title: OPPO小布深度语义问答FQA技术实践
subtitle: OPPO小布深度语义问答FQA技术实践
date: 2021-10-31
author: NSX
catalog: true
tags:
- OPPO小布
- 智能问答系统
经过 2 年多的成长,小布助手在能力上实现大幅升级,也融入了我们身边便捷的服务功能。小布团队亦克服了诸多技术难点,为用户带来了更智能的服务。为此,小布团队撰写了一系列文章,详细介绍小布助手背后的技术支撑,本文是揭秘小布背后技术的第三篇。
第一篇:对话系统简介与OPPO小布助手的工程实践
第二篇:小布助手算法系统的探索、实践与思考
前言
在智能客服、语义问答的业务中,更注重的是query与query之间的匹配,即短文本之间的相似度计算。长文本匹配更多注重文本的关键词或者主题的匹配,业界使用的较多的算法如:TF-IDF、LSA、LDA;而短文本匹配更多的是句子整体的语义一致性,业界较为主流的算法有:word2vec、esim、abcnn、bert等深度模型。
相比于长文本的相似度计算,短文本的相似度计算存在更大的挑战。其一,短文本可以利用的上下文信息有限,语义刻画不够全面;其二,短文本通常情况下,口语化程度更高,存在缺省的可能性更大;第三,短文本更注重文本整体语义的匹配,对文本的语序、句式等更为敏感。
| query1 | query2 |
|---|---|
| 我要打给你 | 我要打你 |
| 你叫什么 | 你叫我什么 |
| 我叫小布 | 我不叫小布 |
| 你有男票吗 | 你是单身狗吗 |
| 你真搞笑 | 你是个逗比啊 |
| 我喜欢看动漫 | 你不知道我喜欢看动漫吗 |
业界常用的短文本相似度计算方案大致可以分为两类:监督学习与无监督学习,通常情况下,监督学习效果相对较好。在没有足够的训练数据需要冷启动的情况下,可优先考虑使用无监督学习来进行上线。
无监督学习
最简单有效的无监督学习方案就是预训练的方式,使用word2vec或者bert等预训练模型,对任务领域内的无标签数据进行预训练。使用得到的预训练模型,获取每个词以及句子的语义表示,用于相似度的计算。
Word2vec是nlp领域一个划时代的产物,将word的表征从离散的one-hot的方式转化成连续的embedding的形式,不仅降低了计算维度,各个任务上的效果也取得了质的飞跃。Word2vec通过对大规模语料来进行语言模型(language model)的建模,使得语义相近的word,在embedding的表示上,也具有很强的相关性。
通过cbow或者max-pooling的方式,使用句子中每个词的word embedding计算得到sentence embedding,可以使得语义相似的句子在sentence embedding的表示上也具备较高的相关性,相比于传统的TF-IDF等相似度计算具有更好的泛化性。但是cbow的方式来计算sentence embedding,句子中所有word使用相同的权重,无法准确获取句子中的keyword,导致语义计算的准确率有限,难以达到上线标准。
虽然Word2vec提供了一定的泛化性,但其最大的弱点是在不同的语境下,同一个word的表征完全相同,无法满足丰富的语言变化。gpt、bert等大规模预训练模型的出现,彻底解决了这个问题,做到了word的表征与上下文相关,同时也不断刷新了各个领域任务的榜单。
但实验证明直接使用bert输出的token embedding来计算句子的sentence embedding,无论使用cbow的方式对所有token embedding求平均或者直接使用[CLS] token的embedding来表示,语义计算的效果都不佳,甚至不如GloVe。究其原因,在bert的预训练过程中,高频词之间共现概率更大,MLM任务训练使得它们之间语义表征更加接近,而低频词之间的分布更为稀疏。语义空间分布的不均匀,导致低频词周围中存在很多语义的“hole”,由于这些“hole”的存在,导致语义计算的相似度存在偏差。
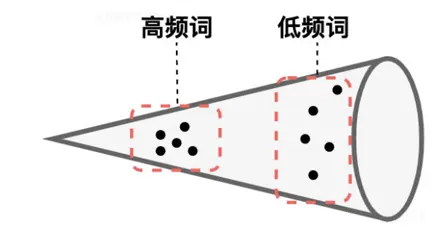
为了解决bert语义空间不均匀的问题,CMU与字节跳动合作的bert-flow提出将bert的语义空间映射到一个标准的高斯隐空间,由于标准高斯分布满足各向同性,区域内不存在“hole”,不会破坏语义空间的连续性。
监督学习
Bert-flow的出现使得无监督学习在文本相似度计算方面取得了较大进步,但是在特定任务上相比于监督学习,效果还存在一定的差距。监督学习常用的相似度计算模型大致可以分为两类:语义表征模型,语义交互式模型。语义表征模型常用于海量query召回,交互式模型更多使用于语义排序阶段。
深度语义问答FQA技术实践
语义匹配问答架构主要分为拒绝策略层、Query预处理、智能改写包括代词指代消解、同义词改写以及后续规划的语义递进或转折场景下的完整性改写、语义检索、语义排序、语义消歧等可配置模块,可配置的策略模块用于快速解决线上高优BADCASE问题,同时小布助手在百度语义匹配赛道冲击过第一名。
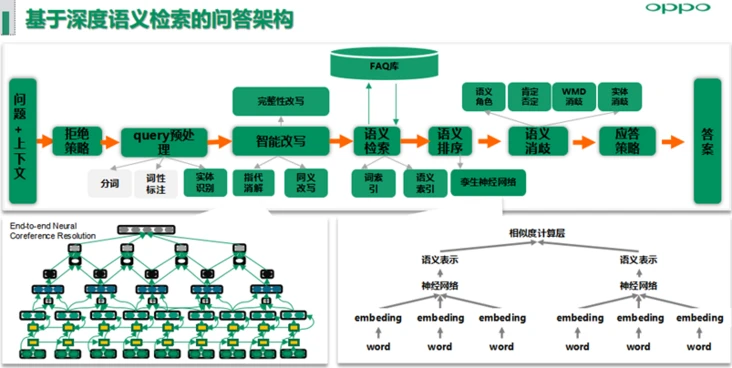
语义召回模型——采用SiameseNetwork框架,使用分类任务建模思路进行训练,且训练样本数据范式采用listwise范式,模型目标是最大化正样本之间的相关性,同时抑制负样本之间的相关性。
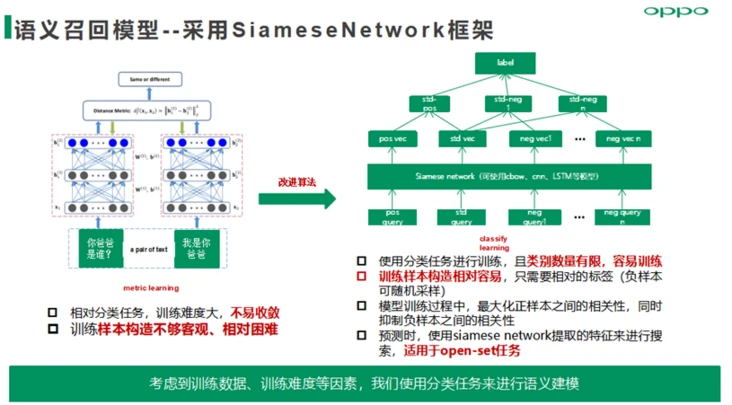
相似度上,核心就在于离线需要训练一个足够靠谱的语义相似度模型,这块非常机智的参考了人脸识别的一些思路。我们希望语义相似的句子能分布在一个比较集中的空间内,而语义不同的则能差的足够远,按照人脸识别领域的经验,通过损失函数引导模型往这方面学,则有很大的收益了。如果只是平行样本(q1,q2,label),那训练起来信息不够,参考DSSM的思路(说实话,DSSM给这块真的提供了和很多思路,不能仅要关注模型本身),可以1个anchor,若干正负样本(对比anchor)来构成一串输入样本,来进行计算,更有好处,即有了对比,A和B是相似,和C是不相似,那我们可以很有把握地定位好A的位置,从而训练好模型
语义匹配模型实践方面,对于负样本采样策略优先使用标注的负样本,标注负样本不足情况下,通过卡字面相关性阈值策略进行负采样,以保证负样本有一定相关性,尽量构建semi-hard数据集用来加速模型收敛,同时提升模型语义表征精度;损失函数方面我们主要尝试hinge loss、Triplet Loss、AMSoftMax等。
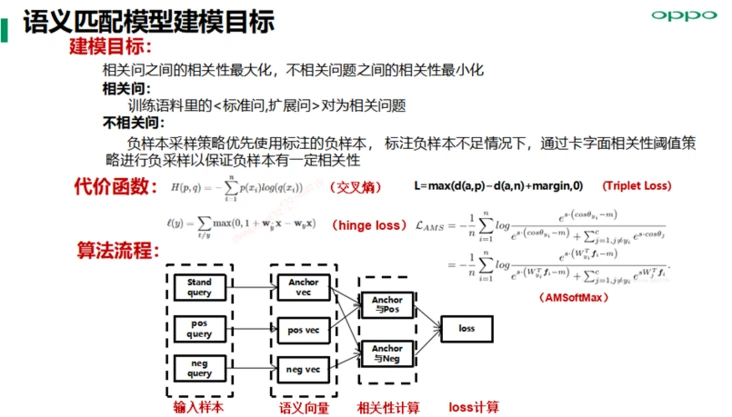
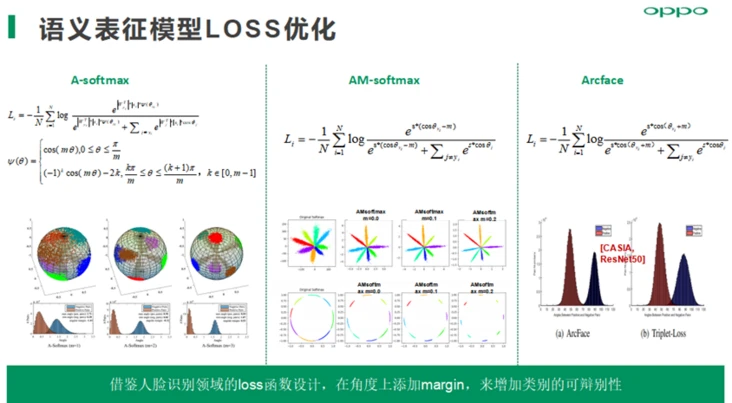
AM-softmax在余弦相似度上添加一个margin,可以提高类间可分及类别的可辨别性, 使用cnn网络,结合AM-softmax的loss函数,能够取得最好的语义表征能力,通用评测集下的准确率提升1%,同时召回提升明显。
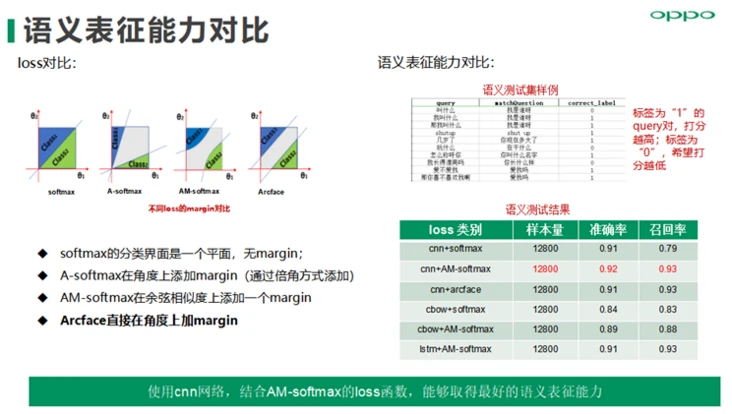
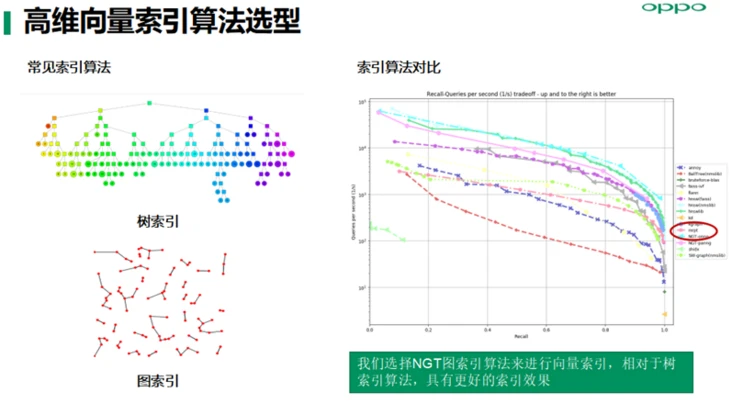
高纬数据索引算法主要有树索引和图索引两种,通过基于同等召回率的召回性能试验对比,我们选择NGT图索引算法来进行向量索引,相对于树索引算法,具有更好的索引效果及索引性能。
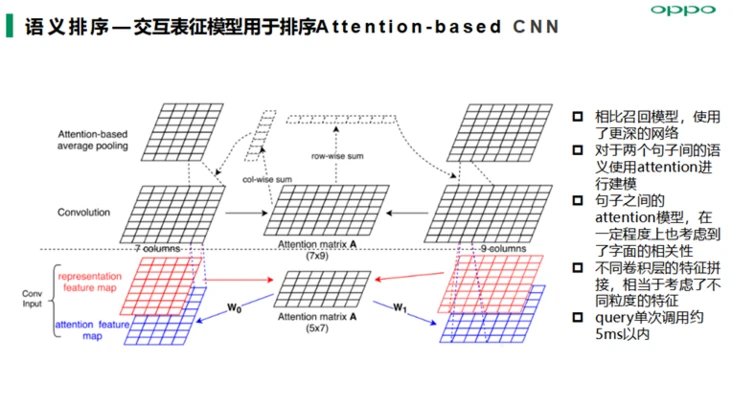
语义排序算法模型主要落地实践了交互表征模型ABCNN、ESIM以及Transformer模型等,在召回阶段我们得到的候选query集合,然后基于用户当前query与候选query进行交互式表征建模能提高语义表征精度从而提高语义匹配准确率;另外ESIM模型优点在于精细设计的序列式推断结构,考虑局部推断和全局推断的融合,准召效果相对也会高一些 。
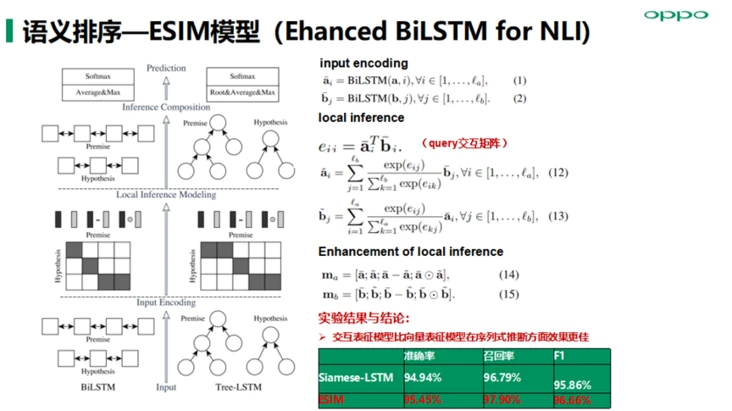
做个总结,OPPO小布的检索式FAQ方案就是:使用siamese cnn语义表征模型来进行语义召回,用蒸馏后的transformer语义交互模型来做排序(自研的XBert)。
在语义表征模型的loss构建上,使用了1个标准query,1个正样本,5个负样本(尝试过其他负样本数量,在我们的数据上效果不如5个负样本),训练过程其实是在这6个样本中,识别出对应正样本的位置,因此可将其转化为二分类任务来进行训练,每个正负样本分别对应一个类别。传统的softmax归一化构建的分类边界使得类别之间可分,为了更好的语义表征效果,需要使得类内更加汇聚,类间更加分散。这里参考了人脸识别领域的损失函数AM-Softmax。
在排序模型方面,尝试了ABCNN、ESIM、transformer等交互式语义模型,但效果相比于bert等预训练模型,还存在一定的差距。自研的预训练模型Xbert,在与Roberta large同规模的情况下,融入了自研知识图谱数据,添加了WWM(whole word MLM)、DAE、Entity MLM等任务,使用LAMB优化器进行优化。我们使用XBert在业务数据上进行了测试,相比于同规模的Roberta large准确率有接近0.9%的提升。为了满足上线需求,我们参考tiny bert的方式,用Xbert蒸馏了一个4层的transformer model用于线上推断。
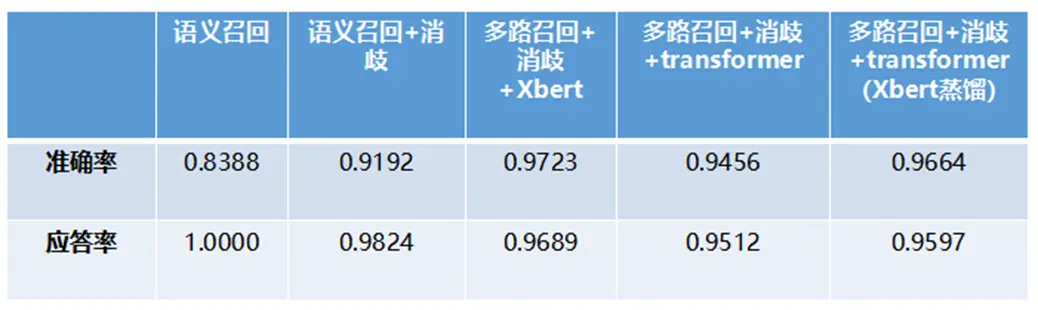
如何对不同排序方案做效果对比?
用语义召回top1的准确率来评估语义表征模型的效果,并且通过消歧模块进一步提升应答准确率;测试排序模型效果时,我们使用了多路召回,共召回30个候选,使用排序模型对候选排序,选择排序后的top1作为最终答案。
算法服务工程
算法服务架构主要基于领域分治、NLU服务多进程并发高性能的原则进行设计。关键点:
- 业务微服务化,业务域按垂域拆分,降低耦合性、提升算法服务性能,提高敏捷迭代效率;
- 模型tfservering服务化,TF Serving集群管理TF模型易部署,天然支持模型热更新机制,复杂模型可利用GPU进行inference,同时通过本地模型服务实现服务降级策略。

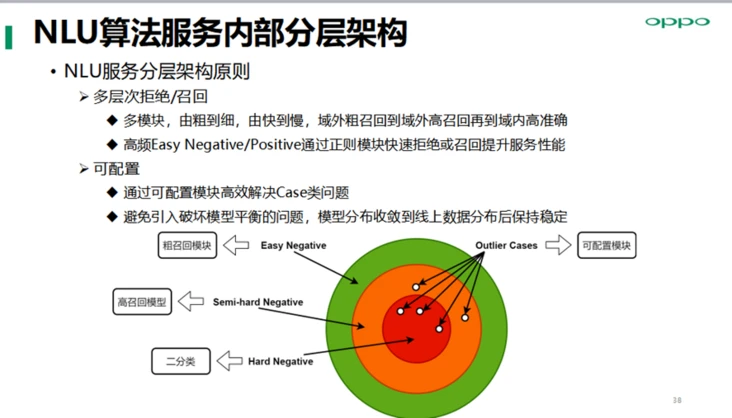
NLU算法服务内部分层架构,多层次拒绝/召回,域外粗召回到域外高召回再到域内高准确, 通过可配置模块高效解决Case类问题,避免引入破坏模型平衡的问题,模型分布收敛到线上数据分布后保持稳定。
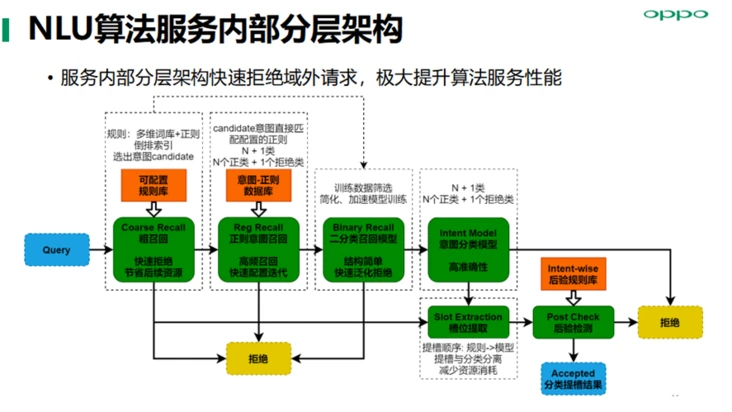
服务内部分层架构快速拒绝域外请求,极大提升算法服务性能,保障小布助手端到端流畅度的性能体验。
总结与展望
封闭域任务型对话技术关键挑战有多个,比如,语义理解模型的鲁棒性,特别是高频技能线上query分布变化快,如何保证线上模型泛化性是关键;对话能力更自然流畅的对话管理技术;上下文意图理解(当前已经具备人称/实体代词、部分零指代的指代消解能力,但泛化能力有限);融合设备渠道、LBS位置信息及客户端状态等场景特征+用户基本属性+用户兴趣画像的综合意图理解。
开放域对话技术方面,检索式聊天技术能解决高频头部query问题,但解决不了长尾问题以及开放域多轮对话问题。融合知识问答、闲聊、对话推荐为一体的端到端多轮生成式,是未来ChatBot的关键技术方向。
这里也存在不少技术挑战,包括包罗万象的知识问答、情绪感知的共情能力、融合系统画像与用户画像的回复生成、逻辑/观点/人设一致性、回合制被动问答向主动式对话演进、全双工的持续对话能力。
参考

若有收获,就点个赞吧
0 人点赞
