layout: post
title: NLP数据增强方法总结
subtitle: NLP数据增强方法总结
date: 2020-07-03
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- 数据增强
转载自 标注样本少怎么办?「文本增强+半监督」方法总结 - 知乎
Colab 代码:Consistency training with supervision
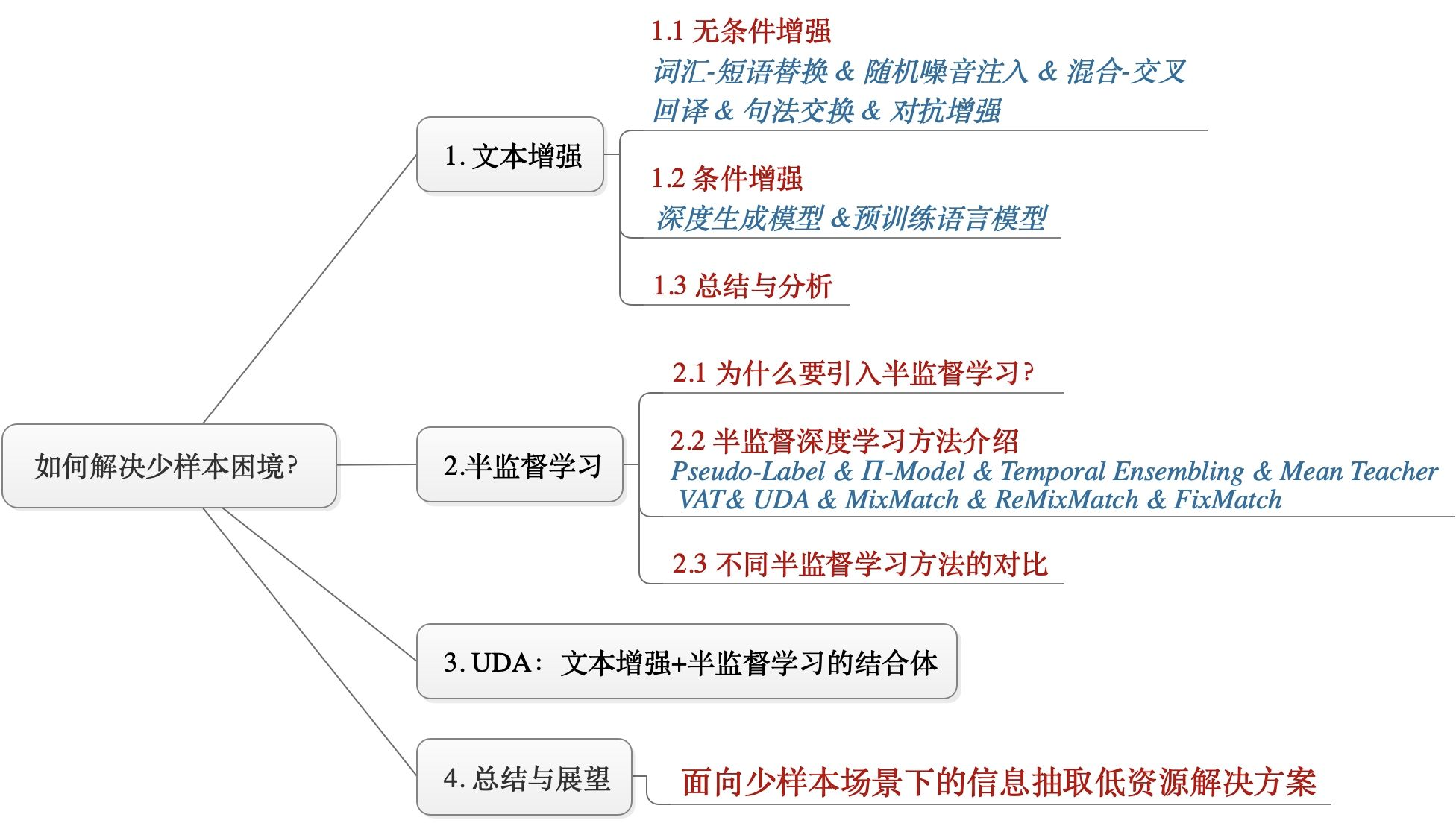
1、NLP中的文本增强技术总结
[1] A Visual Survey of Data Augmentation in NLP
1.1 无条件增强
定义:既可以对标注数据进行增强(增强后标签不发生变化),又可以针对无标注数据进行增强,不需要强制引入标签信息。
- 词汇&短语替换
- 基于词典:主要从文本中选择词汇或短语进行同义词替换,词典可以采取WordNet或哈工大词林等。著名的EDA(Easy Data Augmentation)[2] 就采用了这种方法。
- 基于词向量:在嵌入空间中找寻相邻词汇进行替换,我们所熟知的TinyBERT[3] 就利用这种技术进行了数据增强。(采用了经过预训练的词嵌入,并使用嵌入空间中最近的邻居词代替句子中某个词) ``` import gensim.downloader as api
model = api.load(‘glove-twitter-25’)
model.most_similar(‘awesome’, topn=5)
- Masked LM:借鉴预训练语言模型(如BERT)中的自编码语言模型,可以启发式地Mask词汇并进行预测替换。
from transformers import pipeline
nlp = pipeline(‘fill-mask’)
nlp(‘This is
[{‘score’: 0.515411913394928,’sequence’: ‘ This is pretty cool‘,’token’: 1256},
{‘score’: 0.1166248694062233,’sequence’: ‘ This is really cool‘,’token’: 269},
{‘score’: 0.07387523353099823,’sequence’: ‘ This is super cool‘,’token’: 2422},
{‘score’: 0.04272908344864845,’sequence’: ‘ This is kinda cool‘,’token’: 24282},
{‘score’: 0.034715913236141205,’sequence’: ‘ This is very cool‘,’token’: 182}]
```
- TF-IDF:基本思想是,TF-IDF分数较低的单词是无意义的,因此可以替换而不会影响句子的真实标签。它实质上是一种非核心词替换,对那些low TF-IDF scores进行替换,这一方法最早由Google的UDA[4]提出
- 随机噪音注入



注意:EDA [2] 除了进行同义词替换外,也同时采用上述三种随机噪音注入。
混合&交叉
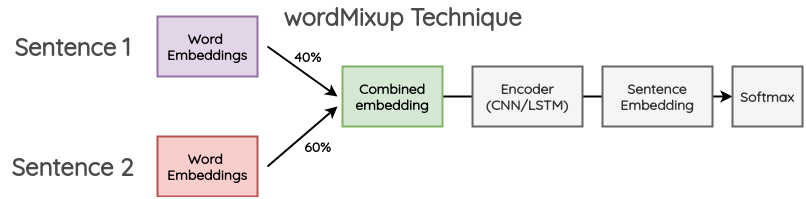
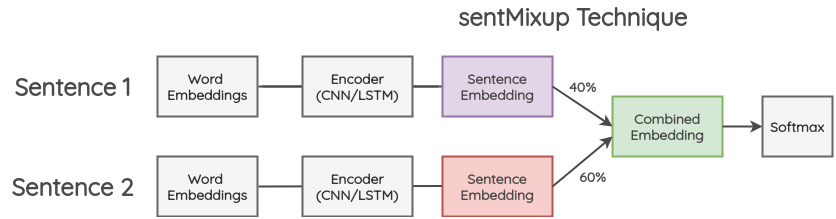
混合增强:起源于图像领域的Mixup[5],这是一种表示增强方法,借鉴这种思想,文献[6]提出了wordMixup和sentMixup将词向量和句向量进行Mixup。

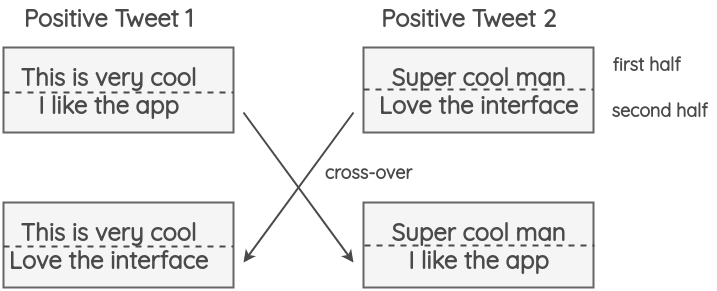
交叉增强:类似于“染色体的交叉操作”,文献[7]将相同极性的文本进行交叉:
回译:基于机器翻译技术,例如从中文-英文-日文-中文;我们熟知的机器阅读理解模型QANet[8]和UDA[4]都采用了回译技术进行数据增强。
句法交换:通过句法树对文本句子进行解析,并利用相关规则进行转换,例如将主动式变成被动式句子。
对抗增强: 不同于CV领域利用GAN生成对抗进行数据增强[9],NLP中通常在词向量上添加扰动并进行对抗训练,文献[10]NLP中的对抗训练方法FGM, PGD, FreeAT, YOPO, FreeLB等进行了总结。
本节介绍的无条件增强方法,在对标注数据进行增强后标签不发生变化,但可能会造成文本主旨发生发生变化(例如情感分析中,某一时刻将good 替换为了bad),带来的噪音过大从而影响模型性能。因此,我们是否可以考虑引入标签信息来引导数据生成呢?
1.2 条件增强
定义:所谓条件增强(Conditional Data Augmentation),就是意味着需要强制引入「文本标签」信息到模型中再产生数据。
深度生成模型:既然条件增强需要引入标签信息进行数据增强,那么我们自然就会联想到Conditional变分自编码模型(CVAE),文献[11]就利用CVA进行增强。想生成一个高质量的增强数据,往往需要充分的标注量,但这却与我们「少样本困境」的这一前提所矛盾。这也正是GAN或者CVAE这一类深度生成模型在解决少样本问题时需要考虑的一个现状。
预训练语言模型:众所周知,BERT等在NLP领域取得了巨大成功,特别是其利用大量无标注数据进行了语言模型预训练。如果我们能够结合标签信息、充分利用这一系列语言模型去做文本增强,也许能够克服深度生成模型在少样本问题上的矛盾。近来许多研究者对Conditional Pre-trained Language Models做文本增强进行了有益尝试:
- Contextual Augment[12]:这是这一系列尝试的开篇之作,其基于LSTM进行biLM预训练,将标签信息融入网络结构进行finetune,是替换生成的词汇与标签信息兼容一致。
- CBERT[13]:其主要思想还是借鉴了Contextual Augment,基于BERT进行finetune,将segment embedding转换融入标签指示的label embedding(如果标签类别数目大于2类,则相应扩充),如下图,替换good生成的funny与标签positive兼容。
- LAMBADA [14]:来自IBM团队,其基于GPT-2将标签信息与原始文本拼接当作训练数据进行finetune(如下图所示,SEP代表标签和文本的分割,EOS是文本结束的标志),同时也采用一个判别器对生成数据进行了过滤降噪。
在最近的一篇paper《Data Augmentation using Pre-trained Transformer Models》[15]中,根据不同预训练目标对自编码(AE)的BERT、自回归(AR)的GPT-2、Seq2Seq的BART这3个预训练模型进行了对比。不同于CBERT,没有标签信息变为label embedding而是直接作为一个token&sub-token来于原文拼接。
1.3 总结与分析
至此,我们介绍完了NLP中的文本增强技术,以[15]的实验结果为例,我们可以发现文本增强技术可以满足本文一开始给出的第一层次评价策略,即:在少样本场景下,采用文本增强技术,比起同等标注量的无增强监督学习模型,性能会有较大幅度的提升。
需要注意的是,上述相关文献中,通常只针对标注数据进行文本增强。但我们是否可以充分利用领域相关的大量无标注数据解决少样本困境呢?我们将在第2部分进行介绍。
除此之外,在实践中我们也要去思考:
- 是否存在一种文本增强技术,能够达到或者逼近充分样本下的监督学习模型性能?
- 在充分样本下,采取文本增强技术,是否会陷入到过拟合的境地,又是否会由于噪音过大而影响性能?如何挑选样本?又如何降噪?
2、半监督学习
这一部分主要介绍如何结合大量无标注数据解决少样本困境,相应的弱监督方法层出不穷,本文着眼于「半监督学习」,借鉴CV领域的9个主流方法进行介绍,包括:Pseudo-Label / Π-Model / Temporal Ensembling / Mean Teacher / VAT / UDA / MixMatch / ReMixMatch / FixMatch。
2.1 为什么要引入半监督学习?
监督学习往往需要大量的标注数据,而标注数据的成本比较高,因此如何利用大量的无标注数据来提高监督学习的效果,具有十分重要的意义。这种利用少量标注数据和大量无标注数据进行学习的方式称为半监督学习(Semi-Supervised Learning,SSL) 。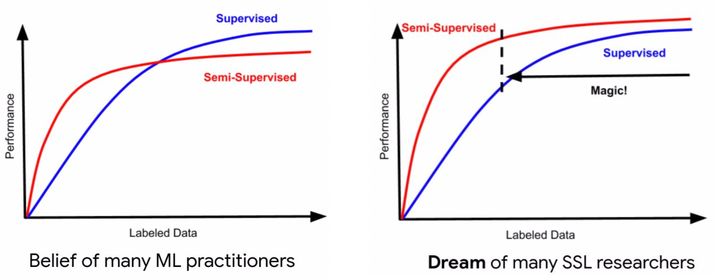
如上图所示,在同等的少量标注样本下,半监督学习通常取得比监督学习较好的性能。进入深度学习时代以来,SSL如何在少量标注样本下达到或超越大量标注样本下监督学习的效果,SSL如何在大量标注样本下也不会陷入到“过拟合陷阱”,是SSL研究者面临的一个挑战。
近年来,半监督深度学习取得了长足的进展,特别是在CV领域;相关的研究主要着力于如何针对未标注数据构建无监督信号,与监督学习联合建模;简单地讲,就是如何在损失函数中添加针对未标注数据相关的正则项,使模型能够充分利用大量的未标注数据不断迭代,最终增强泛化性能,正如下图所展示的那样(来自文献[19])。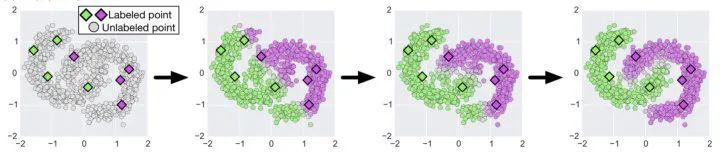
2.2 半监督深度学习方法介绍
总的来看,深度学习时代的半监督学习,主要针对未标注数据相关的正则化项进行设置,其通常有以下两种:
- 熵最小化(Entropy Minimization):根据半监督学习的Cluster假设,决策边界应该尽可能地通过数据较为稀疏的地方(低密度区),以能够避免把密集的样本数据点分到决策边界的两侧。也就是模型通过对未标记数据预测后要作出低熵预测,即熵最小化:

- 一致性正则(Consistency Regularization):对于未标记数据,希望模型在其输入
 受到扰动时产生相同的输出分布。即:
受到扰动时产生相同的输出分布。即:
重要说明: 本文将 z定义为 人工标签,其含义是构建“标签”指导一致性正则的实施,通常采取weak数据增强方法,也可能来自历史平均预测或模型平均预测。  定义为 预测标签,为模型当前时刻对无标注数据的预测,对其输入可进行strong增强或对抗扰动。
定义为 预测标签,为模型当前时刻对无标注数据的预测,对其输入可进行strong增强或对抗扰动。
(1) Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks [16]
Pseudo Label的原理很简单, 其损失函数定义为:
其中  为少量标注数据量,
为少量标注数据量,  为未标注数据量,
为未标注数据量,  为第m个标记数据的logit输出,
为第m个标记数据的logit输出,  为其对应的标签;
为其对应的标签; 为第m个未标记数据的logit输出,
为第m个未标记数据的logit输出,  为其对应的Pseudo Label,具体的做法就是选举每个未标注样本的最大概率作为其伪标签。为了降低噪音的影响,只有当置信度大于阈值时才计算相应的损失。
为其对应的Pseudo Label,具体的做法就是选举每个未标注样本的最大概率作为其伪标签。为了降低噪音的影响,只有当置信度大于阈值时才计算相应的损失。
我们可以看出上式中第二项正是利用了熵最小化的思想,利用未标注数据和伪标签进行训练来引导模型预测的类概率逼近其中一个类别,从而将伪标签条件熵减到最小。 模拟的是一个确定性退火过程,避免陷入局部最小值,调和平衡标注和未标注数据的训练,从而使伪label更接近真实标签:
模拟的是一个确定性退火过程,避免陷入局部最小值,调和平衡标注和未标注数据的训练,从而使伪label更接近真实标签: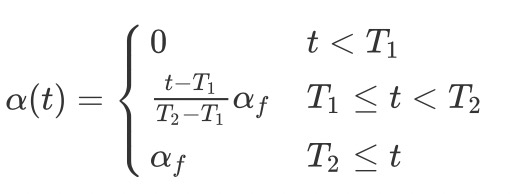
(2) Π-Model/Temporal Ensembling: Temporal ensembling for semi-supervised learning[17]
Π-Model 和 Temporal Ensembling来自同一篇论文,均利用了一致性正则。
Π-Model如上图所示,对无标注数据输入  进行了两次不同的随机数据增强、并通过不同dropout输出得到
进行了两次不同的随机数据增强、并通过不同dropout输出得到  和
和  ,并引入一致性正则到损失函数(L2 loss)中:
,并引入一致性正则到损失函数(L2 loss)中: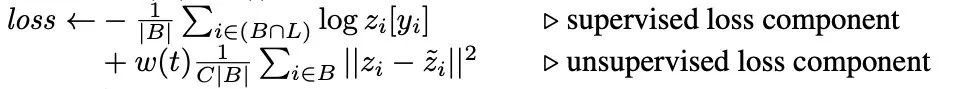
可以看出 和
和  来自同一时间步产生的两次结果,同一个train step要进行两次前向计算,可以预见这种单次计算的噪音较大、同时降低训练速度。Temporal Ensembling则采用时序融合模型,
来自同一时间步产生的两次结果,同一个train step要进行两次前向计算,可以预见这种单次计算的噪音较大、同时降低训练速度。Temporal Ensembling则采用时序融合模型, 是历史
是历史  的EMA加权平均和,将其视作人工标签,同一个train step只进行一次计算,如下图所示:
的EMA加权平均和,将其视作人工标签,同一个train step只进行一次计算,如下图所示: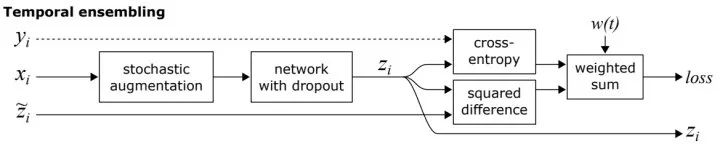
(3) Mean Teacher:Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results[18]
Mean Teacher是对Temporal Ensembling的升级,仍然采用一致性正则(L2 loss)。
Temporal Ensembling是对预测结果进行EMA平均,但是  每个epoch才更新一次,需要等到下一个epoch相关信息才能被模型学习。为克服这一缺点,Mean Teacher采取对模型参数进行EMA平均,其认为训练步骤的上平均模型会比直接使用单一模型权重更精确,将平均模型作为teacher预测人工标签
每个epoch才更新一次,需要等到下一个epoch相关信息才能被模型学习。为克服这一缺点,Mean Teacher采取对模型参数进行EMA平均,其认为训练步骤的上平均模型会比直接使用单一模型权重更精确,将平均模型作为teacher预测人工标签 ,
, 由当前模型(看作student)预测。
由当前模型(看作student)预测。
(4) Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning[19]
Virtual Adversarial Training(VAT)仍然采用一致性正则,学习一致性就要添加扰动。作者认为,随机扰动无法模拟复杂情况的输入,不同于上述SSL方法采用数据增强进行施加扰动,VAT采取对抗训练的方式添加噪音。
VAT不同于传统的有监督学习下的对抗训练(详细了解可阅读 @李如的一文搞懂NLP中的对抗训练),其没有标签信息,而是采用  构建一个虚拟标签,并根据这个虚拟标签计算对抗扰动方向
构建一个虚拟标签,并根据这个虚拟标签计算对抗扰动方向  (通常是梯度上升的方向,为正梯度),这也是称之为“虚拟对抗训练”的原因吧~。VAT采用KL散度来计算一致性正则:
(通常是梯度上升的方向,为正梯度),这也是称之为“虚拟对抗训练”的原因吧~。VAT采用KL散度来计算一致性正则: 
(5) UDA:Unsupervised Data Augmentation for Consistency Training[4]
UDA来自Google,同样也是采用一致性正则。一致性正则的关键在于如何注入噪声,一个好的模型对于输入扰动的任何细微变化也都应具有鲁棒性。上述SSL方法注入噪音的方法通常为高斯噪音、dropout噪音、对抗噪音,这些注入方式被认为是较弱的干扰。UDA针对图像采取一种高质量的数据增强方法——RandAugment ,通过这种strong的干扰来提高一致性训练性能。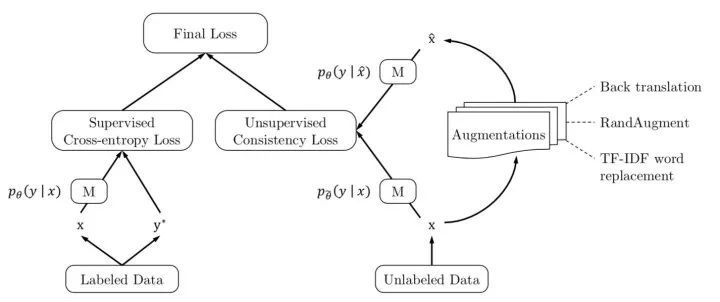
上图为UDA的损失函数,核心在于对无标注数据  通过strong增强转化为
通过strong增强转化为  ,采用KL散度来计算两者间的一致性损失。UDA也通过回译和非核心词替换对文本进行无监督增强,我们将在第3部分作详细介绍。
,采用KL散度来计算两者间的一致性损失。UDA也通过回译和非核心词替换对文本进行无监督增强,我们将在第3部分作详细介绍。
此外,UDA也利用了一些辅助技术:
- 结合了熵最小化正则:对无监督信号
 进行sharpen操作构建人工标签,使其趋近于 One-Hot 分布,对某一类别输出概率趋向 1,其他类别趋向0,此时熵最低。此外,还直接计算了熵损失。
进行sharpen操作构建人工标签,使其趋近于 One-Hot 分布,对某一类别输出概率趋向 1,其他类别趋向0,此时熵最低。此外,还直接计算了熵损失。 - 将人工标签与strong增强后的预测标签共同构建一致性正则,并计算损失时进行了confidence-based masking,低于置信度阈值不参与loss计算。
- 采用训练信号退火(TSA)方法防止对标注数据过拟合,对于标注数据的置信度高于阈值要进行masking,这与无标注数据正好相反。
- 使用初始模型过滤了领域外的无标注数据。
(6) MixMatch: A Holistic Approach to Semi-Supervised Learning[20]
MixMatch同样来自Google,与UDA类似,同样结合了熵最小化和一致性正则。其重要的操作就是通过MixMatch进行数据增强,与UDA的RandAugment不同,这种增强方式依然是weak的。MixMatch具体的数据增强操作为: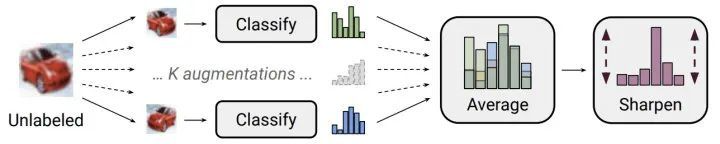

- 对标注数据进行一次增强,对于未标注数据作K次weak增强输入模型得到average后的概率,并对其进行与UDA类似的sharpen操作得到人工标签
 ,利用了熵最小化思想。
,利用了熵最小化思想。 - 将无标注数据得到的人工标签与标注数据混合在一起并进行MixUp操作,进而得到增强后的无标注数据以及标注数据。
最后对于MixMatch增强后的标注数据  和无标注数据
和无标注数据  分别计算损失项,采用L2 loss引入一致性正则:
分别计算损失项,采用L2 loss引入一致性正则:
(7) ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring[21]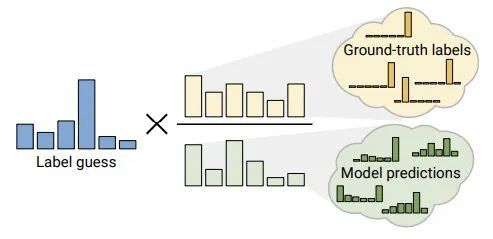
ReMixMatch是MixMatch原作者对自己工作的改进,主要有两点:
- Distribution Alignment:分布对齐,将无标注数据的人工标签与标注数据的标签分布对齐,如上图所示,根据标注数据的标签分布(Groud-truth labels)与无标注数据的平均预测(Model prediction)的比值作为“对齐因子”,缓解猜测标签的噪音和分布不一致情况。
- Strong Augmentation:MixMatch不稳定的原因可能是K次weak增强会导致不同的预测,取平均值不是具有意义的目标;ReMixMatch改进这一点,引入strong增强,将weak增强后的人工标签与strong增强后的预测标签共同构建一致性正则(KL散度)。具体的增强方式CTAugment可参考原论文。
此外,ReMixMatch还对未标注数据丢失的权重进行了退火,并引入了Rotation loss,这里不再赘述。
(8) FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence[22]
FixMatch也是来自Google,实质上是UDA和ReMixMatch一个综合简化版本,舍弃了sharpen操作和UDA的训练信号退火、ReMixMatch的分布对齐和旋转损失等。
UDA和ReMixMatch表明引入strong增强方式,在与weak增强方式一同构建一致性正则时,是有效的,FixMatch延续了这一思想,strong增强同时使用了UDA的RandAugment和ReMixMatch的CTAugment。
不同于UDA和ReMixMatch通过sharpen构建人工标签来指导一致性正则的实施,FixMatch则直接利用Pseudo-Label 构建人工标签。具体地说:
记strong增强为  和weak增强为
和weak增强为  ,对于标注数据只使用弱增强并计算交叉熵;对于无标注数据使用weak增强
,对于标注数据只使用弱增强并计算交叉熵;对于无标注数据使用weak增强  构建人工标签
构建人工标签  :
: ,使用strong增强构建预测标签,最终损失形式为:
,使用strong增强构建预测标签,最终损失形式为:
其中  为置信度阈值,对低于阈值的人工标签不参与loss计算进行confidence-based masking。
为置信度阈值,对低于阈值的人工标签不参与loss计算进行confidence-based masking。
2.3 不同半监督学习方法的对比
至此,我们已经介绍完了近年来主流的半监督深度学习方法。回顾1.1节对一致性正则公式的介绍,我们可以发现:
- 人工标签是构建“标签”指导一致性正则的实施,通常采取weak数据增强方法,也可能来自历史平均预测(Temporal Ensembling)或模型平均预测(Mean Teacher);
- 预测标签为模型当前时刻对无标注数据的预测,其输入可进行strong增强(UDA/ReMixMatch/FixMatch)或对抗扰动(VAT).
我们将其归纳如下:
下图给出了上述SSL方法在不同数据集上的性能对比(指标为错误率):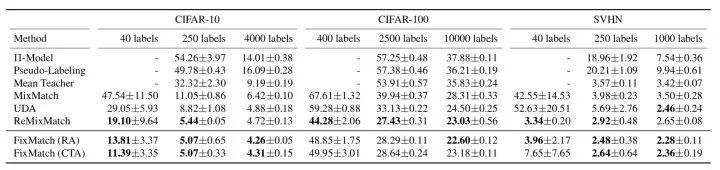
我们可以发现借鉴了UDA和ReMixMatch的FixMatch,是目前的SOTA。上述大多数SSL方法都引入了一致性正则,其关键在于如何注入噪声,一个好的模型对于输入扰动的任何细微变化也都应具有鲁棒性。也许我们可以形成一个共识:通过strong增强的预测标签与weak增强的人工标签共同构建一致性损失,能够提高一致性训练性能,充分挖掘未标注数据中潜在的价值,最终增强泛化性能。
上述结合图像数据增强的半监督学习方法在CV领域已经取得成功,基本满足本文一开始提出的三个层次评价策略,特别是:在少样本场景下可以比肩充分样本下的监督学习模型性能,而在充分样本场景下,性能仍然继续提升。相关实验可以进一步阅读CV相关论文,接下来我们主要关注其在NLP的表现。
3. UDA:文本增强+半监督学习的结合体
作为NLPer,我们更关心上述文本增强与半监督学习的结合在文本领域表现如何?我们主要介绍分析Google的UDA[4]相关结果。
本文在第1部分重点介绍了文本增强技术,文本增强方法通常针对标注数据(有监督数据增强),我们可以看到其在少样本场景通常会取得稳定的性能提升,但相较于充分样本下的监督学习性能,也许是有限的提升(“cherry on the cake”)。
为克服这一限制,UDA通过一致性训练框架(正如2.2节介绍的那样),将有监督的数据增强技术的发展扩展到了有大量未标记数据的半监督学习,尽可能的去利用大量未标记数据,这也正是论文名字——无监督数据增强(Unsupervised Data Augmentation)的由来。
UDA在六个文本分类任务上结合当前如日中天的BERT迁移学习框架进行了实验。迁移学习框架分别为:(1)Random:随机初始化的Transformer;(2):BERT_base;(3):BERT_large;(4):BERT_finetune:基于BERT_large在domain数据集上继续进行预训练;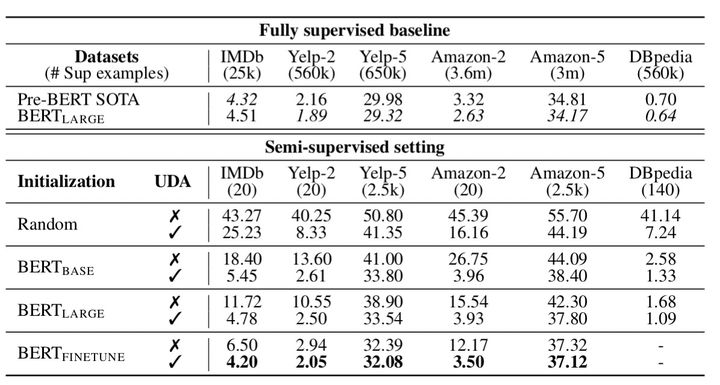
如上图所示(指标为错误率),Pre-BERT SOTA为BERT出现之前的相关SOTA模型。我们可以发现:
- 在少样本场景下,UDA相较于同等监督学习模型,性能明显提升。
- 在少样本场景下,UDA能够逼近充分样本下的监督学习模型性能,特别地,在IMDb上具有20个标注数据的UDA优于在1250倍标注数据上训练的SOTA模型。相较于2分类任务,5分类任务难度更高,未来仍有提升空间。
- UDA兼容了迁移学习框架,进一步domain预训练后,性能更佳。
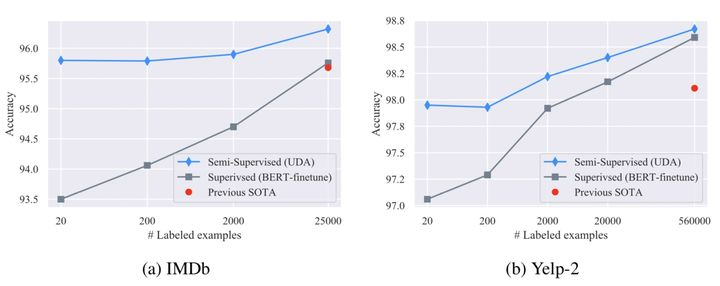
那么,在充分样本场景下,继续使用UDA框架表现如何?从上图可以看出,在更多、更充分的标注数据数量下,融合UDA框架,性能也有一定提升。
4、总结与展望
本文针对「如何解决少样本困境?」,从「文本增强」和「半监督学习」两个角度进行了介绍,简单总结如下:
- 文本增强提供了原有标注数据缺少的归纳偏差,在少样本场景下通常会取得稳定、但有限的性能提升;更高级、更多样化和更自然的增强方法效果更佳。
- 融合文本增强+半监督学习技术是一个不错的选择。半监督学习中一致性正则能够充分利用大量未标注数据,同时能够使输入空间的变化更加平滑,从另一个角度来看,降低一致性损失实质上也是将标签信息从标注数据传播到未标注数据的过程。
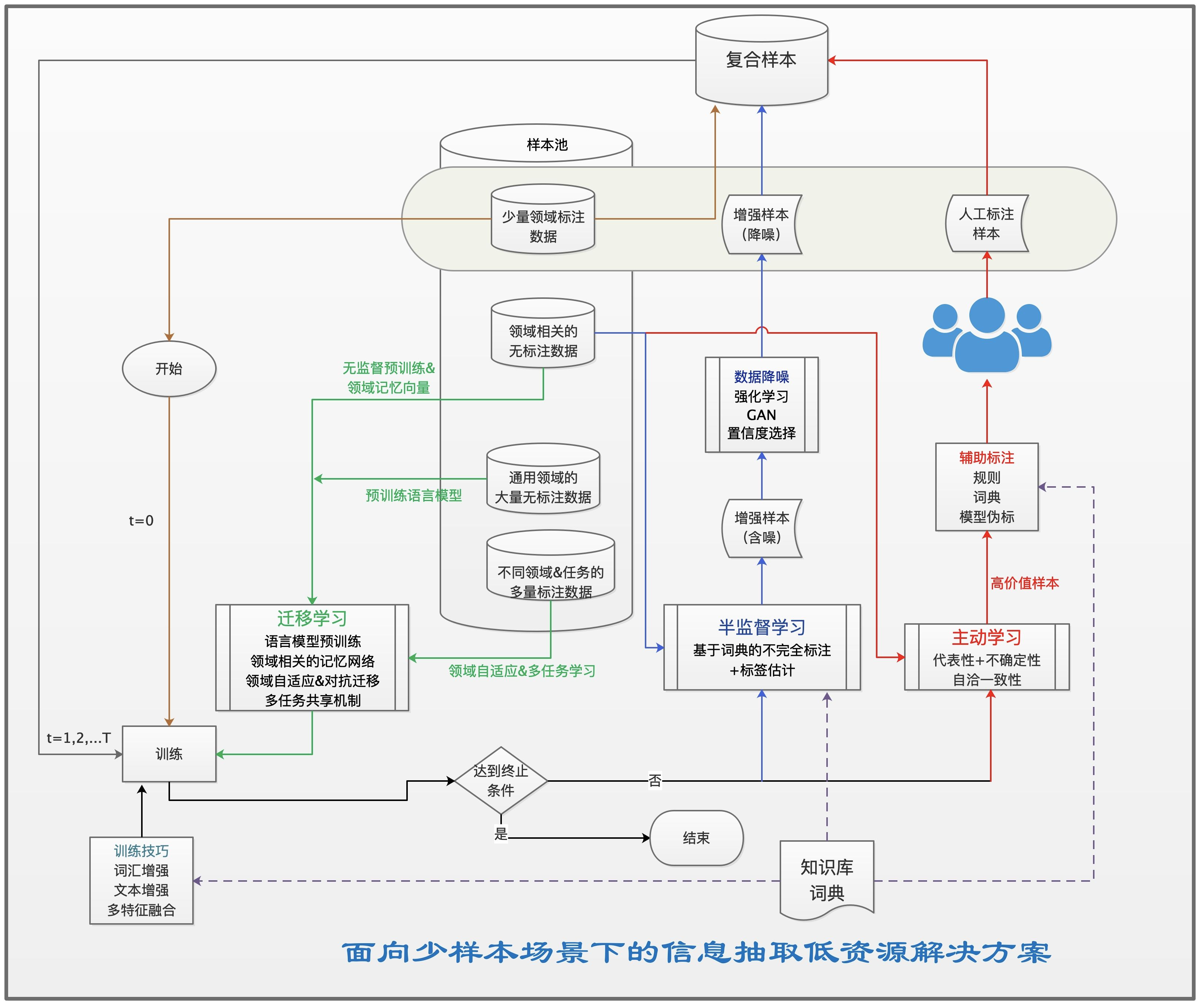
在具体实践中,如何有效地解决少样本问题需要更为全面的考虑,我们可以融合文本增强、半监督学习、迁移学习、主动学习、少样本学习等构建统一的低资源NLP解决方案;如上图所示,笔者尝试给出了信息抽取领域的少样本低资源解决方案;此外,很多弱监督学习方法也被提出,这一类方法更为关键的是如何挑选样本、如何降噪学习等,希望后续有机会与大家交流~
附录:EDA工具
- 诸如nlpaug和textattack之类的库提供了简单而一致的API,以便在Python中应用上述NLP数据增强方法。它们与框架无关,可以轻松集成到您的管道中。
- 中文语料的EDA数据增强工具:提供了四种简单的操作来进行数据增强,可以防止过拟合,并提高模型的泛化能力。使用方法(推荐)
- Synonyms中文近义词工具包
Reference
- [1] A Visual Survey of Data Augmentation in NLP
- [2] EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- [3] TinyBERT: Distilling BERT for Natural Language Understanding
- [4] Unsupervised Data Augmentation for Consistency Training
- [5] mixup: BEYOND EMPIRICAL RISK MINIMIZATION
- [6] Augmenting Data with Mixup for Sentence Classification: An Empirical Study
- [7] Data Augmentation and Robust Embeddings for Sentiment Analysis
- [8] QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
- [9] Data Augmentation Using GANs
- [10] 一文搞懂NLP中的对抗训练
- [11] Controlled Text Generation for Data Augmentation in Intelligent Artificial Agents
- [12] Contextual augmentation: Data augmentation by words with paradigmatic relations
- [13] Conditional BERT contextual augmentation
- [14] Do Not Have Enough Data? Deep Learning to the Rescue!
- [15] Data Augmentation using Pre-trained Transformer Models
- [16]Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
- [17]Temporal ensembling for semi-supervised learning
- [18]Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
- [19]Virtual Adversarial Training: a Regularization Method for Supervised and Semi-supervised Learning
- [20]MixMatch: A Holistic Approach to Semi-Supervised Learning
- [21]ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
- [22]FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence

若有收获,就点个赞吧
0 人点赞
