layout: post # 使用的布局(不需要改)
title: FlashText高效关键词查找与替换 # 标题
subtitle: FlashText算法可用于大规模替换、检索文档中的关键字 #副标题
date: 2020-03-23 # 时间
author: NSX # 作者
header-img: img/post-bg-2015.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: #标签
- 关键词匹配
FlashText 介绍
通常,我们使用Python 在文本中进行关键词查找或替换时,会使用 re 模块以正则的形式实现。在文本数量、文本内容、关键词数量较小时,该方法能够满足我们程序的功能、性能需要。但当在大规模的文本或者对大量关键词语料查找或者替换,re 实现方案的性能将成为瓶颈,本文我们将介绍一种新的关键词搜索和替换的算法:Flashtext 算法,它是一个高效的字符搜索和替换算法。
先来看个例子。正则表达式在一个 10k 的词库中查找 15k 个关键词的时间差不多是 0.165 秒。但是对于 Flashtext 算法而言只需要 0.002 秒。因此,在这个问题上 Flashtext 的速度大约比正则表达式快 82 倍。随着我们需要处理的字符越来越多,正则表达式的处理速度几乎都是线性增加的。然而,Flashtext 的复杂度几乎保持在一个常量。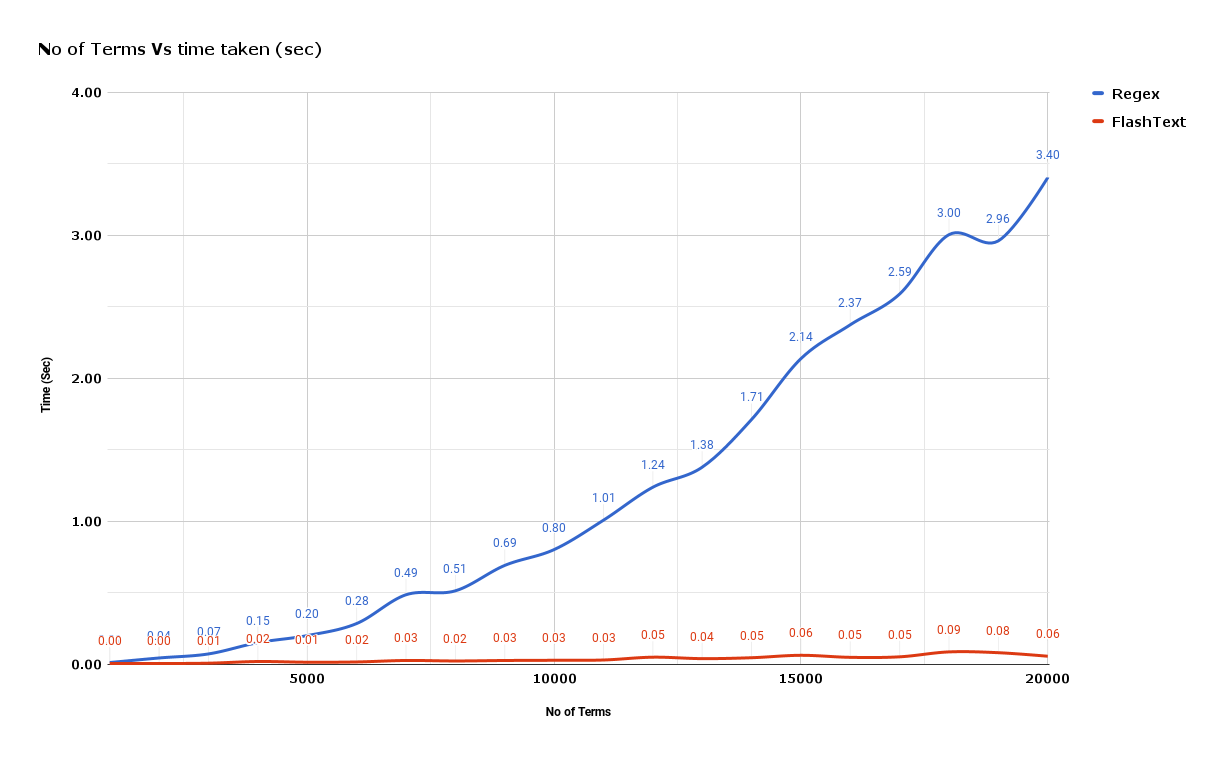
为何存在这么大的差异呢?Flashtext 算法的时间复杂度不依赖于查找或替换的字符的数量。如,对于一个文档有 N 个字符,和一个有 M 个词的关键词库,那么时间复杂度就是 O(N) 。而正则匹配的时间复杂度是 O(M * N) 。这也是两者在性能上的差异随着关键词数量增多而拉大的原因。
因此,在一些大数据下的内容检索和替换,我们更倾向于选择 Flashtext 算法 ,比如,自然语言处理领域中数据清洗是一项必须的操作。经常涉及使用标准的关键词替换一些非标准的词,如,将Javascript替换成JavaScript。或者我们需要判断文本中是否存在JavaScript 关键词等等。
接下来,就让我们了解一下,如何使用Flashtext 实现关键词的查找和替换。
FlashText 算法分析
Flashtext 是一种基于 Trie 结构和 Aho-Corasick 的算法,可用于大规模替换、检索文档中的关键字。

Flashtext 算法主要分为三部分,我们接下来将对每一部分进行单独分析:
- 构建 Trie 字典
- 关键词搜索
- 关键词替换
构建 Trie 字典
Flashtext 是一种基于 Trie 字典数据结构和 Aho Corasick 的算法。它的工作方式是,首先它将所有相关的关键词作为输入,使用这些关键词建立一个 trie 字典,利用字符串的公共前缀最大限度地减少不必要的字符串比较,提高查询效率.
为了构建 trie 字典,Flashtext 创建一个空的节点指向空字典。这个节点被用作所有关键词的起点。我们在字典中插入一个关键词。这个关键词中的下一个字符在本字典中作为关键词,并且这个指针需要再次指向一个空字典。这个过程不断重复,直到我们达到单词中的最后一个字符。当我们到达单词的末尾时,我们插入一个特殊的字符(eot)来表示词尾,如下: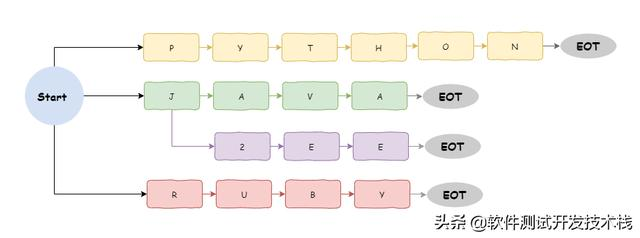
start 和 eot 是两个特殊的字符,用来定义关键词的边界,因此,也可知 Flashtext 只匹配完整的单词,这个 trie 字典就是我们后面要用来搜索和替换的数据结构。
关键词搜索
对输入查询中的字符进行逐个遍历,基于Aho Corasick算法在构建好的前缀树上实现多模串匹配(其中Trie树负责状态转移,KMP负责减少重复匹配)。当匹配到EOT特殊字符时,意味着匹配成功,我们将匹配到的字符序列所对应的标准关键词进行输出。
关键词替换
Flashtext 对输入文本中的字符进行逐个遍历,Flashtext 先创建一个空的字符串,当字符序列中的 word 无法在 Trie 字典中找到匹配时,那么Flashtext 就简单的原始字符复制到返回字符串中。但当Flashtext 可以从 Trie 字典中找到匹配时,那么Flashtext 将把匹配到的字符的标准字符复制到返回字符串中。因此,返回字符串是输入字符串的一个副本,唯一的不同是替换了匹配到的字符序列。
FlashText vs. Aho Corasick
FlashText算法和 Aho Corasick 算法的不同之处在于,它不匹配子字符串。Flashtext 算法被设计为只匹配完整的单词。比如,我们输入一个单词 {Apple},那么这个算法就不会去匹配 “I likePineapple” 中的 apple。这个算法也被设计为首先匹配最长字符串。在举个例子,比如我们有这样一个数据集 {Machine, Learning,Machine Learning},一个文档 “I like Machine Learning”,那么我们的算法只会去匹配 “MachineLearning” ,因为这是最长匹配。
什么时候应该使用 FlashText?
简单的答案:当关键词数 > 500 时,对于搜索,FlashText 在大约超过 500 个关键词后性能优于正则表达式。
复杂的答案:正则表达式可以基于特殊字符搜索关键词,如 ^,$,*,\d,.,FlashText 不支持这个。
因此,如果您想像 word\dvec 这样匹配部分词,最好不要用 FlashText。但像 word2vec 这样提取完整的单词,就非常适合了。
FlashText库使用方法
1、安装
pip install flashtext
2、导入词库
首先传入一个关键词列表。此列表将在内部用于构建 Trie 字典
from flashtext.keyword import KeywordProcessorkp = KeywordProcessor()keyword_dict={"fruit": ["apple", "banana","orange","watermelon"],"ball": ["tennis", "basketball","football"]}keyword_processor.add_keywords_from_dict(keyword_dict) # 可以添加dictkeyword_processor.add_keywords_from_list(["fruit", "banana"]) # 可以添加list
3、关键词提取
from flashtext.keyword import KeywordProcessorkeyword_processor = KeywordProcessor(case_sensitive=False)keyword_processor.add_keyword('Big Apple', 'New York')keyword_processor.add_keyword('Bay Area')keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.',span_info=True)keywords_found# ['New York', 'Bay Area']
其中:
- case_sensitive,是否对大小写敏感
- span_info,是否要返回位置信息
4、关键词替换
您也可以替换句子中的关键词,而不是提取它。我们用这作为数据处理流程中的数据清理步骤。
from flashtext.keyword import KeywordProcessorkeyword_processor = KeywordProcessor()keyword_processor.add_keyword('Big Apple', 'New York')keyword_processor.add_keyword('New Delhi', 'NCR region')new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')new_sentence# 'I love New York and NCR region.'
5、删除关键词
keyword_processor.remove_keyword('banana')keyword_processor.remove_keywords_from_dict({"food": ["bread"]})keyword_processor.remove_keywords_from_list(["basketball"])123456
参考
- [译] 正则表达式要跑 5 天,所以我做了个工具,只跑 15 分钟。
- Regex was taking 5 days to run. So I built a tool that did it in 15 minutes.
- FlashText – A library faster than Regular Expressions for NLP tasks
- Flashtext:大规模数据清洗的利器
- 超大规模文本数据清洗、查找、匹配神器之python模块flashtext学习使用
- python 关键词快速匹配
- 大量的数据做字符串匹配_Python Flashtext 实现大数据集下高效的关键词查找和替换…

若有收获,就点个赞吧
0 人点赞
