本文翻译自Gaurav Bhatt在 http://deeplearn-ai.com 发表的NEURAL TENSOR NETWORK: EXPLORING RELATIONS AMONG TEXT ENTITIES。
在这篇文章中,我将介绍神经张量网络 (Neural Tensor Network, NTN),并使用 NTN 预测新的三元组关系。
用代码直接跳到GitHub仓库
对关系进行推理的神经模型
NTN 旨在找到实体 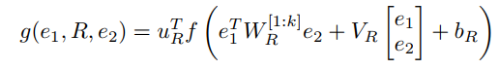
其中是 标准非线性的单元应用,
标准非线性的单元应用, 是张量,双线性张量积
是张量,双线性张量积 产生向量
产生向量 ,其中每个条目张量的一个切片
,其中每个条目张量的一个切片 计算:
计算: 。其它参数为关系R是一个神经网络的标准形式:
。其它参数为关系R是一个神经网络的标准形式: 和
和 .
.
神经张量层图示

NTN 使用张量变量 对两个实体之间的关系进行乘法建模,如上所示,NTN 是简单神经层的扩展,添加了这些张量变量。
对两个实体之间的关系进行乘法建模,如上所示,NTN 是简单神经层的扩展,添加了这些张量变量。
TRAINING OBJECTIVES
NTN 使用对比最大边距目标函数进行训练。给定训练样本中的三元组为 , 负样本是通过随机替换第二个实体来创建的,其中 j 是随机索引。最后,目标函数定义为
, 负样本是通过随机替换第二个实体来创建的,其中 j 是随机索引。最后,目标函数定义为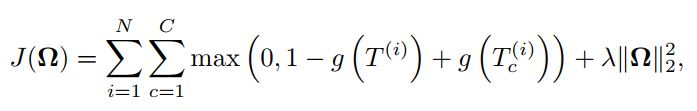
其中, 是正则化参数。
是正则化参数。
Implementation Details
现在,我们已经看到了 NTN 的工作原理,是时候深入研究实施了。这里要考虑的一个重要点是,每个给定的关系都有自己的一组张量参数。让我快速概述一下我们需要在 Keras 的帮助下做什么。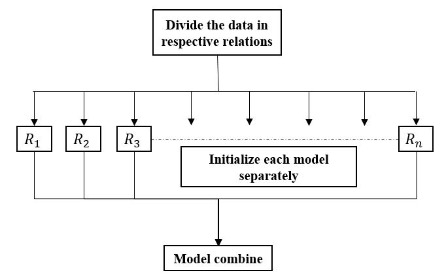
每个关系都归因于一个单独的 Keras 模型,该模型还添加了张量参数。现在,假设在模型初始化和组合之间添加了张量层。在后面的帖子中,我将解释张量层的构造。从上图中,您可以轻松得出结论,我们需要以某种方式处理训练数据,以便可以同时将其传递给所有单独的模型。我们想要的是只更新那些与特定关系相对应的张量参数。然而,Keras 不允许我们在更新单独的模型的同时留下其余部分。因此,我们需要将数据划分为不同的关系。每个训练样本将由所有关系的一个实例组成,即每个关系有一对实体。
实现 NTN 层
让我们从实现神经张量层开始。本节的先决条件是在 Keras 中编写自定义层。我们首先使用参数 inp_size、out_size 和激活来初始化 NTN 类。 inp_size 是输入变量的形状,在我们的例子中是实体; out_size 是张量参数的个数(k),activation 是要使用的激活函数(默认为 tanh)
from ntn_input import *from keras import activationsclass ntn_layer(Layer):def __init__(self, inp_size, out_size, activation='tanh', **kwargs):super(ntn_layer, self).__init__(**kwargs)self.k = out_sizeself.d = inp_sizeself.activation = activations.get(activation)self.test_out = 0
维度的命名保持不变,即 k 对应于每个关系的张量参数的数量,d 是实体的形状。
现在,我们需要初始化张量层参数。为了更好地理解我们在这里做什么,看一下张量网络的下图。
我们初始化四个张量的参数,即 W、V、b 和 U,如下所示:
def build(self,input_shape):self.W = self.add_weight(name='w',shape=(self.d, self.d, self.k), initializer='glorot_uniform', trainable=True)self.V = self.add_weight(name='v', shape=(self.k, self.d*2), initializer='glorot_uniform', trainable=True)self.b = self.add_weight(name='b', shape=(self.k,), initializer='zeros', trainable=True)self.U = self.add_weight(name='u', shape=(self.k,), initializer='glorot_uniform',trainable=True)super(ntn_layer, self).build(input_shape)
在这里,我们使用 glorot_uniform 采样初始化参数。在实践中,这种初始化比其他初始化产生更好的性能。add_weight 函数的另一个参数 - trainable,如果我们不想更新特定的可调参数,可以将其设置为 false。例如,我们可以将 W 参数设置为不可训练,并且 NTN 模型将表现得像一个简单的神经网络,如前所述。
一旦参数被初始化,是时候实现以下等式了: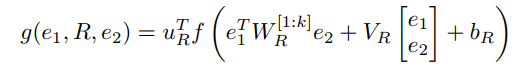
上面的等式给每个实体对打分。 如您所见,我们必须迭代 k 个张量参数(张量模型的切片)。 这是通过计算每次迭代的中间产品,最后聚合所有这些产品来完成的。 以下代码片段为您完成了这项工作。 请不要更改函数的名称,因为它们与 Keras API 一致。
def call(self ,x ,mask=None):e1=x[0] # entity 1e2=x[1] # entity 2batch_size = K.shape(e1)[0]V_out, h, mid_pro = [],[],[]for i in range(self.k): # computing the innner productsV_out = K.dot(self.V[i],K.concatenate([e1,e2]).T)temp = K.dot(e1,self.W[:,:,i])h = K.sum(temp*e2,axis=1)mid_pro.append(V_out+h+self.b[i])tensor_bi_product = K.concatenate(mid_pro,axis=0)tensor_bi_product = self.U*self.activation(K.reshape(tensor_bi_product,(self.k,batch_size))).Tself.test_out = K.shape(tensor_bi_product)return tensor_bi_product
最后,要完成 NTN 层的实现,我们必须添加以下函数
def compute_output_shape(self, input_shape):return (input_shape[0][0],self.k)
我们已经构建了 NTN 层,它可以像 Keras 中的任何其他神经层一样被调用。 让我们看看如何在真实数据集上使用 NTN 层。
数据集
如本文所述,我将使用 Wordbase 和 Freebase 数据集。 略…
建立模型
为了训练模型,我们需要定义对比最大边际损失函数。
def contrastive_loss(y_true, y_pred):margin = 1return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))
我们应该能够从 Keras 编译函数中调用这个自定义损失函数。
from ntn import *def build_model(num_relations):Input_x, Input_y = [], []for i in range(num_relations):Input_x.append(Input(shape=(dimx,)))Input_y.append(Input(shape=(dimy,)))ntn, score = [], [] # storing separate tensor parametersfor i in range(num_relations): # iterating through each slice 'k'ntn.append(ntn_layer(inp_size=dimx, out_size=4)([Input_x[i],Input_y[i]]))score.append(Dense(1,activation='sigmoid')(ntn[i]))all_inputs = [Input_x[i]for i in range(num_relations)]all_inputs.extend([Input_y[i]for i in range(num_relations)]) # aggregating all the modelsmodel = Model(all_inputs,score)model.compile(loss=contrastive_loss,optimizer='adam')return model
最后,我们需要聚合数据以训练模型
e, t, labels_train, labels_dev = aggregate(e1, e2, labels_train, t1, t2, labels_dev, num_relations)model.fit(e, labels_train, nb_epoch=10, batch_size=100, verbose=2)
此时您可以看到模型开始训练,并且每个单独模型的损失逐渐减少。 此外,为了计算知识库数据集上 NTN 的准确性,我们需要计算所有关系的成本,并选择得分最高的关系。 如论文所述,所达到的准确度接近 88%(平均)
参考
GauravBh1010tt/DeepLearn/neural tensor network-Github
神经张量网络:探索文本实体之间的关系

若有收获,就点个赞吧
0 人点赞
