本文总结了苏神多篇 seq2seq 相关的博客内容,感谢苏神!
BERT+Seq2Seq → UNILM
苏剑林. (May. 18, 2020). 《鱼与熊掌兼得:融合检索和生成的SimBERT模型 》[Blog post]. Retrieved from https://kexue.fm/archives/7427
将Bert与Seq2Seq结合的比较知名的工作有两个:MASS和UNILM,两者都是微软的工作。其中,真正有意思的是UNILM,它提供了一种很优雅的方式,能够**让我们直接用单个Bert模型就可以做Seq2Seq任务,而不用区分encoder和decoder**。而实现这一点几乎不费吹灰之力——只需要一个特别的Mask。
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的。它将双向语言模型、单向语言模型、Seq2Seq 语言模型结合进行多任务预训练。 
UniLM的核心是通过特殊的Attention Mask来赋予BERT模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP]。经过这样转化之后,最简单的方案就是训练一个语言模型,然后输入“[CLS] 你 想 吃 啥 [SEP]”来逐字预测“白 切 鸡”,直到出现“[SEP]”为止,即如下面的左图的Mask矩阵:
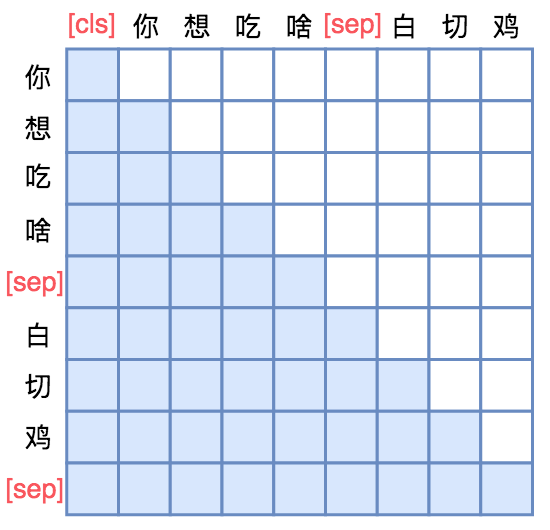 用单向语言模型的方式做Seq2Seq 行代表着输出,列代表着输入;白色方格代表0,蓝色方格代表 1 |
 设计更适合的Mask做Seq2Seq |
|---|---|
不过左图只是最朴素的方案,它把“你想吃啥”也加入了预测范围了(导致它这部分的Attention是单向的,即对应部分的Mask矩阵是下三角),事实上这是不必要的,属于额外的约束。真正要预测的只是“白切鸡”这部分,所以我们可以把“你想吃啥”这部分的Mask去掉,得到上面的右图的Mask。
这样一来,输入部分的Attention是双向的,输出部分的Attention是单向,从而允许递归地预测白 切 鸡 [SEP]这几个token,所以它具备文本生成能力。这便是UNILM里边提供的用单个Bert模型就可以完成Seq2Seq任务的思路,只要添加上述右边形状的Mask,而不需要修改模型架构,并且还可以直接沿用Bert的 Masked Language Model 预训练权重,收敛更快。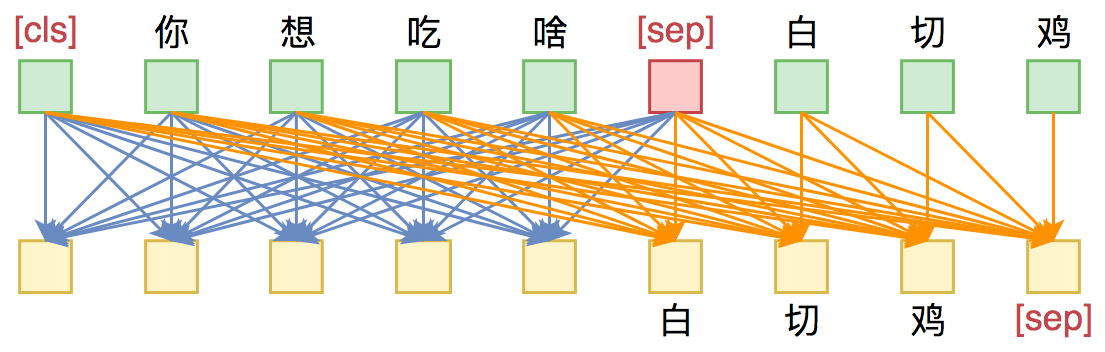
UNILM做Seq2Seq模型图示
输入部分内部可做双向Attention,输出部分只做单向Attention
Seq2Seq只能说明UniLM具有NLG的能力,那前面为什么说它同时具备NLU和NLG能力呢?因为UniLM特殊的Attention Mask,所以[CLS] 你 想 吃 啥 [SEP]这6个token只在它们之间相互做Attention,而跟白 切 鸡 [SEP]完全没关系,这就意味着,尽管后面拼接了白 切 鸡 [SEP],但这不会影响到前6个编码向量。再说明白一点,那就是前6个编码向量等价于只有[CLS] 你 想 吃 啥 [SEP]时的编码结果,如果[CLS]的向量代表着句向量,那么它就是你 想 吃 啥的句向量,而不是加上白 切 鸡后的句向量。
由于这个特性,UniLM在输入的时候也随机加入一些[MASK],这样输入部分就可以做MLM任务,输出部分就可以做Seq2Seq任务,MLM增强了NLU能力,而Seq2Seq增强了NLG能力,一举两得。
BERT+UniLM+对比学习→SimBERT
SimBERT属于有监督训练,训练语料是自行收集到的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后前面也提到过[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,即相似样本之间为正样本,batch内所有的非相似样本都当作负样本。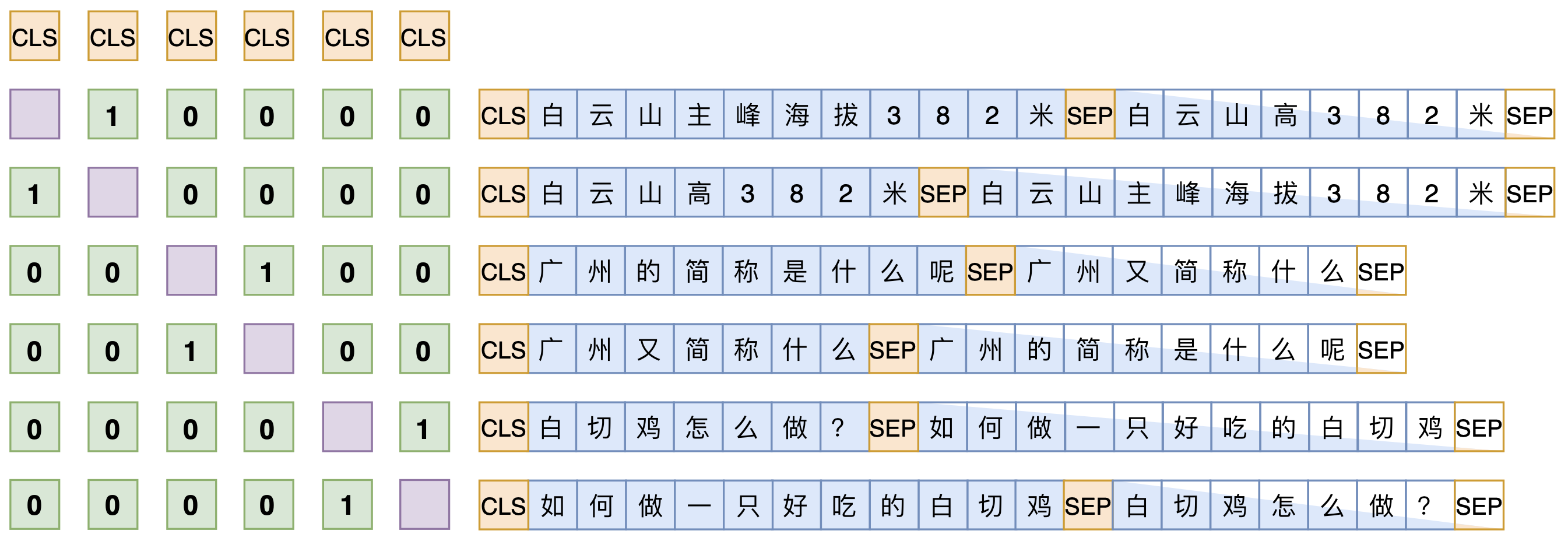
SimBERT训练方式示意图
RoFormer+UniLM+对比学习+BART+蒸馏→RoFormer-Sim(SimBERTv2)
RoFormer-Sim是SimBERT的升级版,除了基础架构换成了RoFormer外,RoFormer-Sim用到了更多的训练数据,更大的batch_size和maxlen….
- 在生成方面:为了增强模型的生成能力,RoFormer-Sim随机地将输入句子的部分token替换为[MASK],这种预训练方法首先由BART提出。而苏等.et al跟BART的区别在于:BART是“输入带噪声的句子,输出原句子”,RoFormer-Sim是“输入带噪声的句子,输出原句子的一个相似句”,理论上更难。
- 在检索方面:在RoFormer-Sim训练完之后,进一步通过蒸馏的方式把SimBERT的检索效果转移到RoFormer-Sim上去,从而使得RoFormer-Sim的检索效果基本持平甚至优于SimBERT。
BERT+UniLM + 前缀树 → Seq2Seq检索
Seq2Seq要是“溢出”(解码出了数据库不存在的句子)了怎么办?这时该前缀树上场了,我们可以利用前缀树约束解码过程,保证生成的结果在数据库中。
前缀解码#
现在我们来细说一下利用前缀树来约束解码的过程,看一下它是如何保证输出结果在数据库中的。我们假设数据库有如下几句话:
明月几时有明天会更好明天下雨明天下午开会明天下午放假明年见今夕是何年今天去哪里玩
那么我们将用如下的前缀树来存储这些句子:
前缀树示意图:本质上是序列的一种压缩表示
其实就是从左往右地把相同位置的相同token聚合起来,树上的每一条完整路径(以[BOS]开头、[EOS]结尾)都代表数据库中的一个句子。之所以叫“前缀树”,是因为利用这种树状结构,我们可以很快地查找到以某个前缀开头的字/句有哪些。比如从上图中我们可以看到,第一个字只可能是“明”或“今”,“明”后面只能接“月”、“天”或“年”,“明天”后面只能接“会”或“下”,等等。
有了前缀树,我们约束Seq2Seq解码就不困难了,比如第一个字只能是“明”或“今”,那么在预测第一个字的时候,我们可以把模型预测其他字的概率都置零,这样模型只可能从这两个字中二选一;如果已经确定了第一个字,比如“明”,那么我们在预测第二个字的时候,同样可以将“月”、“天”或“年”以外的字的概率都置零,这样模型只可能从这三个字中选一个,结果必然是“明月”、“明天”、“明年”之一;依此类推,通过将不在前缀树上的候选token置零,保证解码过程只走前缀树的分支,而且必须走到最后,这样解码出来的结果必然是数据库中已有的句子。
在Python中,实现前缀树比较简单的方案就是利用字典结构来实现嵌套,具体例子可以参考后面的 KgCLUE 评测的 baseline 代码:https://github.com/bojone/KgCLUE-bert4keras
“Seq2Seq+trie”用于检索有哪些优势?
常规的检索系统的流程为:
1、训练句子编码模型,这通常包含复杂的负样本构建流程,负样本质量直接影响到最终效果;2、将每个句子编码为向量,存到诸如Faiss的向量检索库中,这一步通常需要消耗相当大的空间;3、将查询句子编码为向量,然后进行检索,返回Topk结果及其相似度。
相比之下,“Seq2Seq”的优势在于:
1、训练Seq2Seq模型只需要输入和目标,这也就是说我们只需要正样本,免除了构建负样本的烦恼,或者说它是将所有其他句子都当成负样本了;2、Seq2Seq是直接解码出目标句子,省去了句向量的储存和检索, 同时前缀树所需要的储存空间要比稠密的检索向量要少得多;3、Seq2Seq包含了目标句子与输入句子之间Token级别的交互,理论上比基于内积的向量检索能做到更精细的对比,从而有更好的检索效果。
实现思路
具体来说,我们用UNILM方案来训练一个Seq2Seq模型。将用户上下文 query 当作Seq2Seq的输入,将坐席客服回复(type=out)用[SEP]连接起来作为目标;推理/解码的时候,我们先把所有的坐席回复(即答案)建立成前缀树,然后按照前缀树进行 beam search 解码,就保证了解码结果必然落到话术库中,从而能够合理地输出结果。详细的前缀解码步骤前面已经介绍过了,这里就不再细说。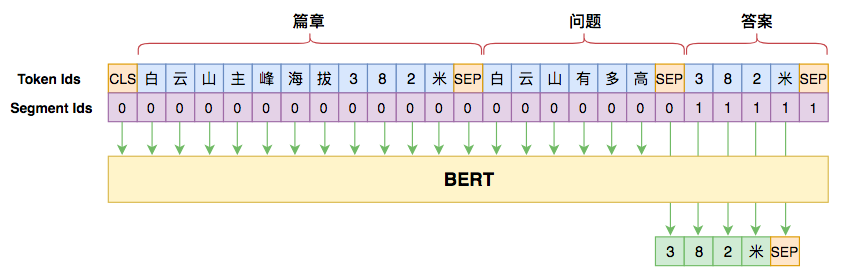
Seq2Seq模型:Roberta / UER / RoFormer+UniLM。RoFormer-Sim-FT模型,它是利用UniLM模型预训练过的相似问生成模型,经过对比,用RoFormer-Sim-FT相比直接用RoFormer,效果至少提升2个百分点。这也说明相似问生成是该方案的一种有效的预训练方式。
一些缺点#
- 训练时的Exposure Bias问题
- 解码时Beam Search的贪心问题
- “生成”过程一旦遇到生僻字被识别为[UNK],那么大概率就会失败了,尤其是如果S的第一个字就是[UNK],那么几乎都会失败,所以如何更好地解决[UNK]问题,是一个值得研究的问题。
- “Seq2Seq+前缀树”或许可以在评测指标上取得不错的效果,但它对于工程来说,有一个不大有好的特点,就是修正bad case会变得比较困难,因为传统方法修正bad case,你只需要不断加样本就行了,而“Seq2Seq+前缀树”则需要你修改解码过程,这通常困难得多。
Keras 代码参考#
自动生成新闻标题:
- 80多万篇新闻的语料
- 以字为基本单位,并且引入了4个额外标记,分别代表mask、unk、start、end
- encoder使用双层双向LSTM,decoder使用双层单向LSTM
- 代码实现:https://github.com/bojone/seq2seq/blob/master/seq2seq.py
自动生成新闻标题-升级版:
- THUCNews的原始数据集
- 以字为基本单位,并且引入了4个额外标记,分别代表mask、unk、start、end
- 以 UniLM 为基础架构,训练一个Seq2Seq模型
- 代码实现:task_seq2seq_autotitle.py
- base 版本:RoBERTa-wwm-ext-base,优化器是Adam,学习率是2e-5,batch_size=32,训练25个epoch
- large 版本:腾讯UER-PyTorch / 腾讯UER-Tensorflow(提取码l0k6),优化器是Adam,学习率是2e-5,batch_size=16,大概需要训练15个epoch
搭建模型,就只有寥寥几行:
model = build_transformer_model(config_path,checkpoint_path,application='unilm',keep_tokens=keep_tokens)model.summary()y_in = model.input[0][:, 1:] # 目标tokensy_mask = model.input[1][:, 1:]y = model.output[:, :-1] # 预测tokens,预测与目标错开一位# 交叉熵作为loss,并mask掉输入部分的预测cross_entropy = K.sparse_categorical_crossentropy(y_in, y)cross_entropy = K.sum(cross_entropy * y_mask) / K.sum(y_mask)
注意build_transformer_model中只要设置application=’unilm’,就会采用UNILM的思路自动加载Bert的MLM预训练权重,并且传入对应的Mask,剩下就只需要把loss写好就行了。另外还有一个keep_tokens,这个是用来精简Embedding层用的,对于中文Bert来说,总的tokens大概有2万个,这意味着最后预测生成的token时是一个2万分类问题。但事实上有接近一半的tokens都不会分出来(理论上都不会),因此这2万分类浪费了一些计算量。于是这里提供了一个选项,我们可以自行维护一个token表,然后传入对应的id,只保留这部分token,这样就可以降低计算量了(精简后一般只是原来的一半,甚至更少)。
参考
√玩转Keras之seq2seq自动生成标题
√从语言模型到Seq2Seq:Transformer如戏,全靠Mask
万能的seq2seq:基于seq2seq的阅读理解问答
√Seq2Seq中Exposure Bias现象的浅析与对策
√TeaForN:让Teacher Forcing更有“远见”一些
如何应对Seq2Seq中的“根本停不下来”问题?
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
√Seq2Seq+前缀树:检索任务新范式(以KgCLUE为例)

若有收获,就点个赞吧
0 人点赞
