函数注释 和 TypeScript
为什么单独将注释排在第一梯队?
我个人认为好的代码注释一定是清晰的,它就如同商品的简介,你可以在第一眼知道它当前的一些信息,如作用,传入的参数,返回了什么。
你知道当前这个常量所指向什么,你知道声明这个变量是用来干什么的。推荐在2021年,如果你们的团队正在使用TypeScript,别抱怨麻烦,它对自己的代码质量提升是非常直观的。
没有注释的代码,在
code review大概率是会被刮目相看的一件事情
变量&常量


函数(方法)
TS =>
JSDOC =>
以上使用了变量和函数方法的示例来进行一些基本的演示。JsDOC是在团队并没有使用TypeScript时的备选方案。
你真的知道函数方法吗
在写业务的时,小伙伴们很少关注一个函数方法的复杂度,这个复杂度的大小决定了他(她)人理解你代码的一个效率度,不论是React,还是Vue,甚至于写Node,Libray上面大多数都是函数在支撑着,因此函数会占据着WEB开发很大的一环。
那么来看下函数上,如何能使当前的代码调理更加的清晰。
函数SRP
对于单一原则来说,函数其实算是其中具有魄力的一员了,在大多数情况下,函数始终只用做一件事情,一段逻辑,这样的话,在结合基本的注释就能让小伙伴瞬间明白你这个方法主要是用来干什么的,而不必思考是不是还做了其他的一件事情。
但是单一原则的颗粒度又是一个问题,在写React组件的时候,如果我们采用函数单一原则,那么一个组件中的函数是海量的,所以这个时候我们就需要权衡当前逻辑的层次了,在适当的范围内,事的大小其实也能套用在函数中,我的这个函数可能是多个函数的BFF(聚合层),或者说我这个函数本身就是用来处理一个聚合任务的。
示例:
如下函数其实就是典型的一个函数处理了两个行为,但是你说它并不单一其实也不是的。如果给它的作用升级,它其实也只是处理一件事情,也只是处理Storage罢了。因此,SRP的局限在于开发者本身,你希望它处理的范围是在哪一层,那么就决定了你的函数SRP做的事情够不够大。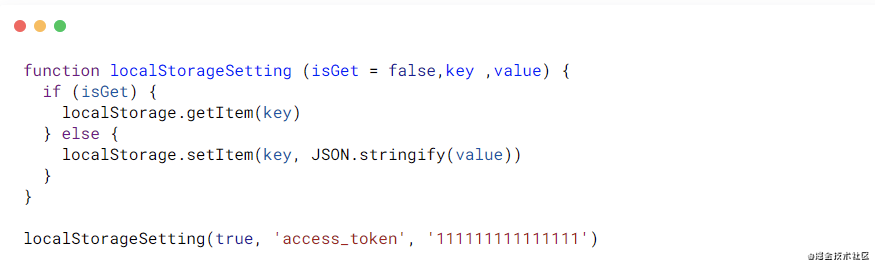
那么,我们也可以写成下面这样,将设置和获取拆分成为两个不同的函数。
主动return函数(主动停止)
对于业务的开发,往往一个函数中可能需要通过一些前置条件才能流向我们业务的一些核心逻辑。这一类的前置条件往往是一些条件判断,因此,在无法满足于这类条件的时候,后面的代码执行与否都没有任何意义的,就像面试时,简历不满足筛选条件,已读未回是一个概念。
如下代码:当姓名(name)和年龄(age)满足的时候,进行个人信息的提交,不满足时提示。那么像下面写,好像是没有什么问题。但是一层层的if else看上去并不是非常的清晰。
那么不妨试试下面这个方法吧。虽然两个方法的复杂数都是5,但其实阅读质量是有很大不同的。方案二的实现将其拆分成三个步骤,当步骤执行到误区时,那么这个步骤中的处理因素return就会执行掉。
函数合并
函数合并的作用就是(减少重复代码),大家都知道,开发者都是善于解决重复工作的小能手,喜欢一劳永逸。所以往往在写代码中,能够合并的逻辑都会被独立出来管理,如下代码:两个方法都调用了相同的判断语句。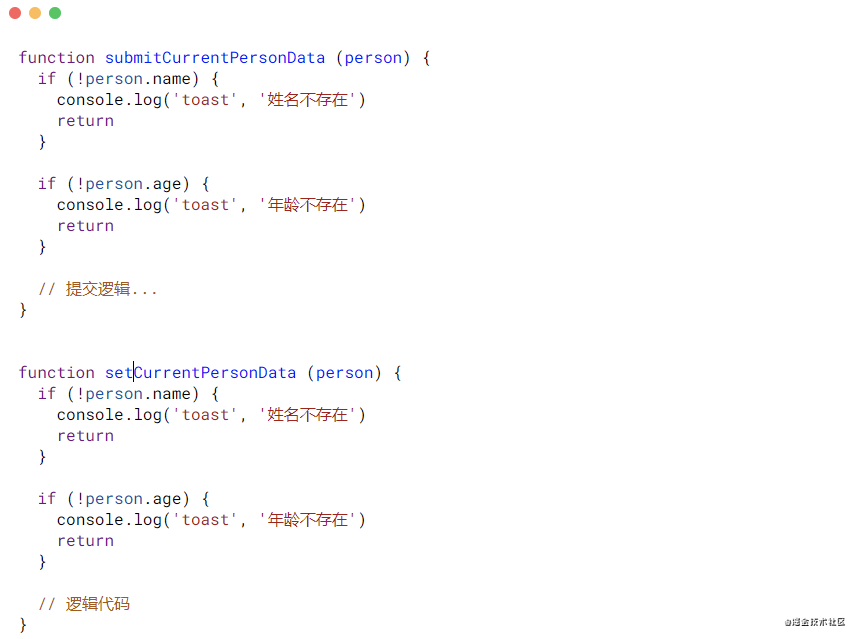
因此,如下图,我们将相同的逻辑提取成为一个函数,将公共代码做一层剥离后,返回对应的状态,随后调用进行状态的判断。
圈复杂度,函数衡量标准
我也是在今年了解到圈复杂度的概念,圈复杂度能够将函数的逻辑量化,用数据相对的标注当前函数有一个较为相对的衡量标准。
在软件测试的概念里,圈复杂度用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。【
百度百科】
那么,在我看来圈复杂度的一些标准化是怎么样的呢?
| 复杂度 | 代码状态 | 维护成本 | 建议 |
|---|---|---|---|
| 1 ~ 10 | 正常 | 低 | 无 |
| 10 ~ 20 | 复杂 | 中 | 优化逻辑,拆分子函数 |
| > 29 | 难以维护 | 高 | 强烈建议重构 |
在这里,有一个插件推荐给大家,如下图,我清晰的知道我当前函数的一个复杂度状态,能够随时的思考函数的变化的优化方式。潜移默化下,能够提高开发者思考当前实现的优化方式是,这个插件名称叫做:CodeMetrics,我认为它是对开发者有帮助的。
圈复杂度,函数衡量标准
我也是在今年了解到圈复杂度的概念,圈复杂度能够将函数的逻辑量化,用数据相对的标注当前函数有一个较为相对的衡量标准。
在软件测试的概念里,圈复杂度用来衡量一个模块判定结构的复杂程度,数量上表现为线性无关的路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。【
百度百科】
那么,在我看来圈复杂度的一些标准化是怎么样的呢?
| 复杂度 | 代码状态 | 维护成本 | 建议 |
|---|---|---|---|
| 1 ~ 10 | 正常 | 低 | 无 |
| 10 ~ 20 | 复杂 | 中 | 优化逻辑,拆分子函数 |
| > 29 | 难以维护 | 高 | 强烈建议重构 |
在这里,有一个插件推荐给大家,如下图,我清晰的知道我当前函数的一个复杂度状态,能够随时的思考函数的变化的优化方式。潜移默化下,能够提高开发者思考当前实现的优化方式是,这个插件名称叫做:CodeMetrics,我认为它是对开发者有帮助的。

复杂度高的函数,强烈建议进行重构,因为其中80%涉及到了脏代码,因此重新梳理逻辑重构是必不可免的。
点击前往VS code下载插件
状态备注维护
信息状态
获取大家都经历过后端返回的一些字段,如status,但基本上值其实是不可读的,除了后端和对接人之外,其他前端往往不清楚这个状态表示了什么。甚至于久而久之,随着需求的增加,你会好奇status中1是什么,2是什么?那么这样避免不了二次查阅文档。这期间花费的时间本身可以被节省掉。
后端的不可读字段其实都来自于实体类,但是其数据表中的字段备注非常详细。因此,后端是绝对是能够梳理起当前的一个状态的。
因此在进行状态操作的时候,在数据声明时加上备注注释。如下图,就是比较难以看懂的一个代表了:
随着grade变化,那么下一次去改变逻辑的时候,就需要重新对grade进行理解。
那么,我们可以做一些友好的注释来声明,对状态进行标注
PS.当状态可以被描述时,往往可以如下处理,定义一个状态对应的数组,返回一些对应的描述。
一般为状态对应某段中文的时候使用。

操作状态
上面是一些信息状态的处理方式,但是操作状态往往是前端抽象出来的,举个很简单的例子:一个表单的创建页面和编辑页面是不是可以复用,既然是复用那么必然涉及到了一个参数来进行判断。
如下代码,就是一个非常难理解的事情,1代表创建,2表示编辑。这是非常不推荐的一个形式。
const action = 1if (action === 1) {// 创建}if (action === 2) {// 编辑}
比较好的形式是如下:那么一下子就知道这个参数的含义是什么了。
const action = 'create'if (action === 'create') {// 创建}if (action === 'edit') {// 编辑}
使用class聚合方法,而不是object
在上面提到过一个示例,localStorage往往是需要我们自身多封装一层的,因此这种多个不同的方法,但是他们在操作一个模型的行为,就可以进行一个简单的聚合分组。
在ES5时,class语法糖还没有出来,原型类又太麻烦,那个时候就有使用object来做方法的聚合,这其实是不友好的,如下图:
但是为了有更好的扩展能力,单个对象其实就没有class有优势了,其次class有更好的面向对象基础,而object只是将函数当成属性来管理的,如果要基于当前的集合做一个超集,那么object就不能胜任子集的任务了。

若有收获,就点个赞吧
0 人点赞
