layout: post
title: Keyword-BERT
subtitle: Keyword-BERT——问答系统中语义匹配的杀手锏
date: 2021-11-15
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- Keyword-BERT
腾讯微信团队于2020年提出的一种深度语义匹配方法的论文。在QA检索问题中,新输入的一个问法,就需要与语料库中的所有问题-答案对(QA对)进行语义相关性匹配。但是在开放领域的场景下,由于在“问法-问题”对中会存在各式各样不同表达的词汇,导致衡量新问法与候选QA对的相似性就变的富有挑战性。Keyword-BERT提出了一种“关键词-注意力机制”的方法来改进深度语义匹配任务。首先从海量的语料中按领域划分来生成领域相关的关键词字典。在基于BERT原有架构的基础之上,再堆叠一层“关键词注意力”层来强调在“问法-问题”对中出现的关键词。在模型的训练过程中,提出了一种新的,基于输入问法对中的关键词重合度的负样本采样方法。最终在中文QA语料上利用多种评估指标对模型进行了验证,包括召回候选数据的精确率,语义匹配的准确率。实验表明,Keyword-BERT超过了现有的其他基线模型。
- 论文链接:https://arxiv.org/pdf/2003.11516.pdf
- github地址:https://github.com/DataTerminatorX/Keyword-BERT
- 论文相关博客:https://mp.weixin.qq.com/s/_QY2EhB-TiBcb5q0379McQ
背景
检索式问答系统大致的流程如下:
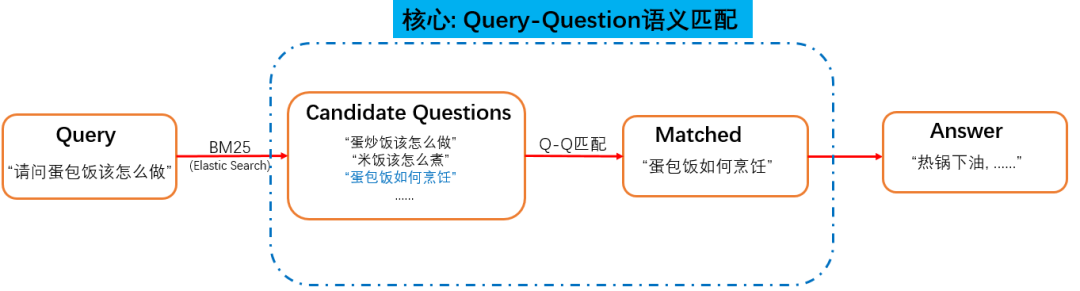
首先我们需要维护一个海量且高质量的问答库。然后对于用户的问题(Query),我们从问答库里先粗略地检索出比较相似的问题 (Questions),对于这些候选问题,再进一步进行『语义匹配』,找出最匹配的那个问题,然后将它所对应的答案,返回给用户。我们可以看到,粗略检索出来的 Question,里面噪音很多,跟我们的 Query 相比,很多都是 形似而神不似。所以最最最核心的模块,便是Query-Question 的语义匹配,用来从一堆形似的候选问题中,找出跟 Query神似的 Question。
挑战
系统鲁棒性不⾜
- 字面相似case不同义(False Positive)
- 同义case表述不同(False Negative)

蓝色加粗的词代表模型自以为匹配上的关键信息,红色代表实际要匹配的关键信息、但模型失配了。
此外,不同的term对于搜索的意义也不同,例如“桃子味的牙膏”,这里的桃子是修饰牙膏的,核心词为“牙膏”,核心词应该就有更高的查询分值。在意图类目识别时也应该根据核心词来确认。所以提前对query做同义词转化、词性分析POS,命名实体识别NER,计算词语权重Term Weight等将会帮助检索。
方法
Keyword-BERT对传统语义匹配模型的框架做了两处改进,一处是加入了 关键词系统,从海量的开放域中提取关键词/词组,然后给训练样本/预测样本中出现的关键词,额外添加一个标注。另一处,是对模型做相应改进,去增强模型对这种关键信息的捕获。这两处改动的核心,是为数据和模型 显式地引入关键信息,这样我们便能从根本上解决我们所面临的数据和模型的痛点,不再只是隔靴搔痒。
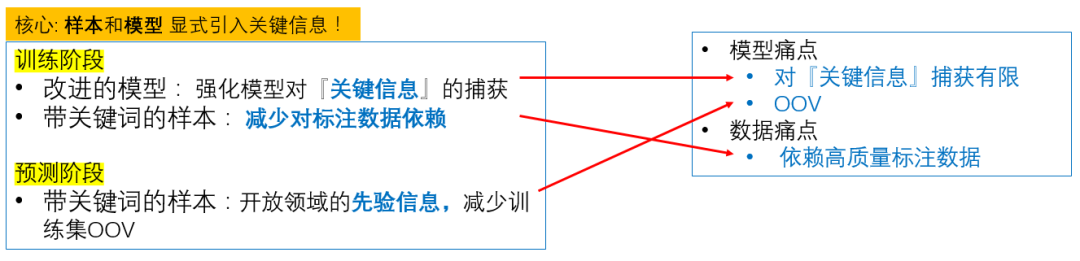
1. 改进的模型:强化模型对关键信息的捕获
这一点很好理解,我们在模型中,额外增加了对关键词词对儿的处理,相当于增加了额外的 feature,给模型提供更多信息,加强模型对问题对儿的区分能力。至于具体的改进细节,我们将会在下节提到,这里先不表。
2. 带关键词的样本:减少对标注数据依赖
我们举个例子,也是我们在引子部分提到的一个负样本:怎么扫码加微信和怎么扫码进微信群。这两个问题不相似的根源,在于微信和微信群的含义不同。但模型一开始学出来的可能是加和进这两个动词的差异(因为微信和微信群的embedding可能非常接近),只有我们提供了额外的样本,比如告诉模型怎么加豆瓣小组和怎么进豆瓣小组这两个问题是相似的,模型才可能学出进和加不是关键,继而学到真正的关键信息。所以如果我们一开始就标注出关键词,相当于告诉模型,这些是候选的、可能的关键信息,模型(经过我们改进后的)就会有意识地针对这部分进行学习,而不需要自行通过更多的样本去判别,从而从根本上解决对标组数据的依赖。
如何构造一个 关键词系统?
如上面所说,一个好的关键词系统,要能抽取出多又好的关键词——即:数量多、质量高。为了达成这个目标,采用新词发现/PMI方法从里面提取出候选的关键词。PMI的计算公式如下,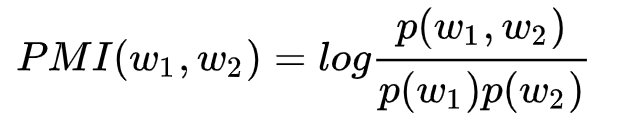
然后设计了一个 diff-idf 分值,去衡量这个关键词的领域特性,直观来说,就是这个关键词在自己领域出现的文档频次,远高于其他领域。计算方法如下所示,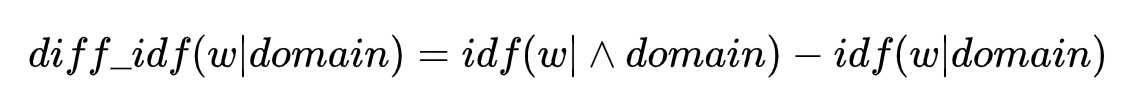
其中 ^domain 表示“其他领域”的语料。举个例子,比如我们计算,“杠杆”这个词在金融领域中的重要性,那么“其他领域”就指,非金融类的语料。这里,我们用“df”来替代“tf”,是因为我们认为评估一个词汇在这个领域的重要性,在篇章(document-level)中的频次,比在词组(term-level)中的频次更为重要。而减去“其他领域”中的idf值能够确保计算出的值,是具有区分度的,能够真正代表该词在目标领域的重要性。从直觉上来说,如果一个词,在每一个领域的文章中都比较平均的出现,那么它的“diff-idf”分值会变小,因为需要同时减去,“其他领域”的idf值。我们最终就利用,“diff-idf”值来排序候选词并剔除那些低于阈值的噪声词汇。
通过这个分值排序截断后,再进行后处理,去除噪音、实体归一化等等,最后与一些公开词条一起,构成一个庞大的关键词词典。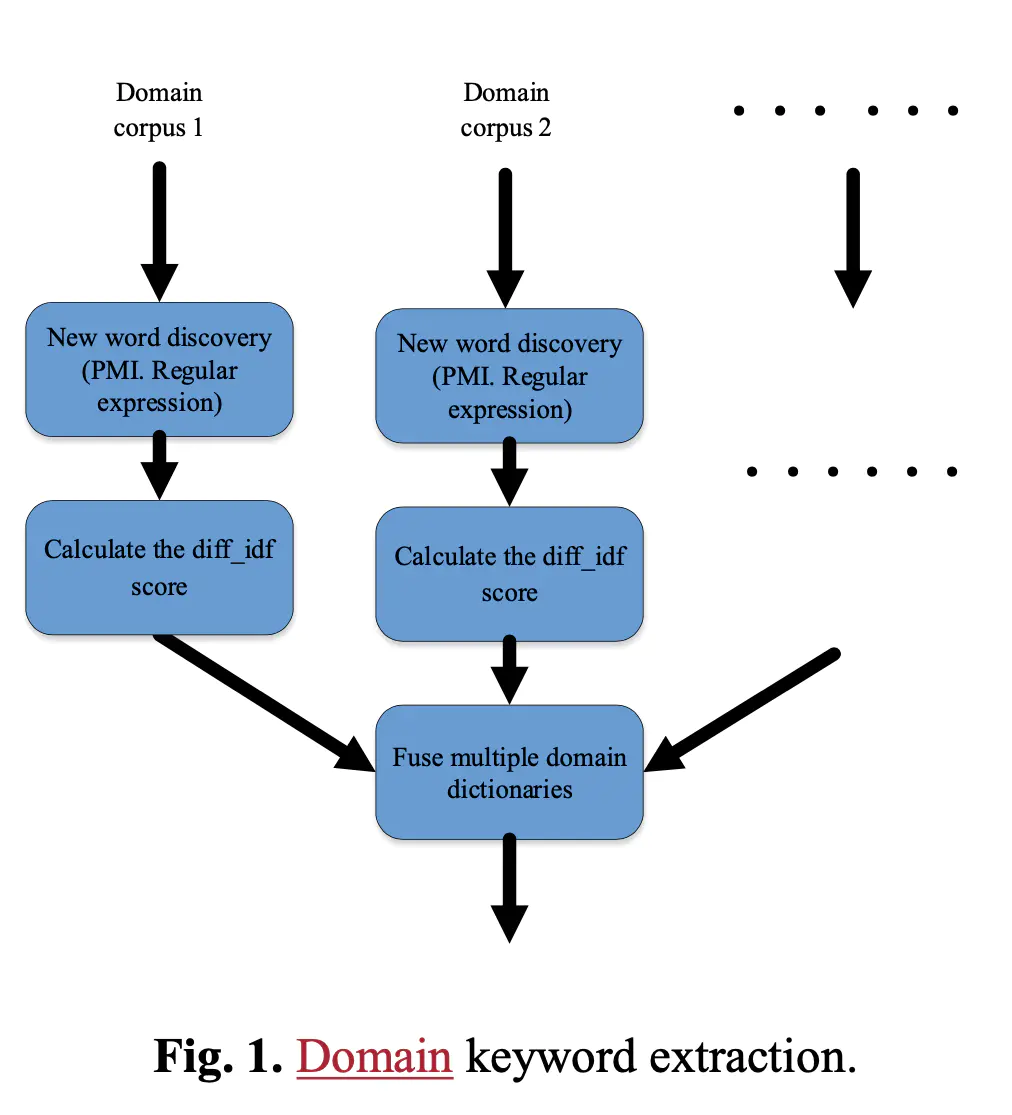
具体的流程如下(比较细碎 但缺一不可)。
这个流程每天都在运行和更新,我们目前的关键词数量达到数百万级,人工评测的质量也不错。下面是一些 case 展示:
如何改进模型?
BERT 相比其他已知的深度模型,是核弹级别的改进,所以我们理所当然地选择了它 (事实上我们也做了线下实验,结果都在意料之中)鉴于 BERT 的结构已家喻户晓,我们就不细述了,我们重点思考的,是如何给 BERT 增加额外的关键信息捕捉模块?我们的思路跟 Fastpair 的改进一脉相承,只不过将这种 pair-wise 的交互,变成了 attention 机制,具体细节如下:
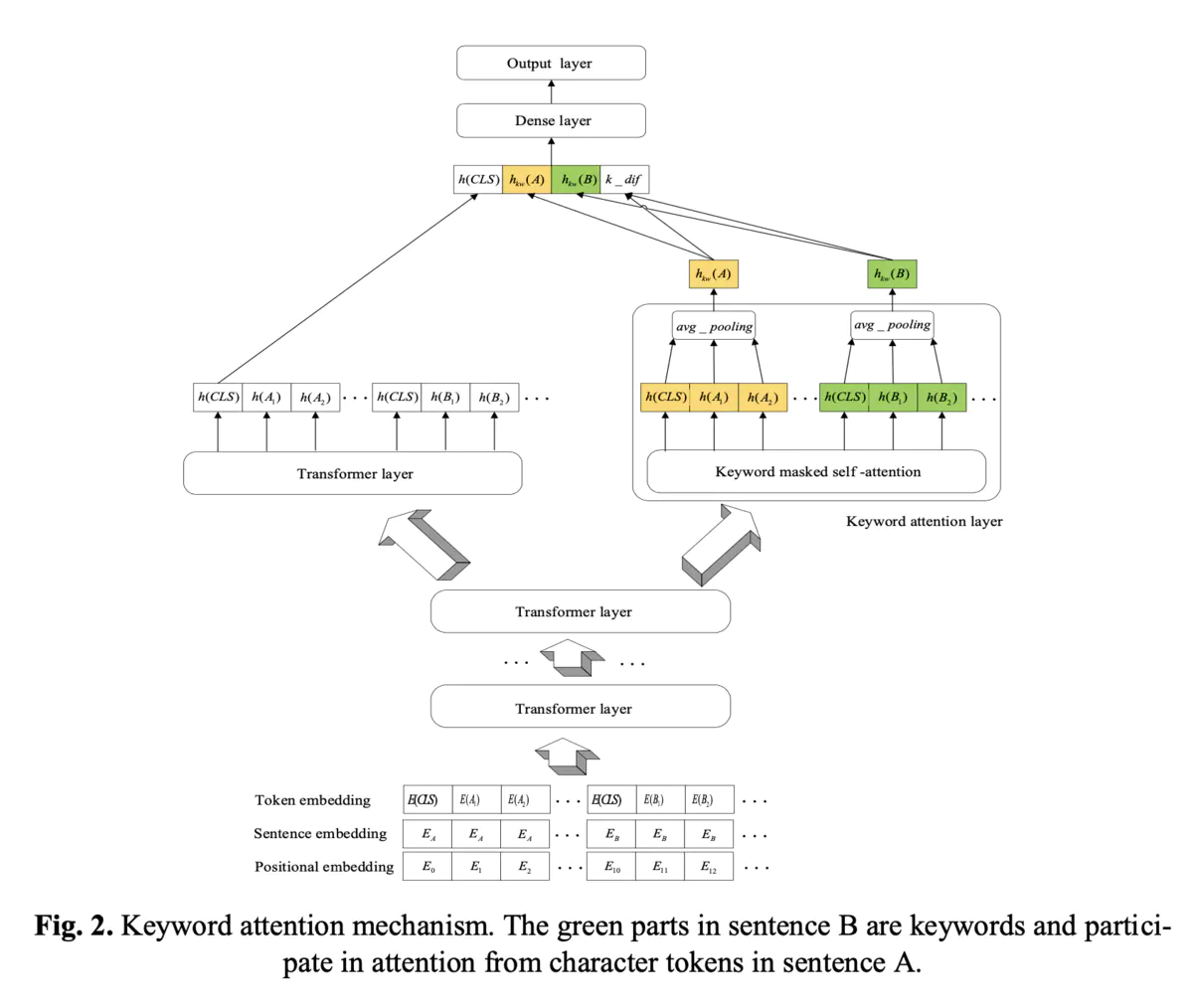
注意力机制对于语义匹配来说是非常重要的,然而,因为缺少额外的监督信息,深度模型往往不能够准确捕获在句子对中的关键信息,从而对这两句话做准确的相似度区分。从pair2vec受到的启发,我们提出的模型更加会关注到那些包含关键词的词组对。具体如下图3所示,在句子A中的每一个字符,只会与句子B中的关键词的字符做点乘。
一方面,我们在最上层引入一个额外的 keyword layer,通过 attention 和 mask ,专门对两个文本之间的关键词信息进行互相之间的 attention, 增强他们之间的互信息,另一方面,对于输出的两个文本的表示,我们借鉴了机器阅读理解里 fusion 的思想进行融合,然后将融合后的结果和 CLS 一起,输出到分类层通过这样的改造,Keyword-BERT 在不同 layer 数目下的指标都优于原始 BERT。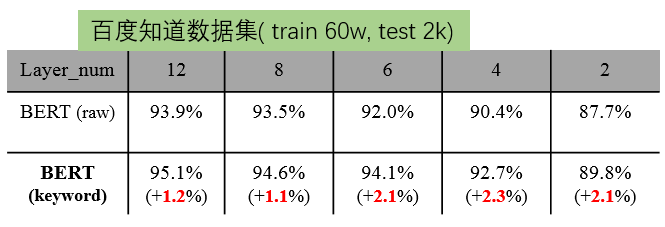
我们发现, layer 数越少,Keyword-BERT 相比原始 BERT 提升越明显。这也很好理解,因为 layer 数越少, BERT 所能学到的句子级别的信息越少,而关键词相当于对这种句子级别信息进行了补充。
参考

若有收获,就点个赞吧
0 人点赞
