- Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,致力于给出神经网络的可解释的方案
- Capsule提供了一种新的、基于聚类思想来代替池化完成特征的整合的方案,这种新方案的特征表达能力更加强大,能够对输入做一个优秀的、可解释的表征。
- Capsule把聚类的迭代算法放到神经网络中,称之为做动态路由
什么是“胶囊”?
neuron: output a value, Capsule: output a vector
其实,只要把一个向量当作一个整体来看,它就是一个“胶囊”,是的,你没看错,你可以这样理解:神经元就是标量,胶囊就是向量,就这么粗暴!可以类比NLP中的one hot表示和词向量。
Capsule框架#
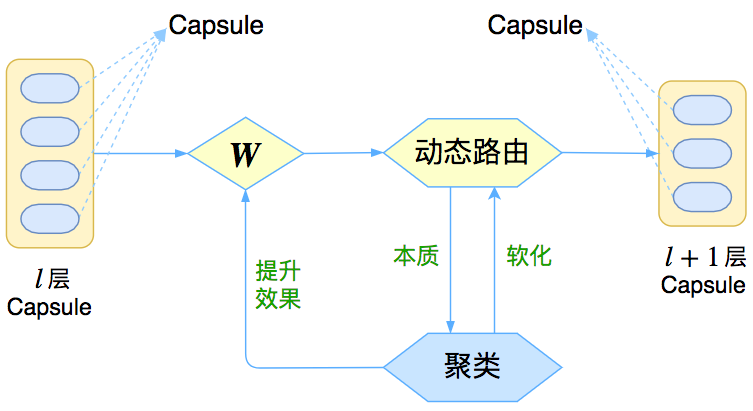
图1:Capsule框架的简明示意图
与其说Capsule是一个具体的模型,倒不如说Capsule是一个建模的框架,而框架内每个步骤的内容,是可以自己灵活替换的,而Hinton所发表的论文,只是一个使用案例。这是一个怎样的框架呢?
特征表达#
Capsule模型中,每个特征都是用一个向量(即Capsule,胶囊)来表示的。可以类比NLP中的one hot表示和词向量/“分布式表示”(Distributed Representation),我们可以用词向量代替one hot来表示一个词,这样表达的信息就更为丰富了,而且所有的词都位于同一向量空间,方便后续处理。
特征组合#
Capsule的第二个特点,是通过聚类来组合特征。
特征间聚类#
那么,怎么完成这个组合的过程呢?试想一下,两个字为什么能成为一个词,是因为这两个字经常“扎堆”出现,而且这个“堆”只有它们俩。这就告诉我们,特征的聚合是因为它们有聚类倾向,所以Capsule把聚类算法融入到模型中。
要注意,我们以前所说的聚类,都是指样本间的聚类,比如将MNIST的图片自动聚类成10个类别,或者将Word2Vec训练而来的词向量聚类成若干类,聚类的对象就是一个样本(输入)。而Capsule则设想将输入本身表示为若干个特征向量,然后对这些向量进行聚类(特征间的聚类),得到若干中心向量,接着再对这些中心向量聚类,层层递进,从而完成层层抽象的过程。Capsule 是一种特征间的聚类。
现在问题就来了。既然是聚类,是按照什么方法来聚类的呢?然后又是怎么根据这个聚类方法来导出那个神奇的Dynamic Routing的呢?后面我们会从K-Means出发来寻根问底,现在让我们先把主要思路讲完。
特征显著性#
通过特征的组合可以得到上层特征,那如何对比特征的强弱程度呢?Capsule的答案是:模长。这就好比在茫茫向量如何找出“突出”的那个?只需要看看谁更高就行了。因此通过特征向量的模长来衡量它自己的“突出程度”,显然也是比较自然的选择。此外,一个有界的度量也是我们希望的,因此我们对特征向量做一个压缩:
我觉得是利用 squash 函数替代 sigmoid 激活;另外,为了突出模长的这一含义,需要同时考虑类内向量的数目、每个类内向量本身的模长。
图3:Capsule通过特征向量的聚类,来刻画特征的组合特性
让我们对比下 CNN+Max pooling 和Capsule,看看Capsule是如何同时体现Invariance和Equivariance特性的:
Invariance: 不同的输入,保证输出不变,例如分类问题。 Equivariance:不同的输入,输出也不同。但是对于任务,知道该忽略哪一些不同。

动态路由#

注意到上上图的蓝框公式,为了求vj需要求softmax,可是为了求softmax又需要知道_ _vj,这不是个鸡生蛋、蛋生鸡的问题了吗?这时候就要上“主菜”了,即“动态路由”(Dynamic Routing),它能够根据自身的特性来更新(部分)参数,从而初步达到了Hinton的放弃梯度下降的目标。
按照第一部分,我们说Capsule中每一层是通过特征间聚类来完成特征的组合与抽象,聚类需要反复迭代,是一个隐式的过程。我们需要为每一层找到光滑的、显式的表达式 才能完成模型的训练。动态路由就是通过迭代来写出这个(近似的)显式表达式的过程,图示如下:
才能完成模型的训练。动态路由就是通过迭代来写出这个(近似的)显式表达式的过程,图示如下: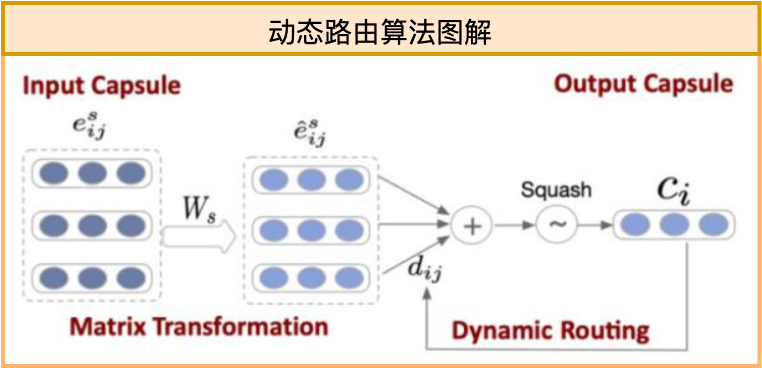
对应伪码为:
改进的动态路由算法如下:
基本步骤讲解
假设Capsule的输入特征分别为u_1,u2,…,un,然后下一层的特征向量就是v1,v2,…,v_k,它就是前一层n个向量聚为k类的聚类中心,聚类的度量是前面的归一化内积,于是我们就可以写出迭代过程:
这个版本是容易理解,但由于存在argmax这个操作,我们用不了梯度下降,而梯度下降是目前求模型其他参数的唯一方法。为了解决这个问题,我们只好不取K→+∞的极限,取一个常数K>0,然后将算法变为
然而这样又新引入了一个参数K,咋看上去K太大了就梯度消失,K太小了就不够准确,很难确定。不过后面我们将会看到,直接让K=1即可,因为K=1的解空间已经包含了任意K的解。最终我们可以得到
其中,最明显的差别是在迭代过程中用_v_j/‖_v_j‖替换了squash(_v_j),仅在最后输出时才进行squash。
给每个类都配一个变换矩阵_W_j,用来分辨不同的类,这时候动态路由变成了:
注意:vj是作为输入ui的某种聚类中心出现的,而从不同角度看输入,得到的聚类结果显然是不一样的。那么为了实现“多角度看特征”,于是可以在每个胶囊传入下一个胶囊之前,都要先乘上一个矩阵做变换!
补充:Capsule 实现细节#
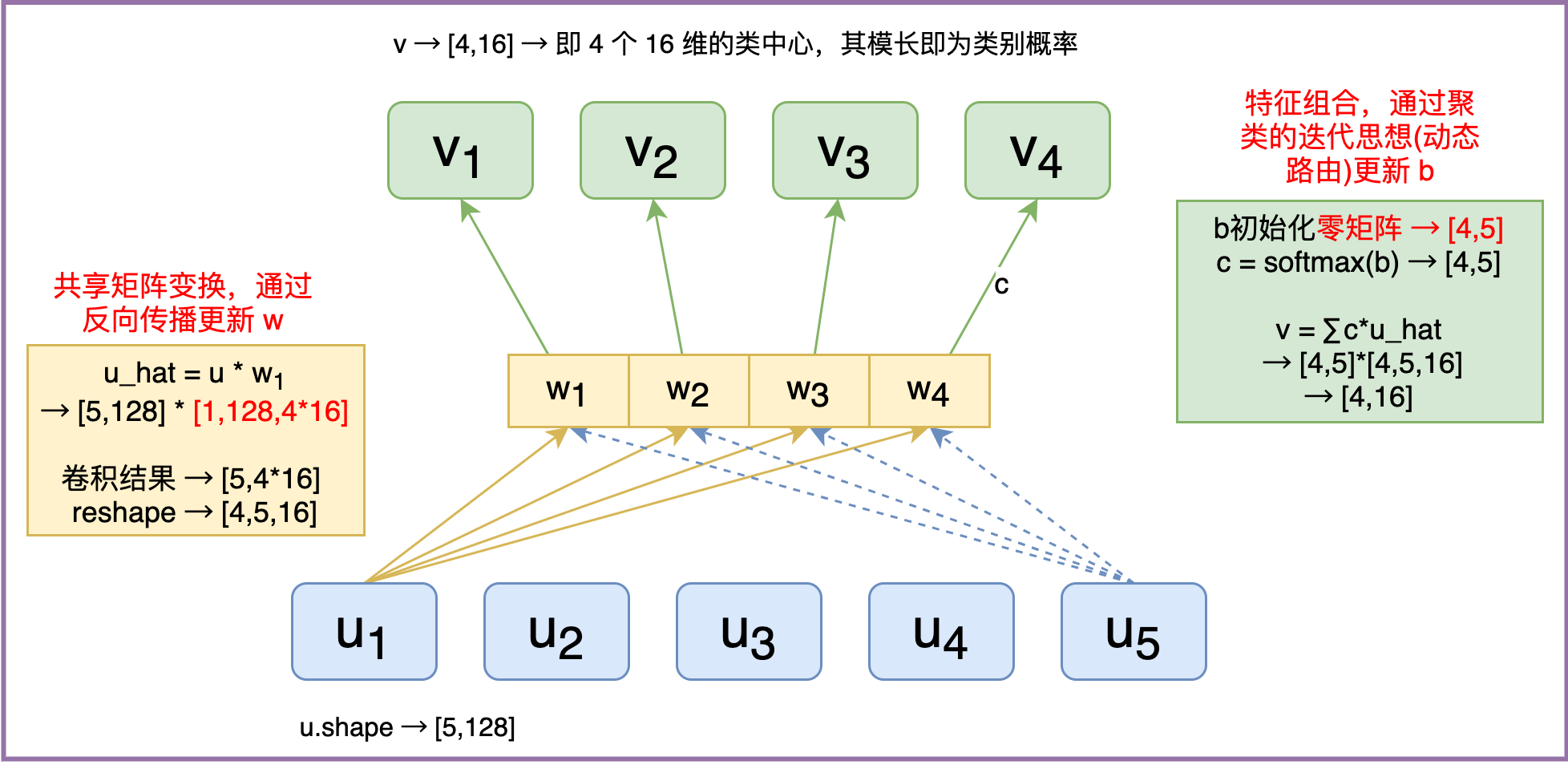
- Capsule实现的细节
- 通过 Dense 层完成矩阵变换,实现“多角度看特征”
- 权值共享版的Capsule。对于固定的上层胶囊j,它与所有的底层胶囊的连接的变换矩阵是共用的 W_ji≡W_j
- 迭代算法的几步(论文中是3步),被加入到模型中,从形式上来看,就是往模型中添加了三层罢了,最后构建一个loss来反向传播。

若有收获,就点个赞吧
0 人点赞
