seq2seq简介#
1.简单介绍
Seq2Seq技术,全称Sequence to Sequence,指一般的序列到序列的转换任务。该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型(DNNs)运用于在翻译,文本自动摘要和机器人自动问答以及一些回归预测任务上,并被证实在英语-法语翻译、英语-德语翻译以及人机短问快答的应用中有着不俗的表现。
2.模型的提出
提出:Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
3.核心思想
Seq2Seq解决问题的主要思路是通过深度神经网络模型,将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码(Encoder)输入与解码(Decoder)输出两个环节组成, 前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。
基本结构#
假如原句子为为 𝑋=(𝑥1,𝑥_2,…,𝑥𝑚),目标输出为 𝑌=(𝑦1,𝑦_2,…,𝑦𝑛)。encoder 负责把输入(可能是变长的)编码为一个固定大小的向量,而decoder负责将刚才我们编码出来的向量解码为我们期望的输出。
Decoder 具体流程为:
- 所有输出端,都以一个通用的
标记开头,以 标记结尾,这两个标记也视为一个词/字; - 将
输入decoder,然后得到隐藏层向量,将这个向量与encoder的输出混合,然后送入一个分类器,分类器的结果应当输出 P; - 将P输入decoder,得到新的隐藏层向量,再次与encoder的输出混合,送入分类器,分类器应输出Q;
- 依此递归,直到分类器的结果输出
。
这就是一个基本的seq2seq模型的解码过程,逐个token地递归生成的,直到出现
训练过程#
训练阶段主要是针对Decoder的输入操作稍微复杂一些(训练和测试时是不一样的):
- 「在训练时,我们使用真实的目标文本,即“标准答案”作为输入」
- 「在测试时,由于此时没有所谓的“真实输出”或“标准答案”了,所以只能自产自销:每一步的预测结果,都送给下一步作为输入,直至输出
or 就结束」 - 这时的Decoder就是一个语言模型。由于这个语言模型是根据context vector来进行文本的生成的,因此这种类型的语言模型,被称为“条件语言模型”:Conditional LM。正因为如此,在训练过程中,我们可以使用一些预训练好的语言模型来对Decoder的参数进行初始化,从而加快迭代过程。

为什么训练和预测时的Decoder不一样?
很多人可能跟我一样,对此感到疑惑:为什么在训练的时候,不能直接使用这种语言模型的模式,使用上一步的预测来作为下一步的输入呢?——当然是可以的!
从理论上没有任何的问题,又不是不能跑。但是,在实践中人们发现,这样训练太南了。因为没有任何的引导,一开始会完全是瞎预测,正所谓“一步错,步步错”,而且越错越离谱,这样会导致训练时的累积损失太大(「误差爆炸」问题),训练起来就很费劲。这个时候,如果我们能够在每一步的预测时,让老师来指导一下,即提示一下上一个词的正确答案,decoder就可以快速步入正轨,训练过程也可以更快收敛①;此外, Teacher Forcing所有token都可以并行训练②,而Free Running只能一直都是串行。

回到Seq2Seq模型,由于训练的时候我们有标注数据对,因此我们能提前预知decoder每一步的输入和输出,因此整个结果实际上是“输入X和Y[:-1],预测Y[1:],即将目标Y错开一位来训练。用公式表示即:

但在预测阶段,真实的 都是未知的,此时它们是递归地预测出来的,可能会存在传递误差等情况。因此Teacher Forcing的问题就是训练和预测存在不一致性,这让我们很难从训练过程掌握预测的效果。举例来说,老师总是假设学生能想到前面若干步后,然后教学生下一步,但如果前面有一步想错了或者想不出来呢?这时候这个过程就无法进行下去了,也就是没法得到正确答案了,这就是Exposure Bias问题。Exposure Bias是Teacher Forcing的经典缺陷。
都是未知的,此时它们是递归地预测出来的,可能会存在传递误差等情况。因此Teacher Forcing的问题就是训练和预测存在不一致性,这让我们很难从训练过程掌握预测的效果。举例来说,老师总是假设学生能想到前面若干步后,然后教学生下一步,但如果前面有一步想错了或者想不出来呢?这时候这个过程就无法进行下去了,也就是没法得到正确答案了,这就是Exposure Bias问题。Exposure Bias是Teacher Forcing的经典缺陷。
所以,更好的办法,更常用的办法,是老师只给适量的引导,学生也积极学习。即我们设置一个概率p,每一步,以概率p靠自己上一步的输入来预测,以概率1-p根据老师的提示来预测,这种方法称为「计划采样」(scheduled sampling):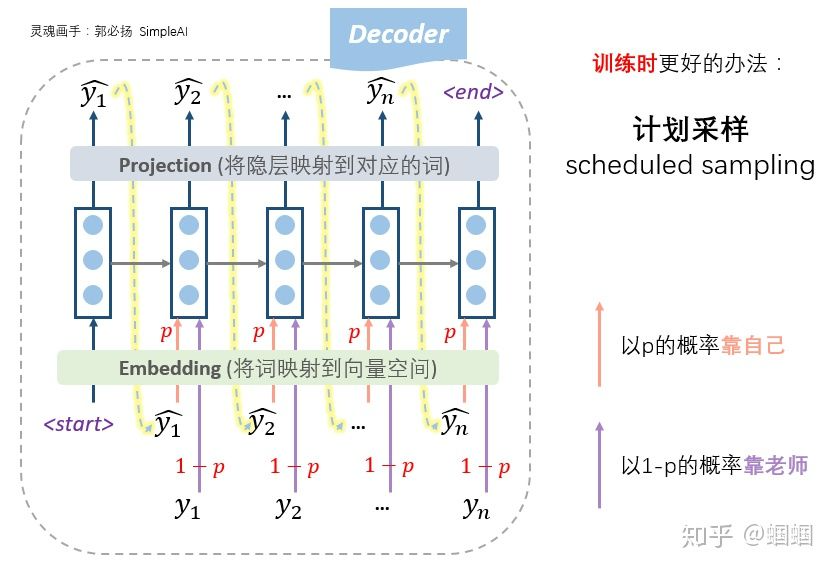
苏神也给出了两种简单可行的缓解Exposure Bias问题的对策,其中一种是随机替换策略,以及另一种基于对抗训练的策略,这两种策略的好处是它们几乎是即插即用的,并且实验表明它们能一定程度上提升文本生成的各个指标。
损失函数
decoder的每一步产生隐状态后,会通过一个projection层映射到对应的词。那怎么去计算每一步的损失呢?实际上,这个projection层,通常是一个softmax神经网络层,假设词汇量是V,则会输出一个V维度的向量,每一维代表是某个词的概率。映射的过程就是把最大概率的那个词找出来作为预测出的词。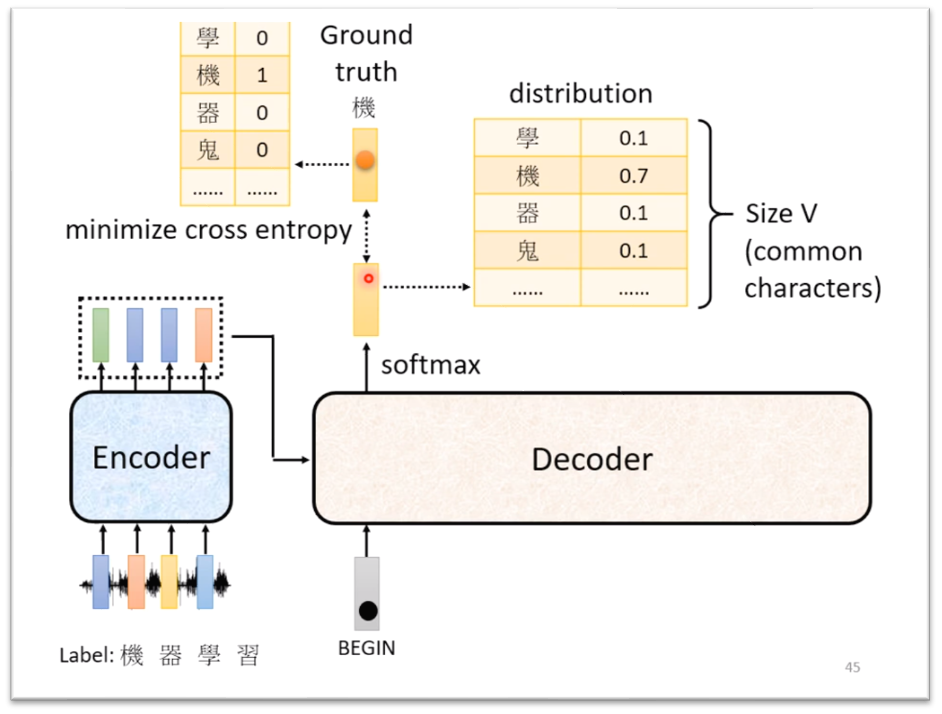
在计算损失的时候,我们使用交叉熵作为损失函数,所以我们要找出这个V维向量中,正确预测对应的词的那一维的概率大小 ,则这一步的损失就是它的负对数似然
,则这一步的损失就是它的负对数似然 ,将每一步的损失求和,即是总的损失函数:
,将每一步的损失求和,即是总的损失函数:

解码算法
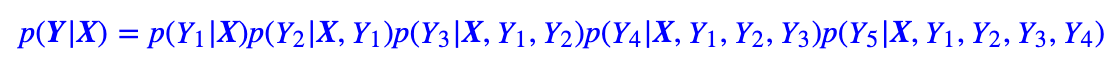
我们希望找到最大概率的Y,那要怎么做呢?解码算法大致可以分为两类:1. 确定性解码算法就是当输入文本固定之后,解码出来的输出文本也是固定的;2. 随机性解码算法,顾名思义,就是哪怕输入文本固定了,解码出来的输出文本也不是固定的,比如原生随机解码、top-k随机解码、Nucleus随机解码。
Seq2Seq 的确定性解码方式主要包括:
- 「Greedy Search」:即每一步,都预测出概率最大的那个词,然后输入给下一步;
- 「Global Search」:即求出所有可能路径的得分,取其中最大的一个;
- 「Beam Search」:即每一步,选择 K 个词作为候选,最后综合考虑,选出最优的组合。
Beam Search的操作步骤:
- 首先,我们需要设定一个候选集的大小beam size=k;
- 每一步的开始,我们从每个当前输入对应的所有可能输出,计算每一条路的“序列得分”;
- 保留“序列得分”最大的k个作为下一步的输入;
- 不断重复上述过程,直至结束,选择“序列得分”最大的那个序列作为最终结果。
Beam Search的使用,往往可以得到较好的结果,道理很容易理解,高手下棋想三步,深思熟虑才能走得远。PS:具体解码细节可参考前一篇博客《2022-03-18-解码策略Beam Search(转载)》

若有收获,就点个赞吧
0 人点赞
