直播资料PDF:https://meetup.pek3a.qingstor.com/%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E6%8A%80%E6%9C%AF%E6%9E%B6%E6%9E%84.pdf
直播链接:https://www.bilibili.com/video/BV1dy4y157Mn?from=search&seid=10798711205603161602&spm_id_from=333.337.0.0
宿主机的硬件资源包括:CPU、内存和外部I/O 设备(硬盘和网卡),宿主机上的硬件资源被运行在这个宿主机上的虚拟机所共享。每个虚拟机也有自己的虚拟硬件(vCPU、内存和外部I/O 设备等),并在这些虚拟硬件上运行客户的操作系统。 
虚拟机内的任务都是跑在vcpu上面,vcpu是宿主机的一个线程,是由宿主机上的CPU调度系统统一调度。
虚拟机内的任务都是通过这样一个二级的调度框架被映射到物理的CPU上去执行的。
内存方面通常采用分块共享的思想来进行虚拟化,宿主机的物理内存被分块管理,并且分配给每个虚拟机使用,同时宿主机还需要 维护好虚拟机所看见的物理内存到真是的机器内存之间的映射关系,这样虚拟机看到的就是一段从地址0开始的连续的物理地址空间。 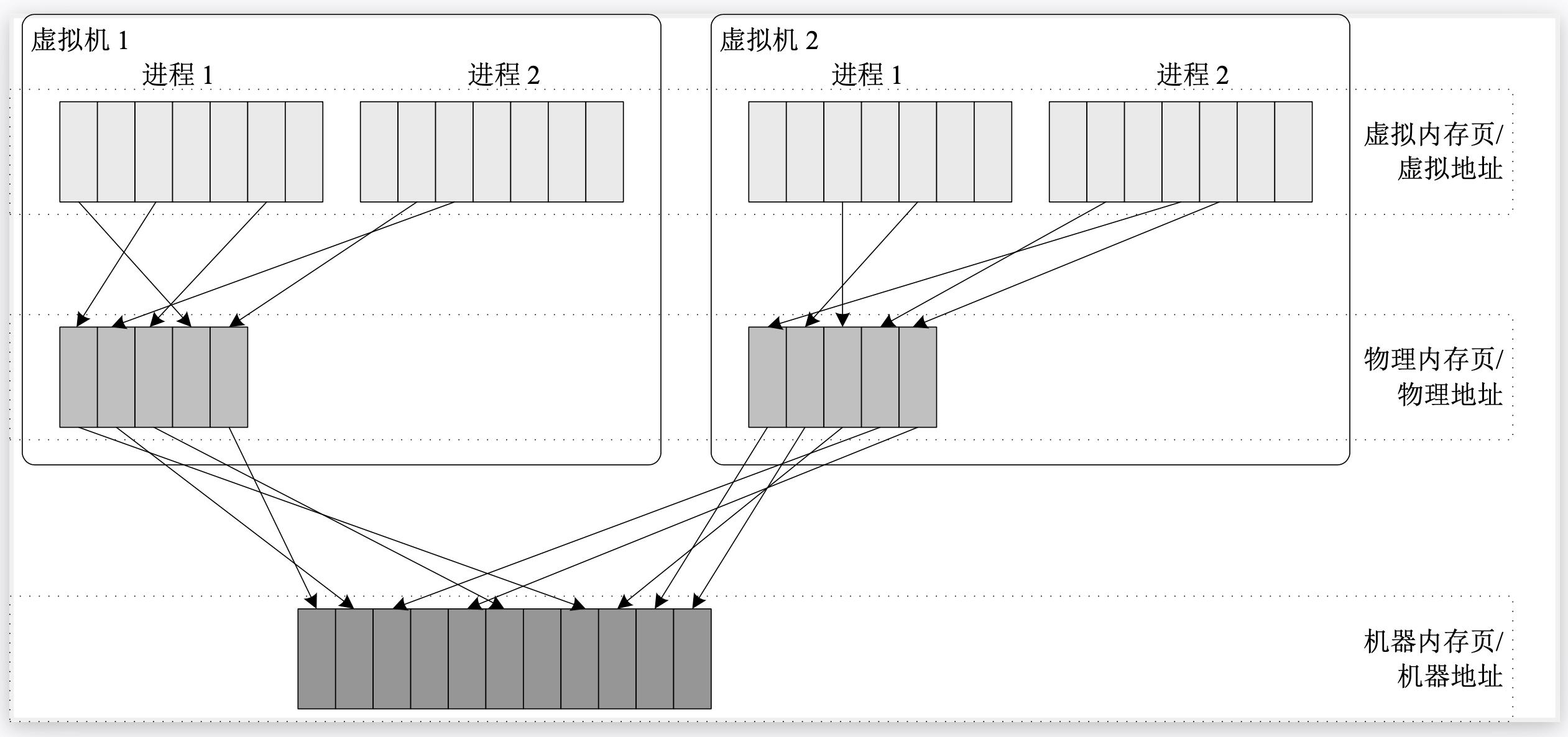
I/O设备
最简单的方法【设备直通】,就是将I/O设备直接分配给虚拟机使用,这样性能最好的,但是设备是有限的,无法共享,没有办法满足所有虚拟机的要求。
因此需要进行虚拟化,虚拟化通常有三种方式:
- 全虚拟化:这种方式需要宿主机对I/O设备进行完整的模拟,性能较差
- 半虚拟化:给虚拟机安装特定的驱动,比如virtio,通过这个驱动虚拟机能够和宿主机直接进行通讯,这种方式通常能够获得较高的性能
- 硬件辅助虚拟化:这种方式需要带有虚拟化功能的硬件,比如SR-IOV,单个I/O虚拟化技术,通过这种技术,硬件自身可以抽象出多个虚拟设备,并将虚拟设备分配给虚拟机使用,性能最好。

采用CPU独占的方式,将虚拟机里面的VCPU与宿主机上的物理核进行一对一的绑定,保证每个物理核只负责调度一个虚拟CPU,并且不进行CPU的超卖,通过这种方式避免租户间的资源竞争,保证性能的稳定。
另一方面,宿主机基本上都是numa的架构,numa间通讯会有一定的时延,因此为了降低虚拟机访问内存的时延,我们会将虚拟机和numa节点进行绑定,将虚拟机的内存绑定到与vCPU对应的numa节点,通过这种方式来避免跨numa节点的内存访问,降低内存时延。

存储优化
存储方面采用的是网络存储,并且在宿主机上实现了一个块设备的内核模块,该模块是通过RDMA协议连接远端的网络存储池,在本地生成了一个块设备(/dev/qbd1和/dev/qbd2),宿主机通过设备直连的方式,将这2个块设备分配给了2个虚机(VM1和VM2),这2个虚机对应的块设备就是/dev/sdc。通过这种方式虚拟机能够获得一个直连的块设备,并且有较高的网络性能。这里的关键技术就是RDMA。
存储
TCP的通讯过程,上面图是TCP的数据路径,应用程序在发包的时候,将数据送到了内核的缓存,内核将数据进行了处理,数据会从用户空间复制到内核空间,经过TCP/IP协议栈处理,最后将封装好的数据包交给网卡。网卡将数据包进行发送,发送到对端,对端网卡在收到数据包后,通过中断的方式通知CPU来处理数据,然后再经过一次TCP/IP协议栈的处理,将解封装后的数据复制到用户的空间,交给应用程序。
在这整个过程中,数据会经过多次的复制,并且数据处理的路径比较长,而且还需要CPU的参与。
下面图RDMA,应用程序是直接将数据写到了网卡,写的地址空间是应用程序预先申请的内存地址。网卡拿到这个数据之后,会对数据按照RDMA协议进行封装,封装完成后发送到对端。对端收到数据之后进行解封装,解封装完成后,直接写到应用程序预先指定好的内存里面,然后通知应用程序来处理。
优势
- 零拷贝(zero-copy)
- 数据的零复制
- 内核旁路(kernel bypass)
- 数据的处理不再经过内核
- 不需要CPU干预(No CPU involvement)

RDMA 的3种实现技术
- Infiniband (IB)
- RDMA over Converged Ethernet (RoCE)
- internet Wide Area RDMA Protocal (iWARP)
IB
- 需要支持IB网络的网卡及交换机 才能实现Infiniband方式
RoCE v2
- 通过以太网对IB报文进行封装
- 将IB报文封装成UDP包在以太网络传输
- 需要特定的支持RoCE协议的网卡支持才能工作,不需要特定的交换机,传统数据中心的以太网交换机就可以传递RoCE协议的报文
RoCE有2个版本,区别就是对IB报文封装的位置,图中可以看到v1版本是在链路层进行封装,v2版本是在传输层进行UDP 的封装,v2版本有较高的性能,部署也比较灵活
iWARP
基于TCP 的RDMA的实现
- 可以使用软件实现,也可以使用支持IWARP的网卡进行offload
- 存在流控相关的工作,性能相比RoCE来说较差一些


若有收获,就点个赞吧
0 人点赞
