前言
交叉验证是帮助机器学习模型选择最优超参数的有用程序。它对于较小的数据集特别有用,因为这些数据集没有足够的数据来创建具有代表性的训练集、验证集和测试集。
简单地说,交叉验证将单个训练数据集拆分为训练和测试数据集的多个子集。
最简单的形式是k-fold交叉验证,它将训练集拆分为k个较小的集合。对于每个分割,使用k-1个集合的训练数据训练模型。然后使用剩余数据对模型进行验证。然后,对于每一次拆分,模型都会在剩余集合上打分。分数是各部分的平均值。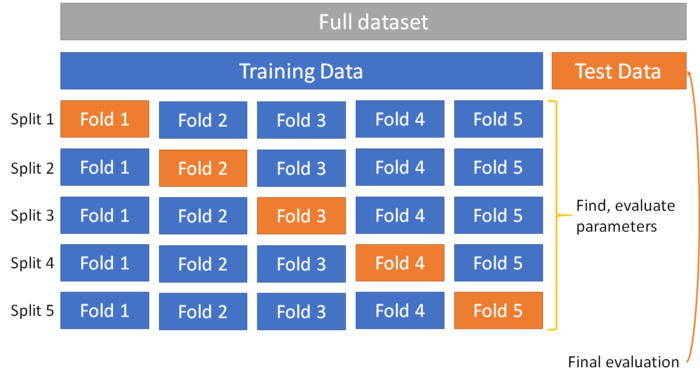
然而,这种超参数调整方法不适用于时间序列预测!
下图说明了为什么标准k折交叉验证(以及其他非时间数据分割)不适用于时间序列机器学习。该图显示了分为五个窗口的单变量序列,并指示序列中的哪些日期指定给哪个折。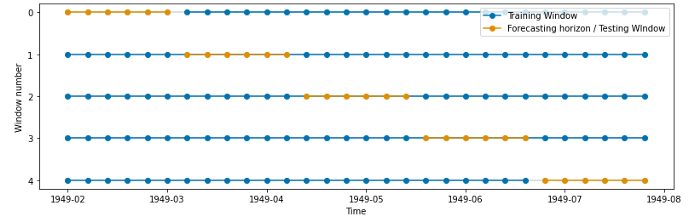
有三个突出的问题:
- 预测/测试数据出现在训练数据之前。在0号窗口中,测试数据出现在训练数据之前!
- 数据泄漏。在窗口2–4中,某些训练数据出现在测试数据之后。这是有问题的,因为模型能够预见“未来”。
- 一序列的空白。在窗口2–4中,由于测试数据取自序列的中间部分,因此训练序列中存在差距。
有关交叉验证的更多背景信息,请参阅scikit-learn文档:
https://scikit-learn.org/stable/modules/cross_validation.html
sktime
scikit learn提供了使用model_selection.KFold之类的类将数据拆分为折的方法。sktime提供了相应的类“窗口拆分器”,它们的工作方式类似。
窗口拆分器有两个可配置的参数:
window_length-每个折的训练窗口长度fh——预测范围;指定训练窗口后要包含在测试数据中的值。它可以是整数、整数列表或sktimeForecastingHorizon对象。initial_window-第一个折的训练窗口长度。如果未设置,window_length将用作第一个折的长度。step_length-折之间的步长。默认值为1步。
初始化后,窗口拆分器可以与KFold验证类相同的方式使用,为每个数据拆分提供训练和测试索引:
from sktime.forecasting.model_selection import SingleWindowSplittercv = SingleWindowSplitter()for train_idx, test_idx in cv.split(y):train_window = y[train_idx]test_window = y[test_idx]
滑动窗口拆分
此拆分器会随着时间的推移在滑动窗口上生成折。每个折的训练序列和测试序列的大小是恒定的。
在本例中, window_length =5,这意味着训练窗口始终包含5个值。预测范围FH是一个整数列表,指示训练窗口后的哪些值应在测试数据中。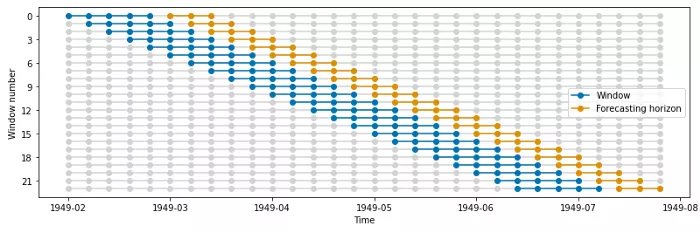
以下是将初始_窗口设置为10并将步长更改为3时的情况:
cv = SlidingWindowSplitter(window_length=5, fh=[1, 2, 3], initial_window=10, step_length=3)n_splits = cv.get_n_splits(y)print(f"Number of Folds = {n_splits}")>> Number of Folds = 6
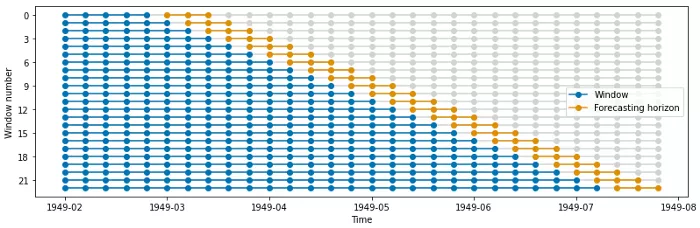
如下图所示,第一个折的训练窗口为10个时间步长;后续的折具有长度为5的训练窗口。此外,每个折滑动3步。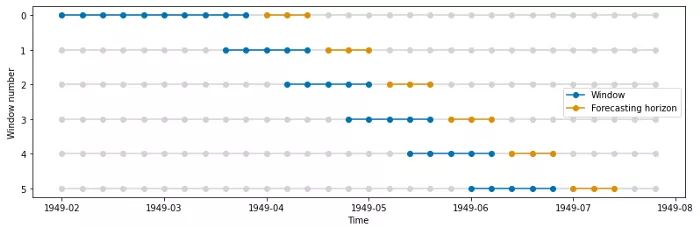
扩展窗口拆分
与滑动窗口拆分器一样,ExpandingWindowSplitter会随着时间的推移在滑动窗口上生成折。
但是,训练序列的长度会随着时间的推移而增长,每个后续折都会保留完整序列历史。每个折的测试序列长度是恒定的。
from sktime.forecasting.model_selection import ExpandingWindowSplittercv = ExpandingWindowSplitter(window_length=5, fh=[1, 2, 3])n_splits = cv.get_n_splits(y)print(f"Number of Folds = {n_splits}")>> Number of Folds = 23
预测模型选择
sktime提供了两个类,它们使用交叉验证来搜索预测模型的最佳参数:Forecasting Grid Search CV(评估所有可能的参数组合)和Forecasting Grandomized Search CV(随机选择要评估的超参数)。这些类通过反复拟合和评估同一个模型来工作。
这两个类类似于scikit learn中的交叉验证方法,并遵循类似的界面。
- 要调整的预测器
- 交叉验证构造函数(例如Sliding Window Splitter)
- 参数网格(例如{‘window_length’:[1,2,3]})
- 参数
- 评估指标(可选)
在下面的示例中,跨时间滑动窗口使用带交叉验证的网格搜索来选择最佳模型参数。参数网格指定模型参数sp(季节周期数)和 seasonal (季节分量类型)的哪些值。
预测器拟合60个时间步长初始窗口的数据。后续窗口的长度为20。预测范围设置为1,这意味着测试窗口仅包含在训练窗口之后出现的单个值。
from sktime.forecasting.exp_smoothing import ExponentialSmoothingfrom sktime.forecasting.model_selection import ForecastingGridSearchCV, SlidingWindowSplitterforecaster = ExponentialSmoothing()param_grid = {"sp": [1, 6, 12], 'seasonal': ['add, 'mul']}cv = SlidingWindowSplitter(initial_window=60, window_length=20, fh=1)gscv = ForecastingGridSearchCV(forecaster, strategy="refit", cv=cv, param_grid=param_grid)
然后可以拟合,并使用该方法进行预测:
gscv.fit(y_train)y_pred = gscv.predict([1, 2]) # 预测给定的未来时间步骤1和2的值
拟合对象包含两个有用的属性:
gscv.best_params_:调整参数gscv.best_forecaster_:具有最佳超参数的最佳预测器实例
有关使用sktime进行预测的更多详细信息,包括模型选择和调整,请参阅此处的sktime预测教程:
https://www.sktime.org/en/latest/examples/01_forecasting.html

若有收获,就点个赞吧
0 人点赞
