方案调研
关注点:
- 这个方案的baseline是什么,最简单和快捷的方式是哪些,都有什么优缺点。
- 大厂常用的方案是什么,有没有什么特别地操作,为什么要做这个操作。
- 论文,科研界的主要方式是什么,需要关注哪些方面。
1、美团人工辅助——话术推荐
智能辅助目的:
- 自动匹配历史对话日志,便于人工座席了解客户背景诉求;
- 自动匹配历史优秀座席回答话术,供其他座席参考;
- 场景话术推荐,分步规范座席对话流程;
面向座席的场景:
座席在与用户的对话聊天中经常回复相似甚至相同的话术,提供话术推荐的能力可以提升人工座席的工作效率,改善人工座席的工作体验。
那么,话术推荐具体要怎么做呢?常见的做法是先准备好常用通用话术库(直接从对话日志里面挖回复),部分座席或商家也会准备个人常见话术库,然后系统根据用户的Query及上下文来检索最合适的话术,预测接下来可能的回复话术
美团的做法是:将历史聊天记录构建成“N+1”QA问答对的形式建模,前N句看作问题Q,后1句作为回复话术A,整个框架就可以转化成检索式的问答模型。在召回阶段,除了文本信息召回外,还加入了上文多轮槽位标签,Topic标签等召回优化(我理解是 ES 建向量索引,top 相似度召回);排序为基于BERT的模型,将“N+1”QA问答对拼接,并加入角色信息建模(角色为用户、商家或者座席)作为输入,利用 0/1 二分类做训练,利用xx相似度匹配做推理….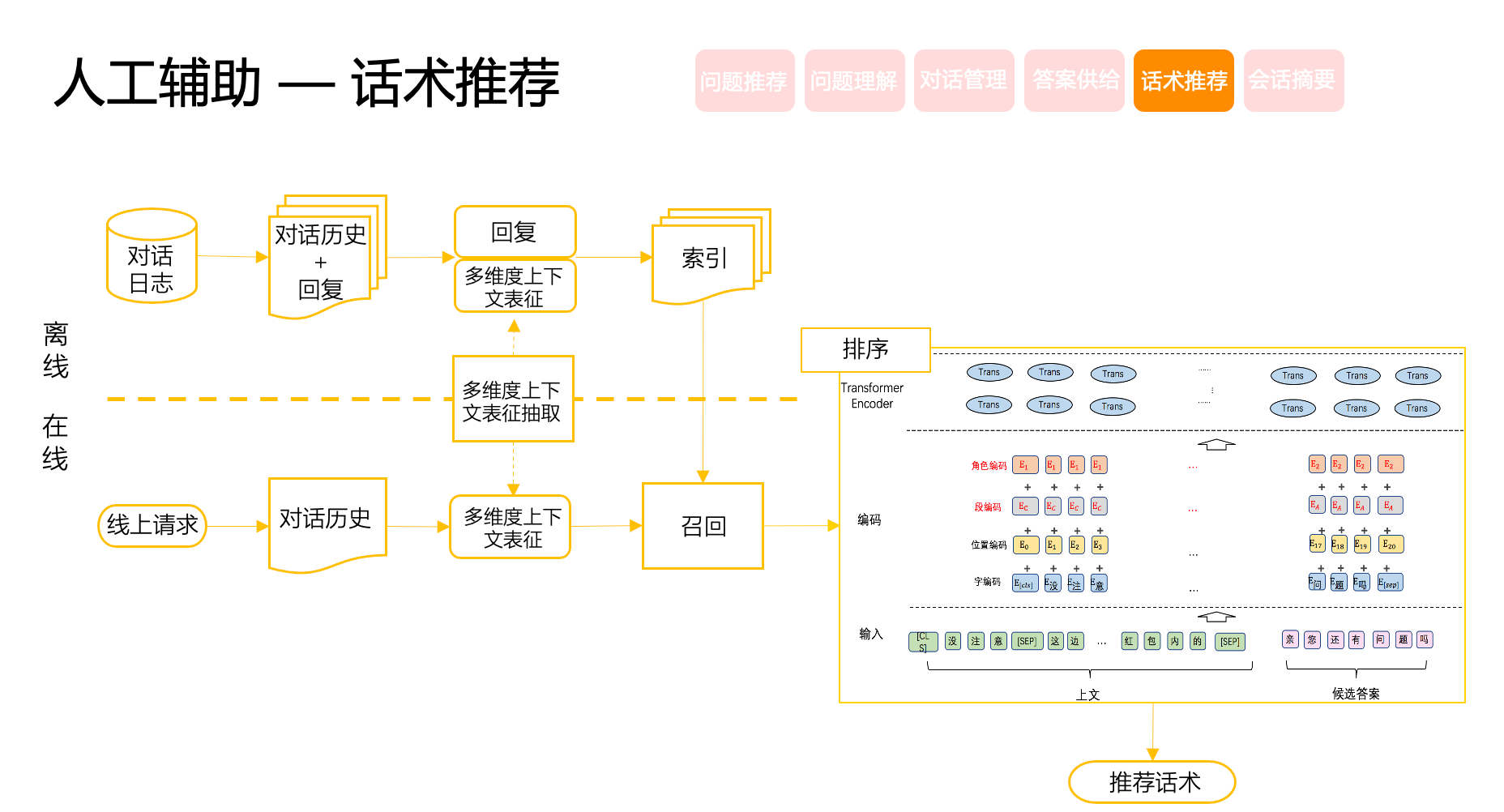
2、基于LM的生成式多轮对话模型
- 数据集:大规模的中文闲聊语料库LCCC,包含了部分多轮对话聊天…所有样本都被处理成双人对话。
- 考虑训练一个模型,预测下一个该回复什么。同时还要求这个模型支持多轮对话。
- 考虑对话历史的最简单的方式,就是把直到当前句的所有历史对话都拼接成单句文本,来作为模型的输入信息了。
- 选择就是单向语言模型(LM、GPT),做法如下图所示。选择当前主流的Transformer模型,按照BERT / GPT 的常规输入格式,将每句对话用[SEP]拼接起来,然后就训练一个从左往右的单向语言模型。为了区分不同的说话角色,我们对不同的说话者用不同的Segment Id区分。
- 此外,考虑到BERT和GPT都是用了绝对位置编码,可处理的文本长度存在一个上限,而对话轮数理论上是无限的,这里可以采用相对位置编码的NEZHA作为基本结构,并使用NEZHA的预训练权重作为模型的初始化权重。
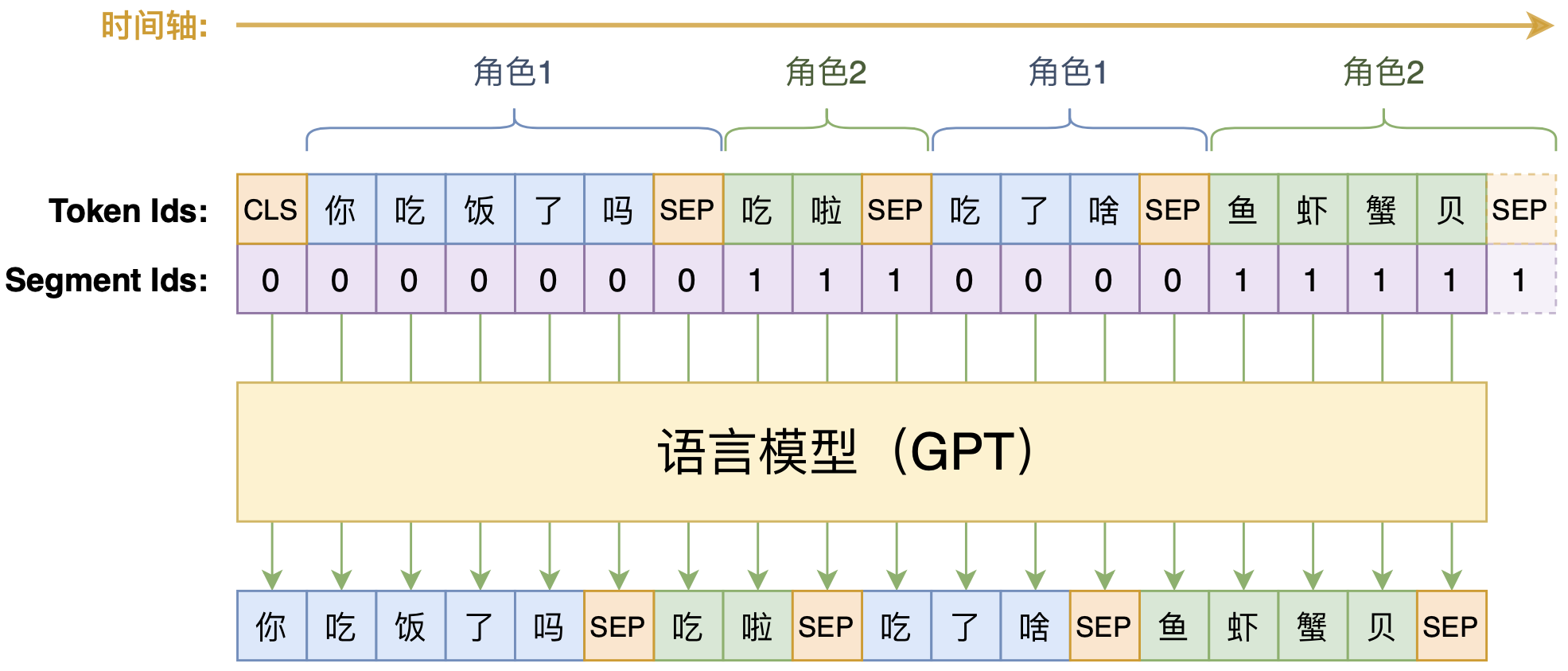
利用单向语言模型做多轮对话示意图
另外,CDial-GPT也开源了自己训练的预训练模型,如下图:
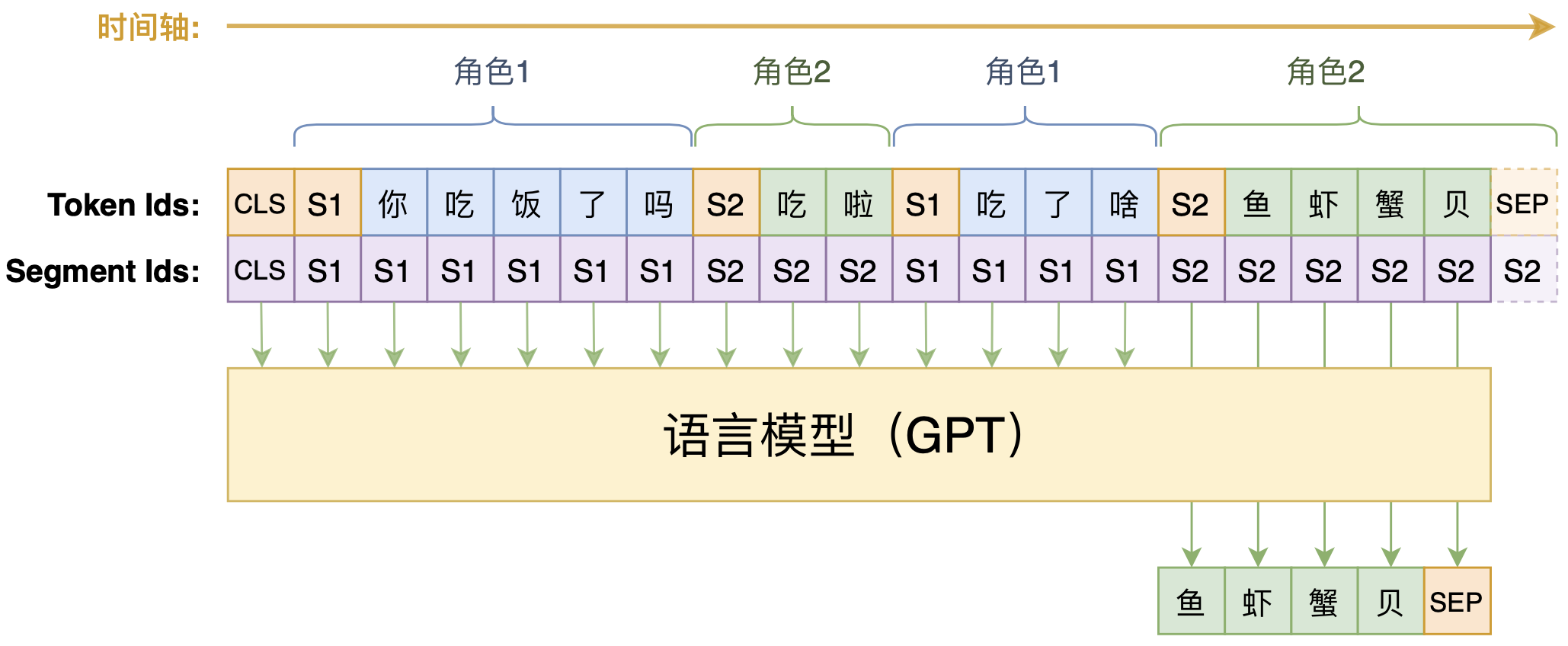
CDial-GPT模型示意图
如图所示,CDial-GPT跟前述设计的主要不同是多轮对话之间的拼接方式,我们之前是直接用[SEP]连接,它是用[speaker1]、[speaker2](图中简记为S1、S2)这样的角色标记来连接,最后才用一个[SEP]表示回复结束。这样一来,由于预测部分的格式跟历史的格式不一样,因此每次只能训练一句回复,多轮对话要拆分为多个样本来训练,理论上是增加了训练复杂性的(要训练多步才能把一个多轮对话样本训练完)。
3、Seq2Seq+前缀树⭐️
对于相似问检索来说,我们输入一个问句,希望输出数据库中与之最相近的句子;对于话术推荐,输入一个问句,希望输出话术库中与最合适的回复。这些任务本质即 seq2seq,再利用前缀树来约束解码过程,即可保证生成的结果在数据库/话术库中。
具体来说,我们用UNILM方案来训练一个Seq2Seq模型。将用户上下文 query 当作Seq2Seq的输入,将坐席客服回复(type=out)用[SEP]连接起来作为目标;推理/解码的时候,我们先把所有的坐席回复(即答案)建立成前缀树,然后按照前缀树进行 beam search 解码 and 输出结果。
注意,利用前缀树约束Seq2Seq解码其实很简单,即根据树上的每一条路径(以[BOS]开头、[EOS]结尾)查找到以某个前缀开头的字/句有哪些。然后,把模型预测其他字的概率都置零,这样模型只可能从这些字中选其一。依此类推,通过将不在前缀树上的候选token置零,保证解码过程只走前缀树的分支,而且必须走到最后,这样解码出来的结果必然是话术库中已有的句子。
在“Seq2Seq+前缀树”方案中,Seq2Seq(Roberta / UER / RoFormer+UniLM)并不是真的要去生成任意文本,而是在前缀树的约束下做本质上是检索的操作。
“Seq2Seq+前缀树”对标的是传统的稠密向量检索任务。理论上“Seq2Seq+前缀树”的检索时间是固定的,也就是说不管数据库中有多少句子,其预测时间都是常数级别。待检索句子的多少,影响的是前缀树的空间占用,基本不影响检索速度。
方案设计
算法设计
- 数据:C2 坐席半年的对话数据(20211001~20220301),通过二八分拆出训练集和评测集;
- 把直到当前句的所有历史对话都拼接成单句文本(q1+a1+…+qn+an)作为输入,预测回复话术(分类);
- 将历史聊天记录构建成“N+1”QA问答对的形式,前N句看作问题Q,后1句作为回复话术A,通过[SEP]占位符拼接;
- 在线更新。需要设计在线实时更新的pipeline。
- 机器。阿波罗的多gpu的机器(8 卡),搭建Docker+配置Conda+安装依赖包;
- 模型的训练策略:
- 当做单标签多分类任务,类别数很大,效果不一定好;
- 类似nlu度量学习,转化成检索式的问答模型:多分类任务训练,保存编码模型,最后向量相似度检索;
- 交互精排:拼接【问题+话术】作为模型的输入,二分类任务(相似/不相似),需要一个召回模型~
- 双塔模型,问题bert+话术bert(二者可共享权重),预测(相似/不相似);
- seq2seq+前缀树(参考方案调研 3)
- 算法效果评估,分类方案使用 pearson和spearman系数双50%,生成方案使用 BLEU评分;
- 坐席推荐选 pearson和spearman 系数进行评测,这里说下原因:(评测集
- 省去了需要召回阶段才能评测,省事
- 直接对QA对进行打分,然后用pearson和spearman去计算 socre list 和 label list 的趋势契合度
- 如果以 ACC/F1 来评测,需要人工卡阈值,才能评估模型的分类准确性;
- 如果以 pearson/spearman 评测,看趋势,可以评估模型的排序相关性;
- 话术推荐是一个非二分类问题,不关心绝对得分大小,而是关心相对得分大小,只要整体得分趋势接近,即可用于特征的对比排序
- 好比有一个q,它有一个正例a1和一个难负例a2,推理出的分数为0.9和0.8,如果是走ACC,默认0.5的阈值,会得到俩1,0.5的ACC。而如果是走spearman或pearson,会是[0.8,0.9]对应[0,1]的label,趋势是一致的
- 坐席推荐选 pearson和spearman 系数进行评测,这里说下原因:(评测集
模型的训练策略C,精排策略的具体细节:
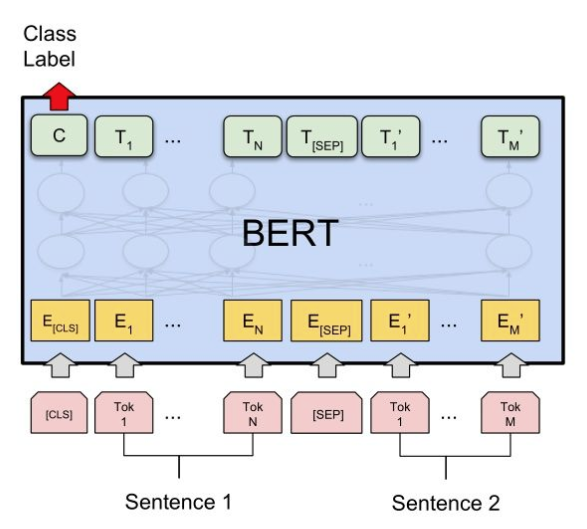
- 问题的拼接:
首先将查询和每一个候选文档一起作为Bert模型的输入,开始加入[CLS]标记。查询和文档之间加入[SEP]标记。利用BPE算法等进行分词,得到Bert模型的输入特征向量。 - 相似度计算:
将特征向量输入Bert后,经计算将得到BERT的输出(句子中每个词的向量表示),取[CLS] 标记的向量表示,通过一个单层或多层的线性神经网络,得到两个文档的相似度得分(相似的概率)。
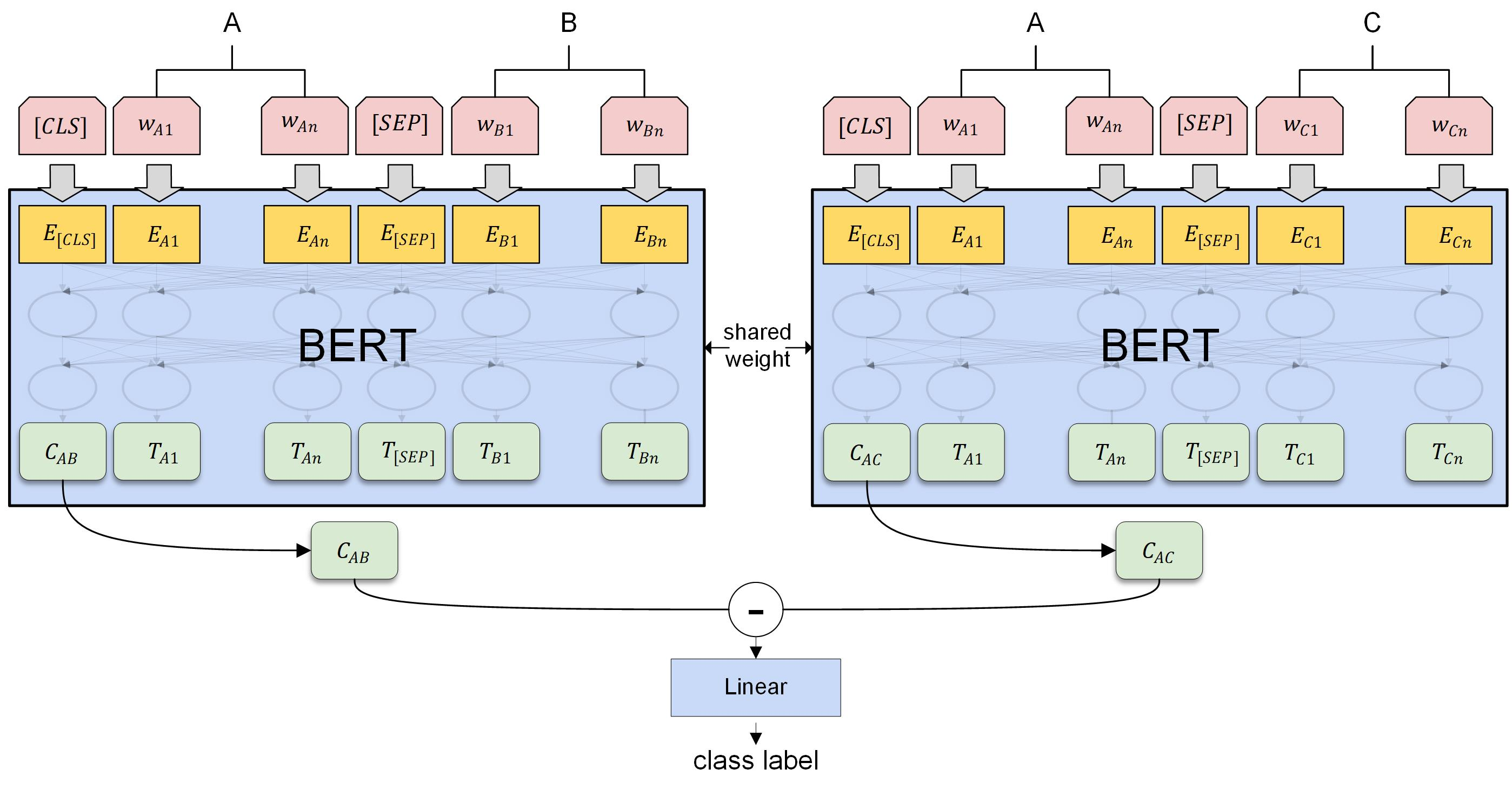
模型的训练策略D,孪生策略的具体细节:
- BERT 模型共享权重;
- 将两个 CLS 取出作差 or 级联,最后通过Dense+Softmax进行分类;
- 使用交叉熵计算二分类损失 or margin loss
1、通用 margin loss 如下: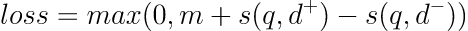
2、Triple loss function为:

工程设计
- 算法模块在整个流程中的角色是什么,上下游接口怎么样。
- 数据流是怎么走的,需要确认,包括离在线,搜索系统的话不仅考虑用户query等信息,还有物料的信息怎么存储,另外如果个性化,还有用户画像的数据问题。
- 中间件的使用和维护,如常用的数据库mysql、ES、redis之类的,还有些类似kafka、hadoop全家桶之类的。
- ……
参考

若有收获,就点个赞吧
0 人点赞
