前言
短语挖掘(Phrase Mining)的目的在于从大量的文本语料中提取出高质量的短语,是 NLP 领域中基础任务之一。短语挖掘主要解决专业领域的专业词典不足的问题,减少人工整理成本。挖掘出来的专业词汇主要用途有:
- 作为「领域词/新词」影响分词
- 作为多轮对话的词槽
- 作为句式触发器的词槽
一个高质量的短语应该满足高频性、一致性、以及完整性:
- 高频性:一个n-gram出现的频率越高(TF),且质量也高(IDF),那么其成为关键词的概率也越高;
- 一致性:用于评估候选短语n-gram中的单词的搭配是否合理,与此相对应的是凝固度,即一个字组合片段里面字与字之间的紧密程度
- 高质量的短语需要是一个完整的语义单元,一般来说,一个短语如果完整,那么其能够被独立运用的概率就越高,其独立使用时出现的前后上下文就越丰富。与此相对应的概念叫做自由度,即一个字组合片段能独立自由运用的程度。
短语抽取方法介绍
一、高频性与TFIDF的统计判定
在实现上,可以使用TF算法计算候选短语出现的频次加以过滤,也可以在此基础上使用TF-IDF、TextRank算法或者词性过滤规则,过滤文中出现的频率高但是不重要的词,如代词,副词,介词,助词等
二、一致性与PMI点间互信息的统计判定
1)思想
一致性,用于评估候选短语n-gram中的单词的搭配是否合理,与此相对应的是凝固度,即一个字组合片段里面字与字之间的紧密程度,例如“琉璃”、“榴莲”这样的词的凝固度就非常高,电影院的凝固度和合理性要比“的电影”要高。
不过,该方法存在一定的缺点,如果只看一致性,即凝固程度的话,会倾向于找出“巧克”、“俄罗”、“颜六色”、“柴可夫”等实际上是“半个词”的片段。
2)原理
在具体实现上,可以使用PMI点间互信息值来衡量,一个ngram短语的PMI点间互信息值越大成词的可能性越大:
举例说明:设定p(x)为文本片段x在整个语料中出现的概率,那么:
- “电影院”的凝合程度就是
p(电影院)与p(电)*p(影院)比值和p(电影院)与p(电影)*p(院)的比值中的较小值 - “的电影”的凝合程度则是
p(的电影)分别除以p(的)*p(电影)和p(的电)*p(影)所得的较小值
其中,有个实现的细节,即针对一个ngram,需要对其进行切分组合,然后分别计算组合中的PMI值,然后排序,例如,针对 ngram ’abcd’:
- 首先,把字组合切分成不同的组合对,拆成(‘a’, ‘bcd’), (‘ab’, ‘cd’), (‘abc’, ‘d’)
- 然后,计算每个组合对的凝固度:
_D(s1, s2)=P(s1s2)/(P(s1)P(s2))_- 最后,取这些组合对凝固度中最小的那个为整个字组合的凝固度。通常,我们会对概率取对数处理。
3)实现
def compute_mi(p1, p2, p12):return math.log2(p12) - math.log2(p1) - math.log2(p2)
开源实现:https://github.com/zhanzecheng/Chinese_segment_augment
三、完整性及左右信息熵的统计判定
1)思想
高质量的短语需要是一个完整的语义单元,如“巧克力“与“巧克”相比,完整性要更高。一般来说,一个短语如果完整,那么其能够被独立运用的概率就越高,其独立使用时出现的前后上下文就越丰富。
与此相对应的概念叫做自由度,即一个字组合片段能独立自由运用的程度。 比如“巧克力”里面的“巧克”的凝固度就很高,和“巧克力”一样高,但是它自由运用的程度几乎为零,所以“巧克”不能单独成词。
2)原理
在具体实现上,我们可以使用左右信息熵来进行实现,左右邻熵,描绘的是一个短语左右搭配的丰富度,一个好的短语左右搭配应该是非常丰富的,分别计算它的左邻居信息熵和右邻居信息熵,取其中较小的为该组合的自由度,自由度越大成词的可能性越大。
例如,援引文献5的论述,对于“吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮”,“葡萄”一词出现了四次,其中左邻字分别为{吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} 。信息熵计算如下:

根据上述公式计算,“葡萄”一词的左邻字的信息熵为:
“葡萄”一词的右邻字的信息熵为:
通过计算,可以发现“葡萄”一词的右邻字更加丰富一些。
3)实现
def compute_entropy(neighbours):if neighbours:right_sum = sum(neighbours)#TODO 计算改词的右领字熵,可以怎么优化呢?right_prob = map(lambda x:x/right_sum, neighbours)right_entropy = sum(map(lambda x:-(x)*math.log(x), right_prob))return right_entropyelse:return 0
与一致性类似,如果只看完整性即自由程度的话,则会把 “吃了一顿”、“看了一遍”、“睡了一晚”、“去了一趟”中的“了一”提取出来,因为它的左右邻字都太丰富了。因此,在最终实现的时候,通常都会综合考虑上面三个因素,然后分别设定阈值或者做得分的加和,得到一个整体的值,再进行阈值过滤,最终输出。
开源实现:https://github.com/zhanzecheng/Chinese_segment_augment
四、词性与构词模板的规则判定
上面列举的三种方法,都需要大量的文本进行统计,而且语料库越大,效果越好,但对于一些query或者短文本情况下,则并不奏效,因此,通常可以采用短语构词模板进行判定,将满足这种词性组合模式的短语过滤出来。
1)思想
词性模板规则判定的方法,其思想在于短语通常满足n+v,或者n+n,或a+n的模式,通过文本分词和词性标注,进行组合匹配,就可以输出。
2)原理与实现
通过jieba等开源工具进行分词和词性标注,可以得到一些有实际意义的词,但这些词分的粒度太细,可以进一步组合,例如,将连续的名词组合成新的NP短语;也可以使用standfordparser/corenlp进行浅层句子成分分析,
通过提取NP标签,可以直接提取出NP短语。
开源实现:https://github.com/liuhuanyong/EventTriplesExtraction
五、基于有监督标注分类评分的短语判定
在基于有监督的短语挖掘工作上,韩家炜老师团队逐步产出了系列具有代表性的工作,包括TopMine,SegPhrase、AutoPhrase,很具有启发性.
1、TopMine:频率模式挖掘+统计分析
TopMine,发表于《Scalable Topical Phrase Mining from Text Corpora》一文。
1)主要思想
该工作主要是对语料库文本的Topic进行挖掘,不同于以往采用Uni-gram的方法,而是将Topic 挖掘分成了两个步骤:通过Phrase Mining对文本进行分割;随后进行基于Phrase约束的Topic模型。
2)原理
首先,先进行Phrase挖掘,用到phrase本身的统计量以及phrase上下文信息。在统计量熵,直接使用频次作为过滤条件,生成所有的phrase候选,在上下文信息上,构造了一个类似PMI的指标,用来衡量合并之后的得分。
3)开源实现
https://github.com/anirudyd/topmine
2、SegPhrase:弱监督、高质量的 Phrase Mining
SegPhrase,发表于《Mining Quality Phrases from Massive Text Corpora》一文
1)思想
TopMine方法通常会产生低质量的主题短语,或者在中等大小的数据集上也会出现可伸缩性差的问题。SegPhrase是一种新的短语挖掘框架,将文档分为单词短语和多词短语,以及一个新的主题模型,该模型基于诱导文档划分,从而产生高质量的短语集合。
2)原理
根据用户需求生成常用短语候选,然后根据有关一致性和信息要求的特征来估计短语质量,并通过短语分段估计校正的频率,并将基于整流频率的基于细分的特征添加到短语质量分类器的特征集中,最后过滤低整流频率的短语,以满足后处理步骤的完整性要求。
3)开源实现
https://github.com/shangjingbo1226/SegPhrase
3、AutoPhrase:自动的 Phrase Mining
论文:Automated Phrase Mining from Massive Text Corpora 博客:Automated Phrase Mining from Massive Text Corpora 论文解读 代码:https://github.com/luozhouyang/AutoPhraseX
1)思想
该工作认为,一个理想的自动短语挖掘方法应该是独立于不同领域,并且只需要最少的人力或语言解析,因此提出了AutoPhrase框架,更深层次的避免了人工标注的问题。
2)原理
AutoPhrase框架选用了Robust Positive-Only Distant Training(强健正面的远程训练)以及POS-Guided Phrasal Segmentation(POS-Guided短语分割)两种策略。
- Robust Positive-Only Distant Training :使用 wiki 和 freebase 作为显眼数据,根据知识库中的相关数据构建 Positive Phrases,根据领域内的文本生成 Negative Phrases,构建分类器后根据预测的结果减少负标签带来的噪音问题。
- POS-Guided Phrasal Segmentation:使用 POS 词性标注的结果,引导短语分词,利用 POS 的浅层句法分析的结果优化 Phrase boundaries。
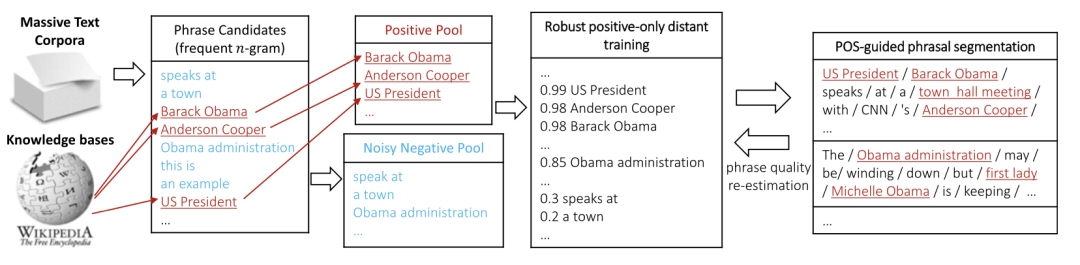
上图展示了整个流程:
1)利用已有的知识库(如Wikipedia)做远程监督训练
Step1: 根据输入语料和知识库构建训练样本
- 对语料进行n-gram,然后得到高频n-gram
- 对高频的n-gram,如果该n-gram在Wikipedia的词条中,该n-gram就作为正样本,反之,该n-gram就作为负样本
Step2: 负样本去躁、训练分类器
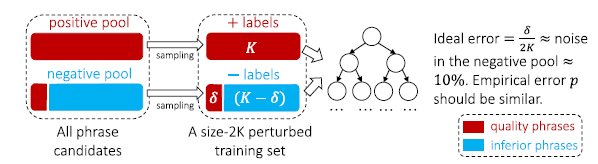
有的n-gram是关键短语,但是并不在Wikipedia中,但是在Step1中,我们把它作为负样本了,这种n-gram就成为了负样本中的噪音。解决方案:使用一个集成分类器来解决,这种方法最大程度上减轻噪声对训练的影响,论文中用的是随机森林
- 对每一个基本分类器,从positive pool 和 negative pool 各抽取 K 个样本,即2K个样本作为一个扰动数据集
- 在扰动数据集上用不经过裁剪的决策树进行训练,假设在扰动数据集上负样本的噪音个数为δ,只要不存在特征完全相同的正样本和负样本,模型在扰动数据集上能够取得100%准确率,由于δ是噪音,所以最理想的准确率是1-δ/2K(在论文中,δ/2K约等于10%,所以最佳准确率为90%,就是每个基分类器完全过拟合的情况下准确率是90%)
- 随机森林中的决策树判断比例作为分数(投票比例)
Step3: 对输入语料中的高频n-gram进行分类,得到n-gram是质量短语的评估score
2) POS-Guided短语分割
目的:利用词性信息来增加抽取的准确性
- Eg: 如果连续三个名词相连,那么很有可能是高质量短语,名词+动词大概率不是一个质量短语(主谓结构)
核心思想:根据词性进行分割,将文本划分成若干个短语(有点类似中文分词得意思,只不过分的是短语,因为前面我们得到的n-gram可能是一个不成词没有意义的序列)
- 输入:词性序列Ω、第一次质量短语评估的score
- 输出:根据词性分割的边界序列B
使用最大似然法:
在给定词性序列Ω 的情况下,每个片段是高质量短语的概率乘积是最大的,那么就是最优分割
3)短语质量评估score修正
经过POS-Guided分割之后,对短语质量进行第二次评估,修正第一次评估的score,选取修正后的score比较高的作为质量短语输出
个人实验记录
前提:业务来挖掘和维护知识中的领域实体词库及其常用说法,成本较高,不现实; 而通过观察发现,这些领域实体大多是一些NN和形容词/动词的组合,也即关键短语,且语料较少,所以采用上述方法四(浅层句法分析+短语构词模板)将满足条件的短语挖掘出来,使得这些短语不仅仅是若干零碎词汇,而是完整的实体。
实验1:关键短语+依存分析

具体步骤如下:
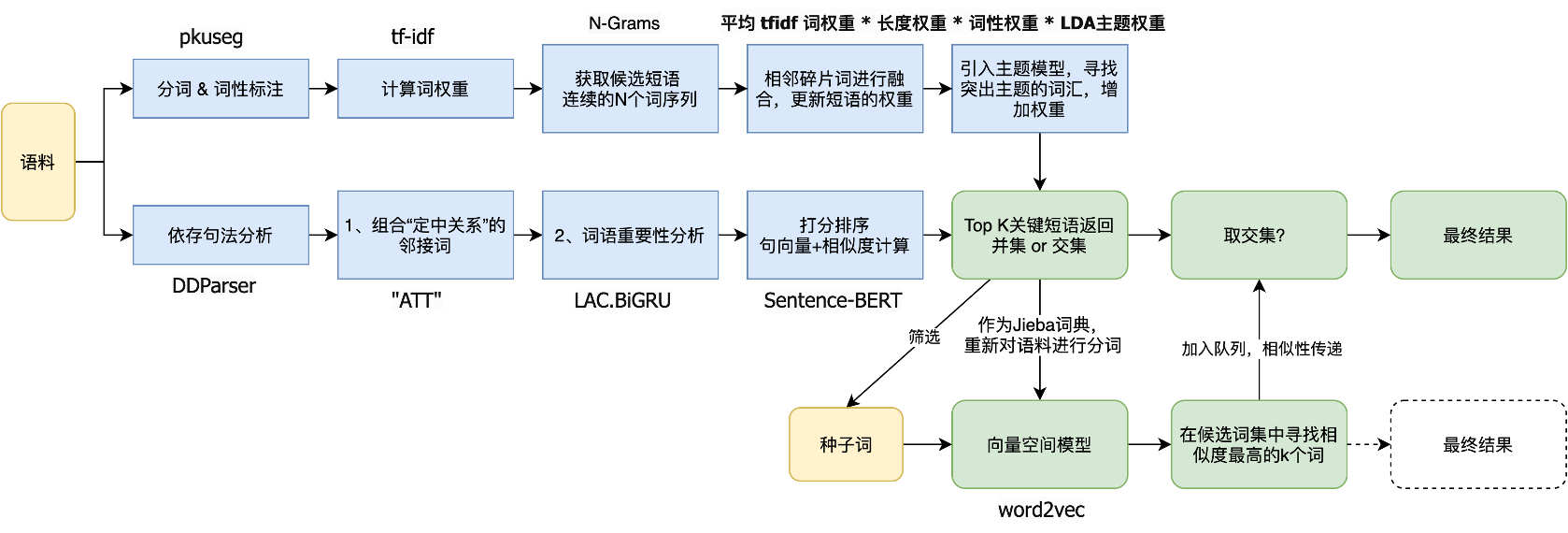
抽取关键词组,作为自定义词典使用 Principle of algorithm ckpe;
- 首先基于 pkuseg 工具做分词和词性标注;
- 再计算文本的 tfidf 词权重;
- 对分词后的 word_list 进行N-Gram(连续的N个字/词序列),针对每个candidate_phrase,通过一定规则,找到候选短语集合,以及其权重:
- 短语过滤(短语的 token 长度不超过 12…)
- 短语的权重更新 = 平均 tfidf 词权重 长度权重 词性权重 主题权重

> 主题权重:使用预训练好的 LDA 模型,计算文本的主题概率分布,以及每一个候选短语的主题概率分布,寻找突出主题的词汇,增加权重.
- 按重要程度进行排序,选取 top_k 个返回,作为用户自定义词典!
引入依存句法分析
- DDParser 工具,得到依存树,将其中存在定中关系的邻接词组合成候选短语span;
- 若上述条件不存在,则进行LAC词语重要性分析,取第一个符合条件的名词(im=3)
词语重要性分析:词重要性是直接使用BiGRU的模型,对于每个词进行重要性分类。其使用词向量+标签向量(LAC的预测结果)作为特征输入,简洁有效;
打分
计算候选关键短语与文档本身的相似度(Cosine Similarity),判断这个ngram是否可能作为一个关键成分短语(similarity > 0.9)
- 领域短语抽取结果如下:

整体抽取效果不错,badcase 也是仔细搜查出来的几个,大部分都比较符合要求!
句子:如何抵扣 App store 充值卡 ckpe的抽取结果为:[‘App’] ckpe + 依存树 的结果为: [‘App store充值卡’, ‘ store充值卡’]
实验1plus:关键短语+依存分析+种子词扩展
参考苏神在“电力专业领域词汇挖掘”比赛中实践的无监督领域词发现方法,对实验 1 进行了改进,如下:
实验2:autophrase
领域短语抽取结果如下:
分析:
- 效果不理想,缺少正例!
- 种子词汇获取(利用已有 tag_name)不充分,无外部知识库可用?
实验3:新词发现/词库构建 ✨
分享一次专业领域词汇的无监督挖掘-苏剑林 ✨ HarvestText: 领域自适应文本挖掘工具(新词发现、情感分析、实体链接等)√ 最小熵原理(二):“当机立断”之词库构建
一、利用基于最小熵原理的NLP库:nlp zero ,在train的基础上(统计字频和字对频率),计算互信息,通过互信息找出强相关的邻字,然后通过这些邻字实现粗糙的分词,从粗糙的分词结果中筛选出可能的词语。
. 《最小熵原理(二):“当机立断”之词库构建 》[Blog post]. Retrieved from https://kexue.fm/archives/5476")
二、给定两份语料,一份是目标语料,一份是公开较大规模的通用语料(如:wiki百科语料),分别对两份语料进行新词发现/词库构建。对比两份语料词频,即可得到非 常用词库的「语料特征词」
三、按照上述方法导出来的词表,顶多算是“语料特征词”,但是还不完全是“专业领域词汇”,还需进行语义筛选!而领域词判断,作者采用的是通过语料训练词向量,再由种子词来扩展领域词:
- 用上一步导出来的词表对比赛语料进行分词,然后训练一个Word2Vec模型 ;
- 特征词→领域词:根据Word2Vec得到的词向量来对词进行聚类。具体来说,给定若干个种子词,然后根据余弦相似度找到一批相似词来(>阈值),放入队列中(有点类似基于连通性的聚类算法,即A和B相似,B和C也相似,那么A、B、C就聚为一类),继续往下传递…,实现由人工种子词来扩展领域词!
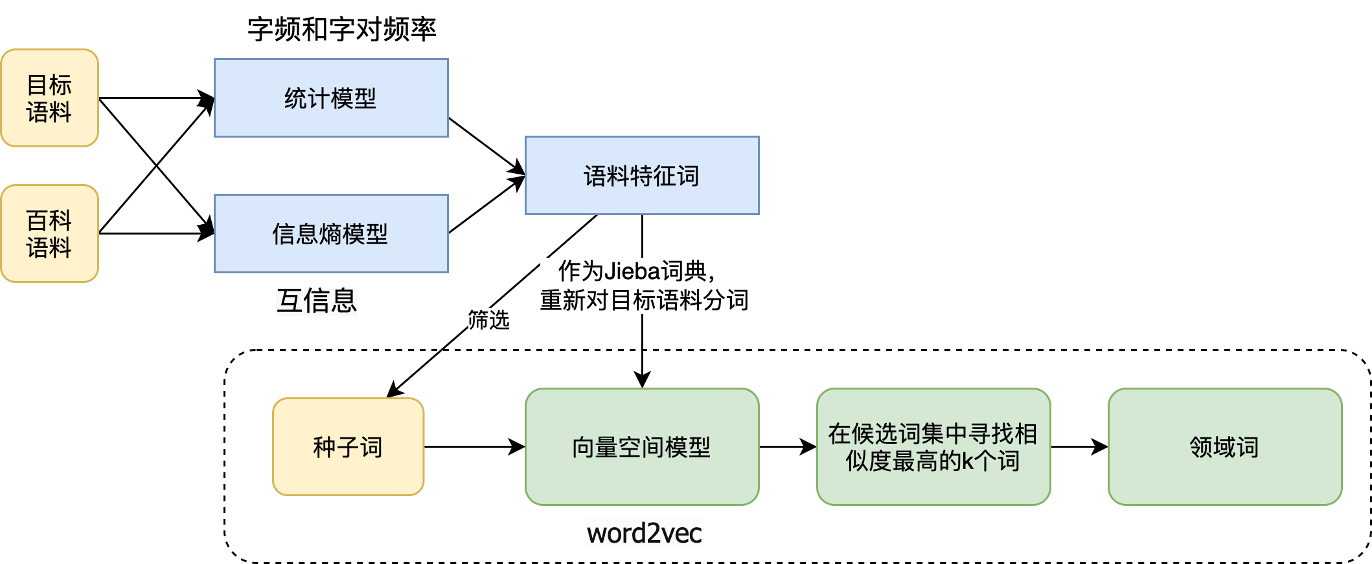
四、抽取结果:
五、分析
结果并不是很理想,抽取出太多无关的词…一方面可能是种子词不够?另一方面可能通用语料不够大?分词精度不太够?过滤规则不够强?
但是这个方法的优点很明显,通过信息熵来做无监督分词,不光计算量减小了很多,而且不在需要设置超参数中ngram的值,挖掘出的词也更符号“语义完整性”;而领域词判断,作者采用的是通过语料训练词向量,再由种子词来扩展领域词,也不失为一个好思路。
实验 4:《Unsupervised Key-phrase Extraction and Clustering for Classifification Scheme in Scientifific Publications》
近两年一些无监督的方法,2021年AAAI的一篇论文,这篇论文是做keyphrase extraction 并对抽取到的关键标签进行层次聚类。对文章分词后,使用chunking的方式对candidate进行抽取,并用一些预训练模型和一些文章的统计信息对candidate进行排序,这篇文章的重点主要放在了ranking和clustering上。
- Document Relevance score : 通过SIFRank计算文档相关度。
- Domain Relevance score : 根据candidate和domain glossaries(领域词表)预训练词向量,根据candidate去计算关于领域词表的余弦相似度,最终的相关度得分为Top N的相似度结果的均值
- Phrase Quality score : PMI, length_score 等等的统计数据用来表示phrase的质量。
clustering可以借鉴这篇 TaxoGen: Unsupervised Topic Taxonomy Construction by Adaptive Term Embedding and Clustering 本篇不做过多介绍。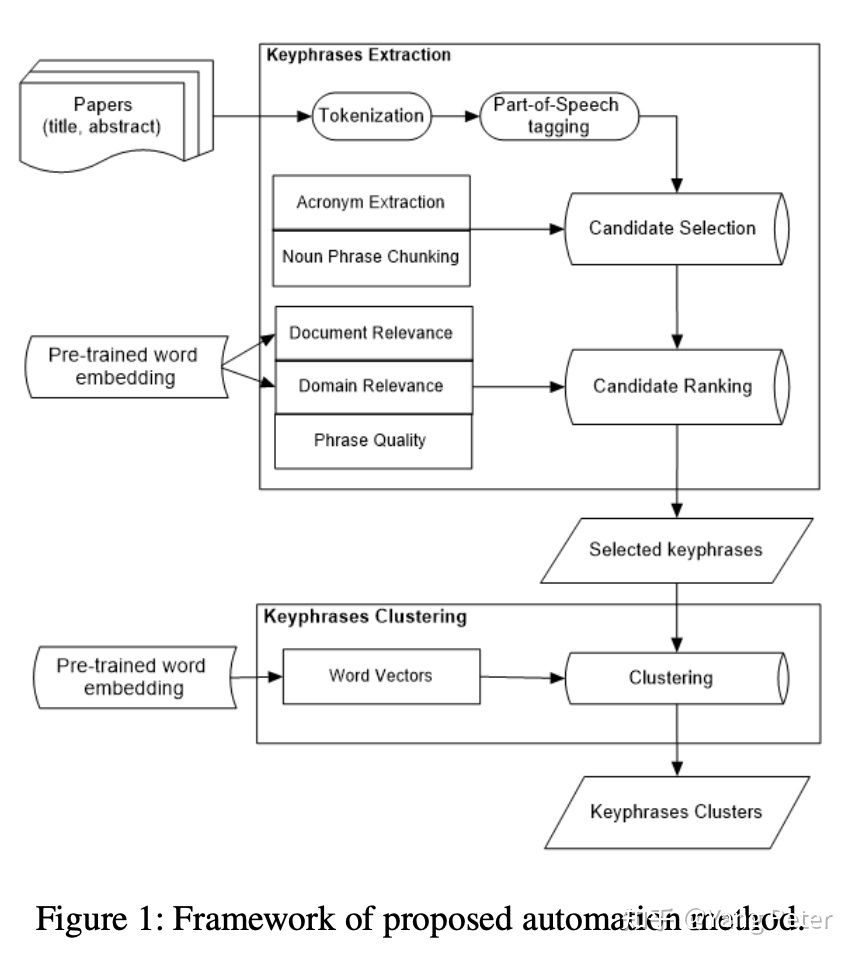
思路很清晰,方法也不是很复杂,对文章打标签提供了一种思路,并且层次聚类建立了标签间的层级关系,这对后续下游任务还是有帮助的。
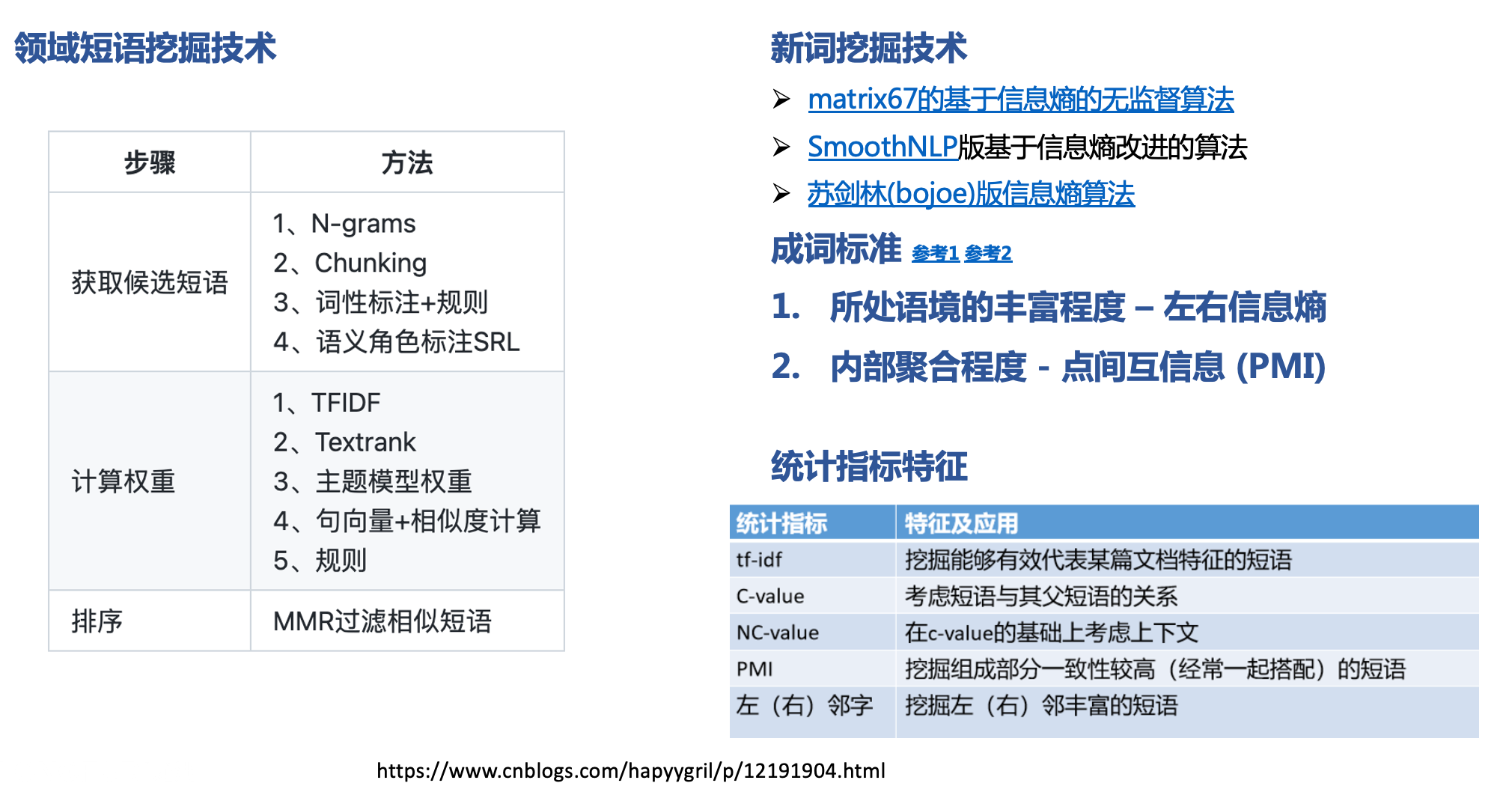
附录:关键短语抽取技术总结
附录:关键短语挖掘库
- TextRank4ZH 针对中文文本的TextRank算法的python算法实现。若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键词组(关键短语偏长)
#pip install textrank4zh --userfrom textrank4zh import TextRank4Keywordtr4w = TextRank4Keyword()tr4w.analyze(text=text, lower=True, window=2)for item in tr4w.get_keywords(num=20, word_min_len=1):print(item.word, item.weight)for phrase in tr4w.get_keyphrases(keywords_num=20, min_occur_num=1):print(phrase)
- HarvestText 作者对比测试优于上者(仅限关键词抽取)
#pip install --upgrade harvesttextfrom harvesttext import HarvestTextht = HarvestText()text = '朝鲜确认金正恩出访俄罗斯 将与普京举行会谈...'kwds = ht.extract_keywords(text, 5, method="jieba_tfidf")kwds = ht.extract_keywords(text, 5, method="textrank")
- JioNLP: 在 tfidf 方法提取的碎片化的关键词(默认使用 pkuseg 的分词工具)基础上,将在文本中相邻的关键词合并,并根据权重进行调整,同时合并较为相似的短语,并结合 LDA 模型,寻找突出主题的词汇,增加权重,组合成结果进行返回。
#pip install jionlpimport jionlp as jiotext = '朝鲜确认金正恩出访俄罗斯 将与普京举行会谈...'key_phrases = jio.keyphrase.extract_keyphrase(text)
- Keyword-BERT的关键词词典构造
- LAC (paddlepaddle >=2.0、LAC>=2.1) + DDParser
#pip install lac==2.0from LAC import LAClac = LAC(mode="rank") # 词语重要性text = "LAC是个优秀的分词工具"rank_result = lac.run(text)#[['LAC', '是', '个', '优秀', '的', '分词', '工具'], ['nz', 'v', 'q', 'a', 'u', 'n', 'n'], [3, 0, 0, 2, 0, 3, 2]]
- SmoothNLP(待尝试) ```python corpus = list(*) top_k = 0.2 # 取前k个new words或前k%的new words chunk_size = 1000000 # 用chunksize分块大小来读取文件 min_n = 2 # 抽取ngram及以上 max_n = 8 # 抽取ngram及以下 min_freq = 1 # 抽取目标的最低词频
from smoothnlp.algorithm.phrase import extract_phrase extract_phrase(corpus,top_k,chunk_size,min_n,max_n,min_freq)
output: [‘a’,…,’b’]
```
参考
关键短语抽取(DDParser 关键词词库构建+Bert 二分类排序)
限定域文本语料的短语挖掘(Phrase Mining)
NLP(二十二):基于依存句法的关键词抽取算法
词汇挖掘与实体识别
一个专业词汇聚类实践-Supernan1994’s Personal Blog
“AIIA”杯-国家电网-电力专业领域词汇挖掘比赛第五名PPT分享
文本挖掘从小白到精通(二十四)—-如何基于上下文语境提取关键词/关键短语

若有收获,就点个赞吧
0 人点赞
