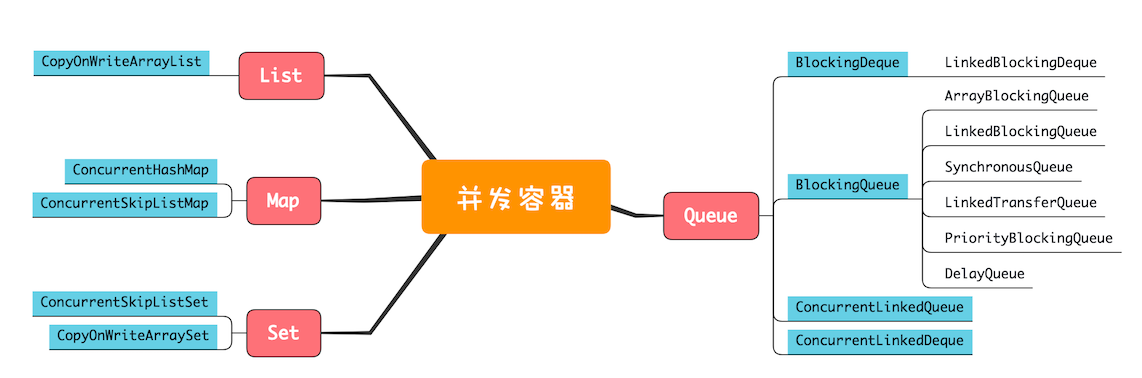
List
List 里面只有一个实现类就是 CopyOnWriteArrayList。
如果在遍历 array 的同时,还有一个写操作,例如增加元素,CopyOnWriteArrayList 是如何处理的呢?CopyOnWriteArrayList 会将 array 复制一份,然后在新复制处理的数组上执行增加元素的操作,执行完之后再将 array 指向这个新的数组。
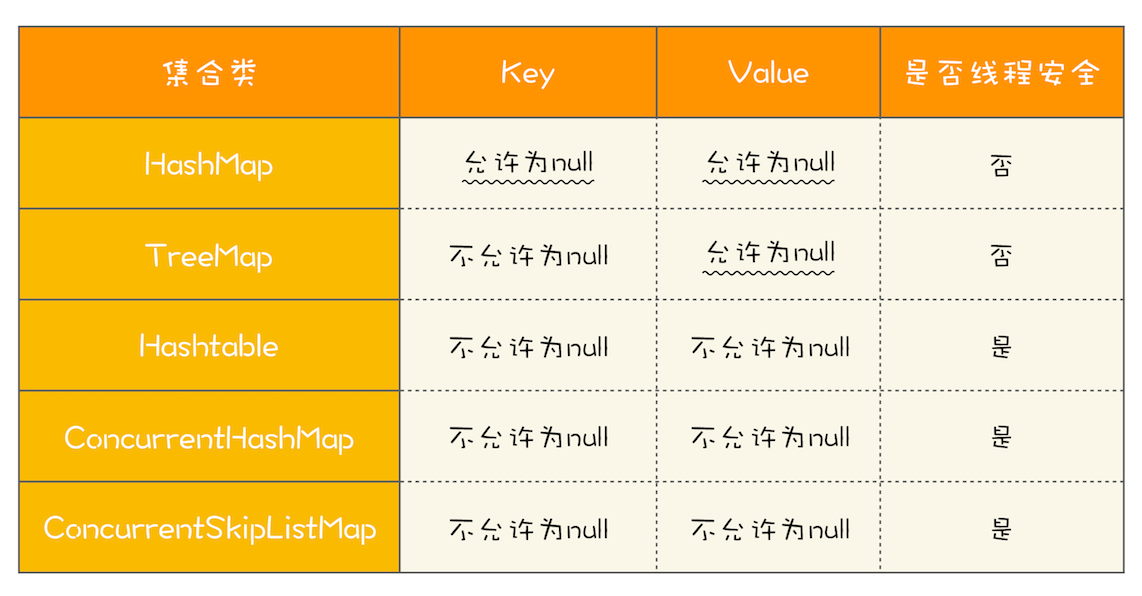
Map
Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap,它们的原理都是一样的
Queue
Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识。
单端阻塞队列
其实现有 ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue。
双端阻塞队列
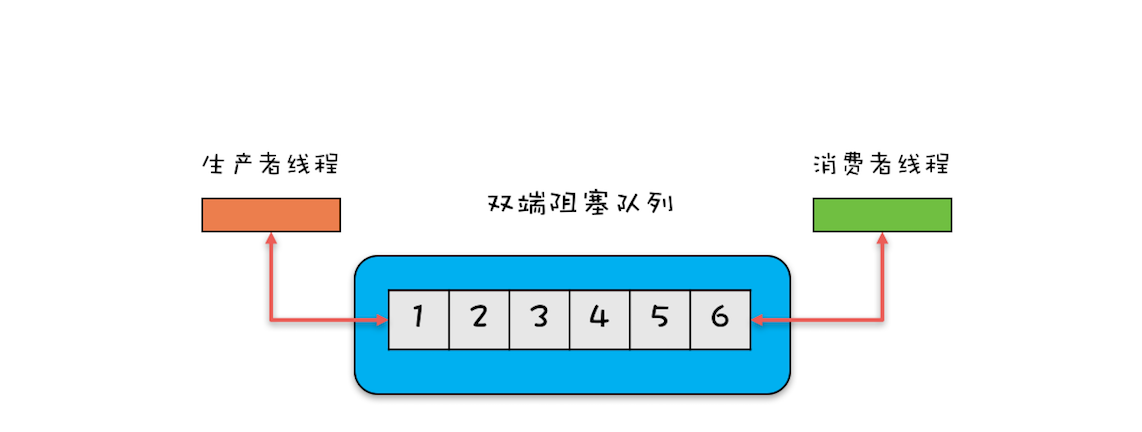
单端非阻塞队列
双端非阻塞队列
其实现是 ConcurrentLinkedDeque。
Java 容器的快速失败机制
课后思考
在 1.8 之前并发执行 HashMap.put() 可能会导致 CPU 飙升到 100%原因
https://my.oschina.net/alexqdjay/blog/1377268?utm_medium=referral
https://blog.csdn.net/qq_35688140/article/details/100772864
21 | 原子类:无锁工具类的典范
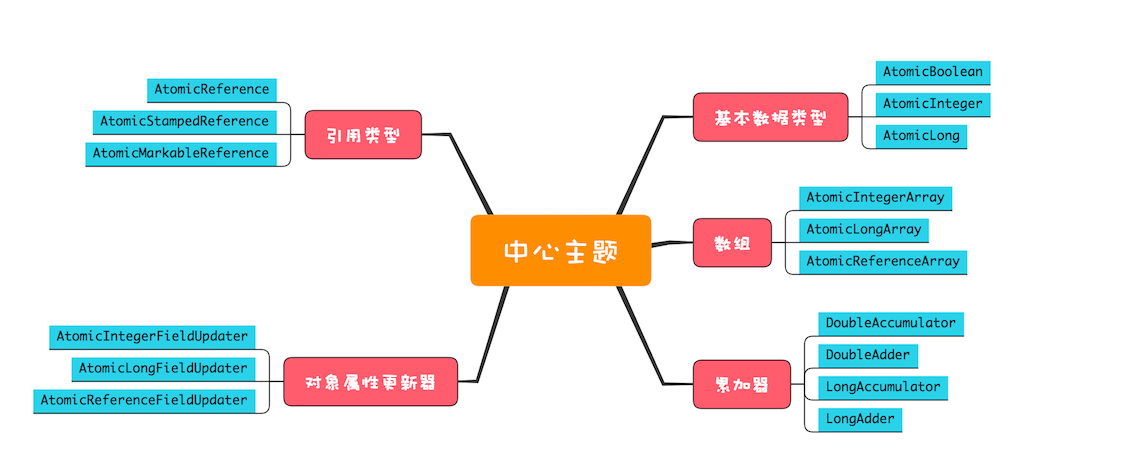
原子类
原子化的基本数据类型
getAndIncrement() //原子化i++getAndDecrement() //原子化的i--incrementAndGet() //原子化的++idecrementAndGet() //原子化的--i//当前值+=delta,返回+=前的值getAndAdd(delta)//当前值+=delta,返回+=后的值addAndGet(delta)//CAS操作,返回是否成功compareAndSet(expect, update)//以下四个方法//新值可以通过传入func函数来计算getAndUpdate(func)updateAndGet(func)getAndAccumulate(x,func)accumulateAndGet(x,func)
原子化的对象引用类型
无锁方案的实现原理
其实原子类性能高的秘密很简单,硬件支持而已。CPU 为了解决并发问题,提供了 CAS 指令(CAS,全称是 Compare And Swap,即“比较并交换”)。CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B 时,才能将内存中地址 A 处的值更新为新值 C。作为一条 CPU 指令,CAS 指令本身是能够保证原子性的。
使用 CAS 来解决并发问题,一般都会伴随着自旋,而所谓自旋,其实就是循环尝试。例如,实现一个线程安全的count += 1操作,“CAS+ 自旋”的实现方案如下所示(范式do while):
class SimulatedCAS{volatile int count;// 实现count+=1addOne() {do {newValue = count+1; //①} while(count != cas(count,newValue) //②}}
引申问题
ABA 的问题。解决 ABA 问题的思路其实很简单,增加一个版本号维度就可以了(版本号递增的)。

若有收获,就点个赞吧
0 人点赞
