title: 58智能客服QABot
subtitle: 58智能客服QABot
date: 2021-10-31
author: NSX
catalog: true
tags:
- 58
- 智能问答系统
本文根据58同城AI Lab负责人詹坤林在DataFunTalk人工智能技术沙龙所分享的《五八同城智能客服系统“帮帮”技术揭秘》编辑整理而成,在未改变原意的基础上稍做整理。
整体架构

“帮帮”整体技术架构如图所示,包括基础服务层、应用服务层、编辑运营层、接入层以及在线客服系统。
- 基础服务层提供对话系统的基础技术能力,系统需要对用户输入的一段语句进行理解,这里需要自然语言理解模块,对语句进行分词、词性标注、实体识别、关键词抽取和句法分析等;同时需要识别用户的意图,包括通用意图和业务意图,通用意图是指用户是来做业务咨询还是闲聊,业务意图是指若用户是做业务咨询,具体咨询什么业务,这里会使用文本分类的技术去识别用户意图。
- 基础服务之上是应用服务层,这一层具体实现了KB-Bot基于问答知识库的机器人、Task-Bot任务对话型机器和Chat-Bot闲聊类型机器人,这是“帮帮”系统的三种核心能力。
- 编辑运营层是指有一个编辑团队支撑着“帮帮”的算法策略迭代,主要完成数据标注、问答运营、数据分析和效果评估的工作,这些工作输出会作用到基础服务层和应用服务层。
- 基于应用服务层,对外提供通用的接口服务以便于业务方接入,我们支持Android、iOS和web端的接入。此外,机器不是万能的,用户有很多复杂的问题仍需要人工解决,这里有一套在线客服系统提供了人工在线客服的能力,应用服务层会和这套在线客服系统做无缝对接。
核心功能
“帮帮”系统的核心是提供KB-Bot、Task-Bot和Chat-Bot三种能力,下面分别介绍下这里使用到的技术。
KB-Bot

KB-Bot是指基于问答知识库的对话机器人,它主要实现了“帮帮”最重要的能力——提供业务咨询类服务。58的用户使用帮帮主要是来进行业务咨询,例如询问账号为何被锁、帖子为何被删、如何购买帖子置顶服务等等。业务咨询类的回答需要基于问答知识库来实现,这里的问答知识库是一个包含众多问答对的数据集。我们将问题划分为标准问题和扩展问题,例如“为什么删除我的帖子”这个是一个标准问题,语句表达很标准,它会有一个标准答案,其近似的问法我们称之为扩展问题,例如“为什么删我贴”、“告诉我为啥删帖”等,这些都表达的是一个意思,这些问题同样对应的是相同的标准答案。有了问答知识库,用户来询问时就是一个问题匹配的过程了,只需要将用户输入的问题和知识库中的问题做匹配,得到意思最相近的那条问题,然后将对应的答案返回给用户,这就完成了一次问答操作。问答知识库的构建非常关键,这里会首先对客服团队历史积累的问题数据进行抽象,形成标准问题,然后结合算法和标注对标准问题做扩展,形成初始问答知识库,在系统上线后,对新产生的数据又会进行挖掘,不断扩充知识库。

基于知识库的问答可以使用检索或者分类模型来实现:
检索式回答的流程是:首先对用户的输入问题做处理,如分词、抽取关键词、同义词扩展、计算句子向量等;然后基于处理结果在知识库中做检索匹配,例如利用BM25、TF-IDF或者向量相似度等匹配出一个问题集合,这类似推荐系统中的召回过程;由于我们是一个问答系统,最终是直接返回给用户一个答案,因此需要从问题集合中挑出最相似的那个问题,这里会对问题集合做重排序,例如利用规则、机器学习或者深度学习模型做排序,每个问题会被打上一个分值,最终挑选出top1,将这个问题对应的答案返回给用户,这就完成了一次对话流程。在实际应用中,我们还会设置阈值来保证回答的准确性,若最终每个问题的得分低于阈值,会将头部的几个问题以列表的形式返回给用户,最终用户可以选择他想问的问题,进而得到具体的答案。

这里还可以使用分类模型来实现问答,一个标准问题有多种扩展问法,每个标准问题可以看做是一个分类,将用户的输入映射到标准问题上即可完成回答,因此可以将问答看做是一个大规模短文本分类的问题。我们采用了多特征、多模型、多分类结果融合的方式来完成短文本分类,在特征层尝试使用了单字、词、词性、词语属性等多种特征,在模型层应用了FastText、TextCNN和Bi-LSTM等模型,各模型的结果输出最终会做融合得到最终分类结果。
TaskBot
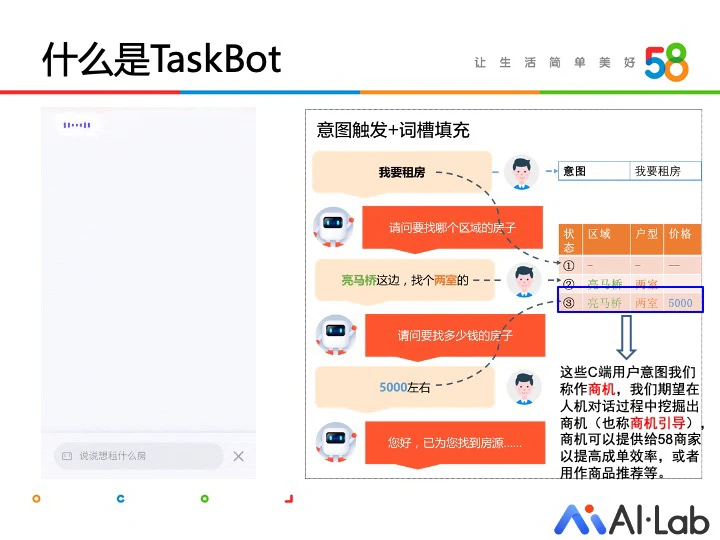
TaskBot 是一类帮助用户完成特定任务的聊天机器人。借鉴通用的 Frame 数据结构,我们采用意图+词槽的组合对用户 query 进行知识表示。在 58 场景下,我们将用户提供的特定词槽值称作商机,TaskBot 的目标即是引导用户提供商机
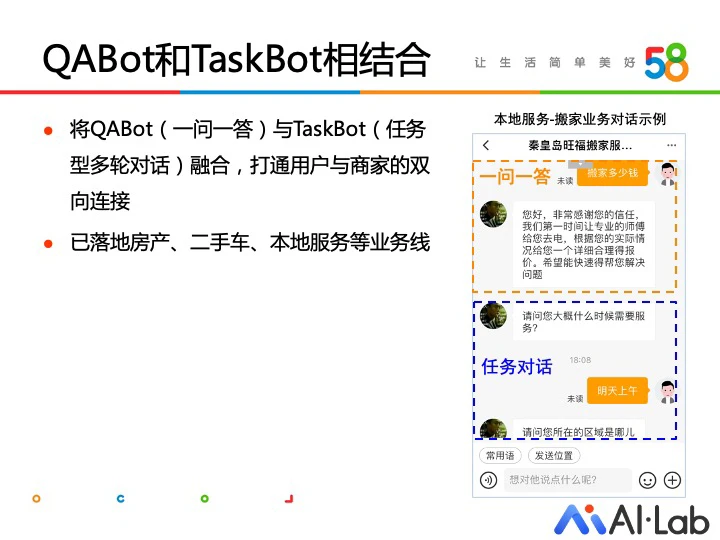
通过学习人工客服的会话,我们发现人工客服回复存在固定的模式,一般人工客服会先回答用户的提问,再根据需要问的信息对用户进行反问。在这个基础上,我们选用了结合一问一答的 QABot 和商机引导多轮 Taskbot 的方案,实现类似人工客服回答模式的商机引导过程,目前已在房产等多个业务线落地。
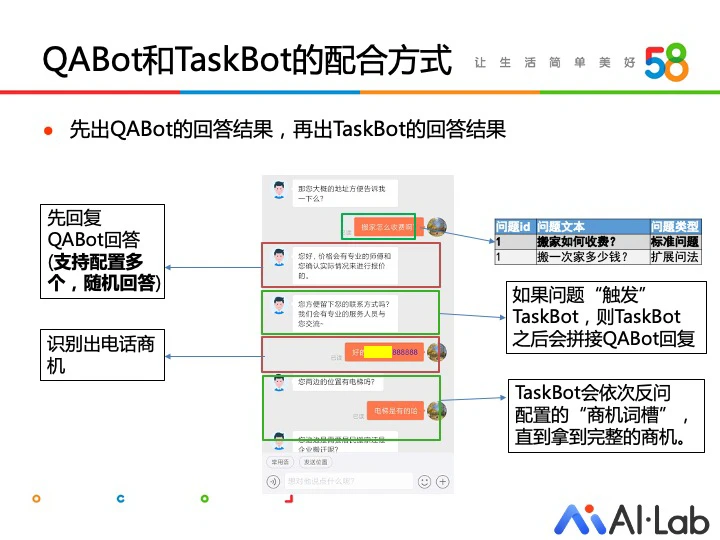
举个例子,在实际会话中,用户的第一个问题命中某标准问题,此时我们先查询答案库,获取到一问一答(QABot)的答案,同时,我们根据 TaskBot 的触发条件判断,如果触发 TaskBot,则继续回复 TaskBot 的反问。
在触发 TaskBot 后,用户在 TaskBot 的依次引导下,逐步透露商机,此时 QABot 不会命中标准问题,TaskBot 引导用户直到对话结束。
核心模型迭代
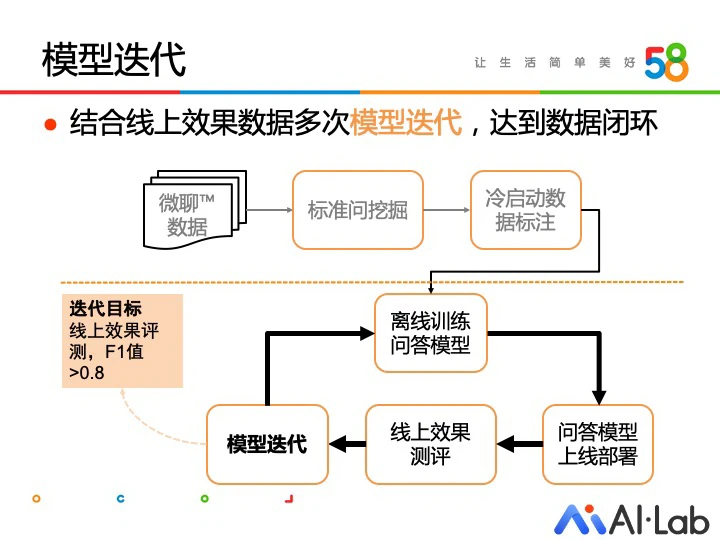
大家可以看到,问答模型的效果对用户体验非常重要。为提升问答模型效果,达到 F1 值大于 0.8 的目标,我们结合线上数据进行了多次模型迭代。
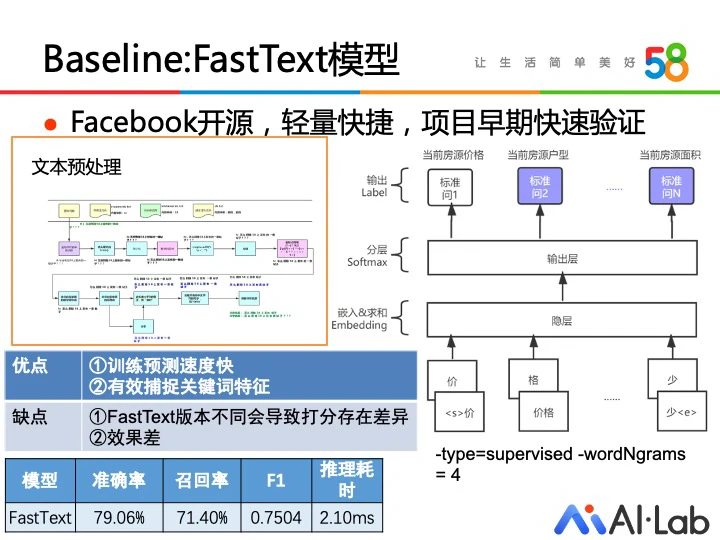
在项目初期,我们使用 FastText 作为基准,快速得到问答模型。选择 FastText 这个浅层神经网络,一方面是考虑网络的训练和预测速度快,可以快速验证数据是否存在异常;另一方面是 NGram 能够快速捕捉关键词特征,在一些关键词比较明显的类别上能取得不错的效果。
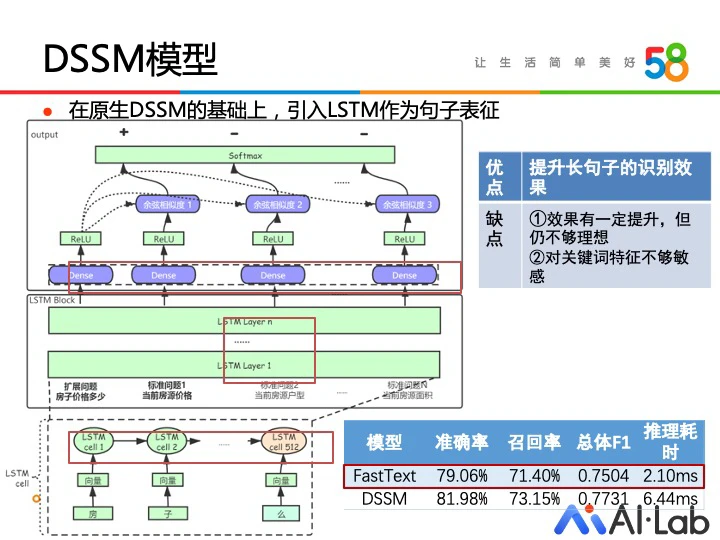

DSSM 作为一个文本匹配模型,其优势在于对样本少的类别也有较好的匹配效果。句子的表示方法对 DSSM 模型的效果有显著影响。这里我们先试用了 LSTM 模型对句子进行表示。相对于 NGram 而言,LSTM 更能够提取出句中的长程特征,提升了样本中长句子的识别效果。其次我们也对 LSTM+NGram 特征的结合进行了尝试,使得模型在有效处理长句的同时,也能不遗漏关键词特征。

58 微聊场景下积累了大量的无监督数据,在预训练模型出现后,我们得以进一步挖掘这些数据的潜力。实践中,BERT 模型作为此类半监督模型的代表,在分类任务中取得了良好的效果。BERT 的主要特点是预训练掩码语言模型+微调两个步骤的结合,同时为了配合 Transformer encoder 的使用,使用了位置编码机制。
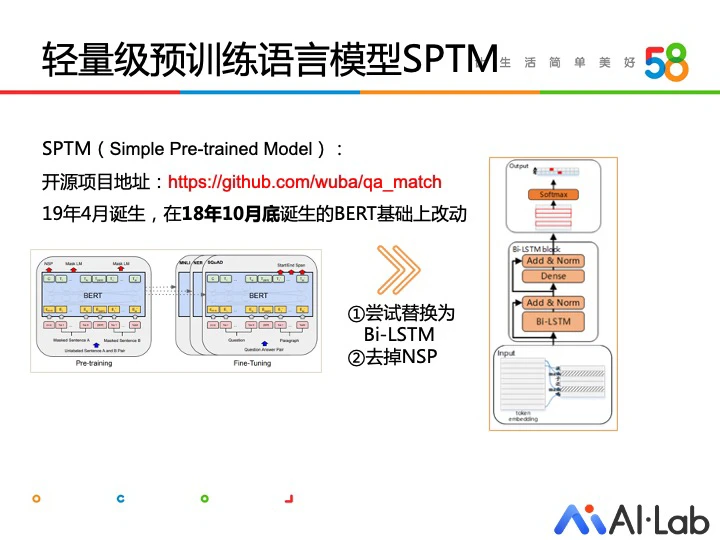
SPTMs 这个轻量级的预训练模型实现比较早,BERT 在 18 年 10 月底发布,这个模型是 19 年 4 月实现的。这里当时看主要创新点是去掉 BERT 的 NSP 任务,另外替换成 Bi-LSTM 也是做一种尝试(实际也可以用一层的 Transformer),在机器资源有限情况下让预训练变得容易。如果直接用 BERT 去预训练,耗时很久,而 SPTM 的推理耗时较低,可以在 CPU 上直接跑,十几到几十毫秒。
参考

若有收获,就点个赞吧
0 人点赞
