layout: post
title: 正则表达式
subtitle: 正则表达式
date: 2019-09-04
author: NSX
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- 技术
- 教程
过一遍《A Visual Guide to Regular Expression》正则的基础知识,基本可以解决日常95%以上的问题了!
什么是正则表达式?
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
验证一个用户名的示例:
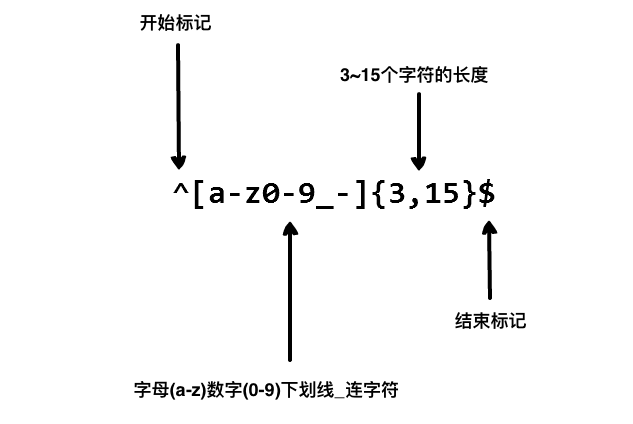
Python 正则表达式 re
Tips: 一般在 pattern 的 “” 前面需要加上一个 r 用来表示这是正则表达式, 而不是普通字符串.
re 模块的一般使用步骤如下:
- 使用 compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象
pattern = re.compile(r'\d+')
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象)
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
re 模块提供了不少有用的函数,用以匹配字符串:
| 模块 | 描述 | |
|---|---|---|
match() |
# # 指定字符串区间 m = pattern.match(text, 3, 10) >>> m.group(0) # ‘12’ >>> m.groups() # >>> m.span(0) # (3, 5) |
从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none |
search() |
m = pattern.search(text) m.group() |
扫描整个字符串并返回第一个成功的匹配 |
findall() |
result2 = pattern.findall(text, 0, 10) | 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表 |
finditer() |
result_iter1 = pattern.finditer(‘hello 123456 789’) for m1 in result_iter1: # m1 是 Match 对象 |
| 在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回 |
| split() | pattern.split(text) | 按照能够匹配的子串将字符串分割后返回列表 |
| sub() | pattern.sub(text, new_text) | 替换字符串中的匹配项 |
基础知识
元字符
正则表达式主要依赖于元字符.
元字符不代表他们本身的字面意思, 他们都有特殊的含义. 一些元字符写在方括号中的时候有一些特殊的意思. 以下是一些元字符的介绍:
| 元字符 | 描述 |
|---|---|
. |
句号匹配任意单个字符除了换行符. |
[ ] |
字符种类. 匹配方括号内的任意字符. |
[^ ] |
否定 的字符种类. 匹配除了方括号里的任意字符 |
* |
匹配==>=0个==重复的在*号之前的字符. |
(xyz) |
字符集, 匹配与 xyz 完全相等的字符串. |
| |
或 运算符,匹配符号前或后的字符. |
\\ |
转义字符,用于匹配一些保留的字符[ ] ( ) { } . * + ? ^ $ |
量词
| 元字符 | 描述 |
|---|---|
? |
匹配前面的字符0次或1次 |
* |
匹配前面的字符0次或多次 |
+ |
匹配前面的字符1次或者多次 |
{m} |
匹配前面表达式m次 |
{m,} |
匹配前面表达式至少m次 |
{,n} |
匹配前面的正则表达式最多n次 |
{m,n} |
匹配前面的正则表达式至少m次,最多n次 |
PS: 以上量词都是贪婪模式,会尽可能多的匹配,如果要改为非贪婪模式,通过在量词后面跟随一个?来实现(惰性匹配)
断言与标记
断言不会匹配任何文本,只是对断言所在的文本施加某些约束
| 字符 | 描述 |
|---|---|
^ |
在起始处匹配 |
$ |
在结尾处匹配 |
() |
表示捕获分组 ,()会把每个分组里的匹配的值保存起来 |
(?:str) |
表示非捕获分组 ,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来 |
(?=str) |
正前瞻,示例:exp1(?=exp2),即exp1后面的内容要匹配exp2 |
(?!str) |
负前瞻,示例:exp1(?!exp2),即exp1后面的内容不能匹配exp2 |
(?<=str) |
正回顾,示例:(?<=exp2)exp1,即 exp1前面的内容要匹配exp2 |
(?<!str) |
负回顾,示例:(?<!exp2)exp1,即 exp1前面的内容不能匹配exp2 |
举例:
"中国人".replace(/(?<=中国)人/, "rr") // 匹配中国人中的人,将其替换为rr,结果为 中国rr"法国人".replace(/(?<=中国)人/, "rr") // 结果为 法国人,因为人前面不是中国,所以无法匹配到
条件匹配
| 字符 | 描述 |
|---|---|
(?(id)yes_exp|no_exp) |
id里的子表达式如果匹配到内容,则匹配yes_exp,否则匹配no_exp |
简写字符集
正则表达式提供一些常用的字符集简写. 如下:
| 简写 | 描述 |
|---|---|
. |
除换行符外的所有字符 |
\\w |
匹配所有字母数字, 等同于 [a-zA-Z0-9_] |
\\W |
匹配所有非字母数字, 即符号, 等同于: [^\\w] |
\\d |
匹配数字: [0-9] |
\\D |
匹配非数字: [^\\d] |
\\s |
匹配所有空格字符, 等同于: [\\t\\n\\f\\r\\p{Z}] |
\\S |
匹配所有非空格字符: [^\\s] |
\\f |
匹配一个换页符 |
\\n |
匹配一个换行符 |
\\r |
匹配一个回车符 |
\\t |
匹配一个制表符 |
\\v |
匹配一个垂直制表符 |
\\p |
匹配 CR/LF (等同于 \\r\\n),用来匹配 DOS 行终止符 |
正则表达式小抄
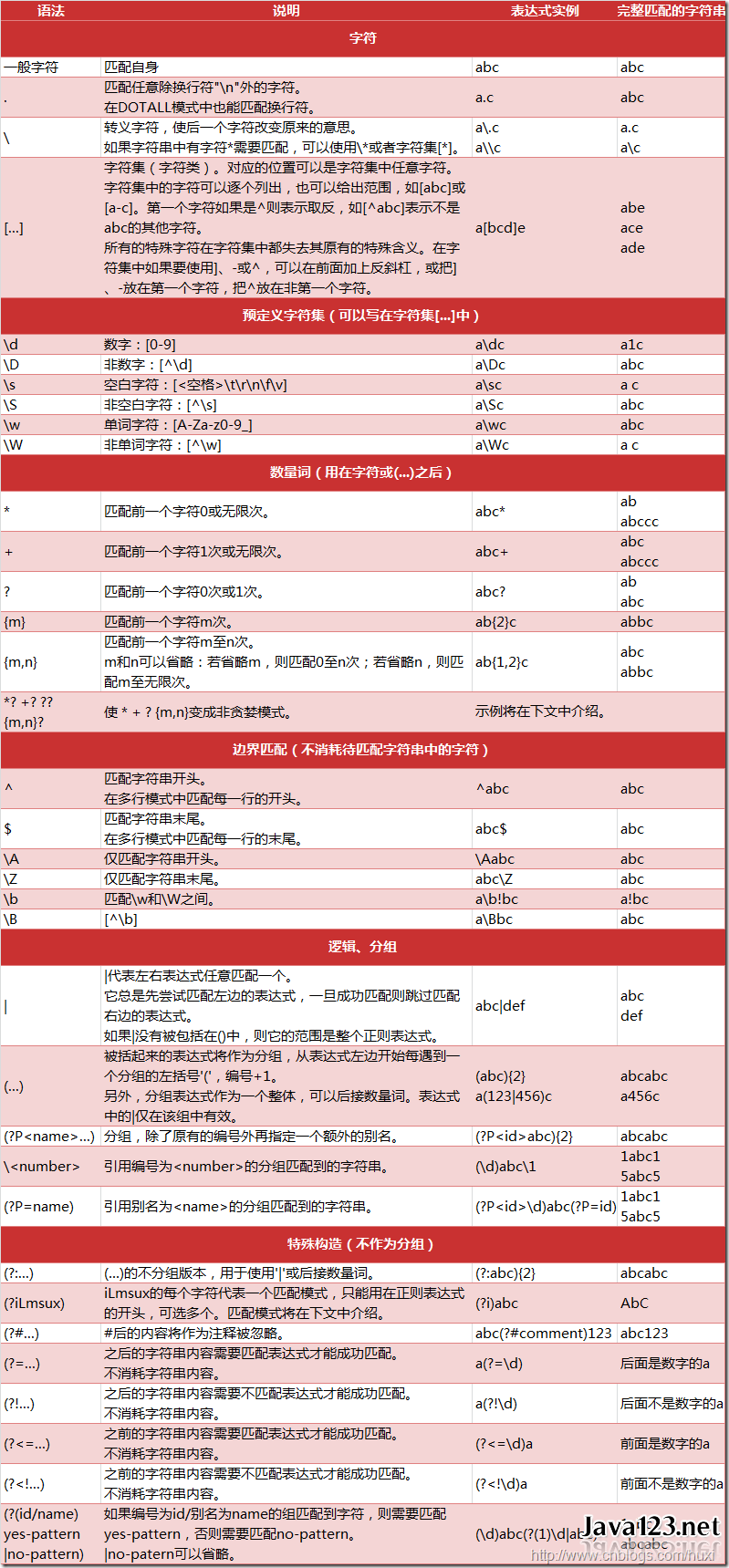
常用正则
匹配中文
[\u4e00-\u9fa5]匹配英文字母
[a-zA-Z]- 数字:[0-9]
- 匹配中文,英文字母和数字及下划线,同时判断输入长度:
[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10} - 只含有汉字、数字、字母、下划线,下划线位置不限:
^[a-zA-Z0-9_\u4e00-\u9fa5]+$ - 由数字、26个英文字母或者下划线组成的字符串
^\w+$ - 不以某字符串开头
^(?!str).*
- 不以某字符串结尾
.*(?<!str)$
- 匹配时间
# 23:59regex = /^([01][0-9]|[2][0-3]):[0-5][0-9]$/;
- 匹配日期(年月日时分秒)
def time_ext(text):# 仅针对 年月日时分text = re.sub(r"(2\d{3}[-\.]\d{1,2}[-\.]\d{1,2}\s[0-2]?[0-9]:[0-5][0-9]:[0-5][0-9])", "[TIME]", text)text = re.sub(r"(2\d{3}[-\.]\d{1,2}[-\.]\d{1,2}\s[0-2]?[0-9]:[0-5][0-9])", "[TIME]", text)text = re.sub(r"(2\d{3}[-\.]\d{1,2}[-\.]\d{1,2})", "[TIME]", text)text = re.sub(r"\d+[年/-]\d{1,2}[月/-]\d{1,2}[日号][0-2]?[0-9]:[0-5][0-9]:[0-5][0-9]", '[TIME]', text)text = re.sub(r"\d+[年/-]\d{1,2}[月/-]\d{1,2}[日号][0-2]?[0-9]:[0-5][0-9]", '[TIME]', text)text = re.sub(r"\d+[年/-]\d{1,2}[月/-]\d{1,2}[日号]?", '[TIME]', text)return text
- 匹配邮箱地址
email_pattern = '^[*#\u4e00-\u9fa5 a-zA-Z0-9_.-]+@[a-zA-Z0-9-]+(\.[a-zA-Z0-9-]+)*\.[a-zA-Z0-9]{2,6}$'
- 匹配字符串中的电话号码 (假设手机号为1开头的11为数字,要求手机号前后不为数字)
假设待提取的字符串:str=” 15838477645dfdfdf15887988765dfdf1157990087651fd157385367891fdf15826789876qqq15838545678a”# 手机号码替换为[PHONE]pattern = r"(?:^|[^\d])((?:\+?86)?1(?:3\d{3}|5[^4\D]\d{2}|8\d{3}|7(?:[01356789]\d{2}|4(?:0\d|1[0-2]|9\d))|9[189]\d{2}|6[567]\d{2}|4(?:[14]0\d{1}|[68]\d{2}|[579]\d{2}))\d{6})(?:$|[^\d])"phone_list = re.compile(pattern).findall(text)for _ in phone_list:text = re.sub(_, '[PHONE]', text)
- 匹配身份证号
IDCards_pattern = r'^([1-9]\d{5}[12]\d{3}(0[1-9]|1[012])(0[1-9]|[12][0-9]|3[01])\d{3}[0-9xX])$'
- 匹配网页链接
pattern = r"http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,]|(?:%[0-9a-fA-F][0-9a-fA-F]))+|[a-zA-Z]+.\w+\.+[a-zA-Z0-9\/_]+"
- 匹配图片链接
pattern = r"(<img src=(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*,])+)"
参考
- 0-9 ↩︎

若有收获,就点个赞吧
0 人点赞
