什么是 PyTorch
它是一个基于 Python 的科学计算包,主要有两大特色:
- 对 Python 的原生支持及其库的使用
- 深度结合于 Facebook 的开发,以满足平台中的所有深度学习要求
- PyTorch 确保提供易于使用的 API,这有助于更换的使用和理解 API
- 动态图计算是 PyTorch 的一个主要亮点,可以确保在代码执行的每个点动态构建图形,并且可以在运行时进行操作
- PyTorch 速度快,因此可以确保轻松编码和快速处理
- 对 CUDA 的支持确保代码可以在 GPU 上运行,从而减少运行代码所需的时间并提高系统的整体性能
安装 PyTorch
在机器上安装 PyTorch 还是非常简单的
基于操作系统或包管理器等系统属性,可以从命令提示符或在 IDE(如 PyCharm 等)中直接安装张量(Tensors)
Tensors 类似于 NumPy 的 n 维数组,此外 Tensors 也可以在 GPU 上进行加速计算
构造一个简单的 Tensors 并检查输出,首先看看如何构建一个 5×3 的未初始化矩阵:
Output:x = torch.empty(5, 3)print(x)
现在构造一个随机初始化的矩阵:tensor([[8.3665e+22, 4.5580e-41, 1.6025e-03],[3.0763e-41, 0.0000e+00, 0.0000e+00],[0.0000e+00, 0.0000e+00, 3.4438e-41],[0.0000e+00, 4.8901e-36, 2.8026e-45],[6.6121e+31, 0.0000e+00, 9.1084e-44]])
Output:x = torch.rand(5, 3)print(x)
直接从数据构造张量:tensor([[0.1607, 0.0298, 0.7555],[0.8887, 0.1625, 0.6643],[0.7328, 0.5419, 0.6686],[0.0793, 0.1133, 0.5956],[0.3149, 0.9995, 0.6372]])
Output:x = torch.tensor([5.5, 3])print(x)
tensor([5.5000, 3.0000])
张量运算
张量运算操作有多种语法,在下面的例子中,看看加法运算:
Output:y = torch.rand(5, 3)print(x + y)
调整大小:如果想重塑/调整张量的大小,可以使用“tensor([[ 0.2349, -0.0427, -0.5053],[ 0.6455, 0.1199, 0.4239],[ 0.1279, 0.1105, 1.4637],[ 0.4259, -0.0763, -0.9671],[ 0.6856, 0.5047, 0.4250]])
torch.view”:
Output:x = torch.randn(4, 4)y = x.view(16)z = x.view(-1, 8) # the size -1 is inferred from other dimensionsprint(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
NumPy
NumPy 是 Python 编程语言的库,增加了对大型、多维数组和矩阵的支持,以及用于对这些数组进行操作的大量高级数学函数集合
Numpy 还有以下特定
- 提供用于集成 C/C++ 和 FORTRAN 代码的工具
- 具有线性代数、傅立叶变换和随机数功能的运算能力
除了明显的科学用途外,NumPy 还可以用作通用数据的高效多维容器,也可以定义任意的数据类型
这使得 NumPy 可以无缝快速地与各种数据库集成!
连接 Array 和 Tensors 的桥梁
将 Torch Tensor 转换为 NumPy 数组,反之亦然是轻而易举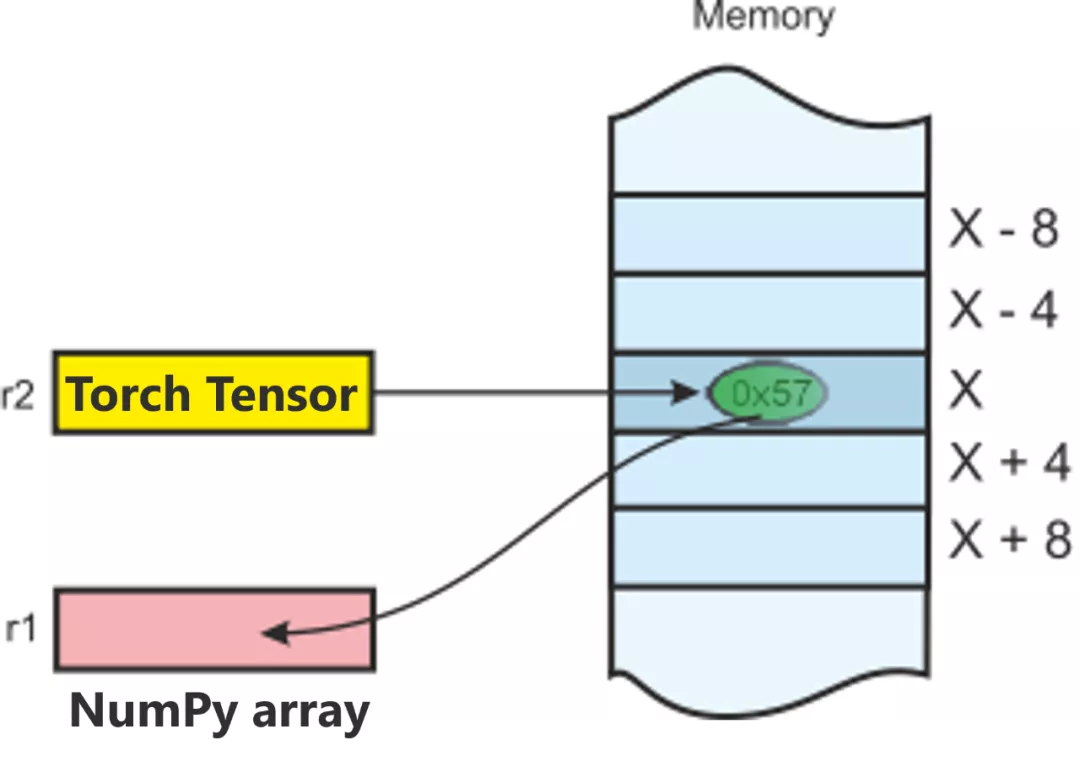
Torch Tensor 和 NumPy 数组将共享它们的底层内存位置,改变一个将同时改变另一个
将 Torch 张量转换为 NumPy 数组:
a = torch.ones(5)print(a)b = a.numpy()print(b)
Output:
tensor([1., 1., 1., 1., 1.])[1. 1. 1. 1. 1.]
下面执行求和运算并检查值的变化:
a.add_(1)print(a)print(b)
Output:
tensor([2., 2., 2., 2., 2.]) [2. 2. 2. 2. 2.]
将 NumPy 数组转换为 Torch 张量:
import numpy as noa = np.ones(5)b = torch.from_numpy(a)np.add(a, 1, out=a)print(a)print(b)
Output:
[2. 2. 2. 2. 2.]tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
可以看到,Numpy 与 Torch 之间的互转还是非常方便的
实战—训练图像分类器
数据集选择
通常,处理图像、文本、音频或视频数据时,可以使用标准的 Python 包将数据加载到 Numpy 数组中,然后就可以把这个数组转换成一个 torch.*Tensor
- 对于图像,可以 Pillow 和 OpenCV
- 对于音频,使用 Scipy 和 Librosa
- 对于文本,原始 Python、基于 Cython 的加载或 NLTK 和 SpaCy 都可以
专门针对视觉,有一个名为 torchvision 的包,它实现了 Imagenet、CIFAR10、MNIST 等常见数据集的数据加载器和用于图像的数据转换器,这样就可以很方便的使用已有数据集进行学习
在这里,将使用 CIFAR10 数据集
它有类别:“飞机”、“汽车”、“鸟”、“猫”、“鹿”、“狗”、“青蛙”、“马”、“船”、“卡车”。CIFAR-10 中的图像大小为3x32x32,即32×32像素大小的3通道彩色图像,如下图:
训练 CIFAR10 分类器
首先加载和归一化 CIFAR10 使用 torchvision 加载
import torchimport torchvisionimport torchvision.transforms as transforms
torchvision 数据集的输出是范围 [0, 1] 的 PILImage 图像,将它们转换为归一化范围 [-1, 1] 的张量
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Output:
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz Files already downloaded and verified
接下来,从数据集中打印一些训练图像
import matplotlib.pyplot as pltimport numpy as np# functions to show an imagedef imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))# get some random training imagesdataiter = iter(trainloader)images, labels = dataiter.next()# show imagesimshow(torchvision.utils.make_grid(images))# print labelsprint(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Output:
dog bird horse horse
下面定义卷积神经网络 考虑使用 3 通道图像(红色、绿色和蓝色)的情况,定义 CNN 架构
import torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
接下来定义损失函数和优化器
使用 Cross-Entropy loss 和 SGD
事实上,Cross-Entropy Loss 是一个介于 0-1 之间的概率值,完美模型的交叉熵损失为 0,但也可能发生预期值为 0.2 但最终却得到 2 的情况,这将导致非常高的损失并且根本没有任何作用
import torch.optim as optimcriterion = nn.CrossEntropyLoss()optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
下面就可以训练神经网络了
只需要遍历数据迭代器,并将输入提供给网络并进行优化
for epoch in range(2): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputsinputs, labels = data# zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeoutputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))running_loss = 0.0print('Finished Training')
Output:
[1, 2000] loss: 2.236[1, 4000] loss: 1.880[1, 6000] loss: 1.676[1, 8000] loss: 1.586[1, 10000] loss: 1.515[1, 12000] loss: 1.464[2, 2000] loss: 1.410[2, 4000] loss: 1.360[2, 6000] loss: 1.360[2, 8000] loss: 1.325[2, 10000] loss: 1.312[2, 12000] loss: 1.302Finished Training
最后,在测试集上测试神经网络
已经在训练数据集上训练了 2 遍网络,但是还需要检查网络是否学到了什么东西
通过预测神经网络输出的类标签来检查这一点,并根据真实情况进行检查,如果预测正确,将样本添加到正确预测列表中
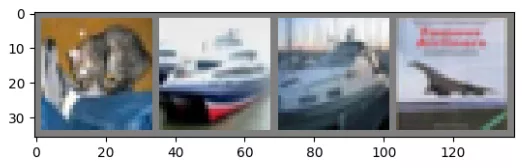
第一步,展示一张来自测试集的图片
dataiter = iter(testloader)images, labels = dataiter.next()# print imagesimshow(torchvision.utils.make_grid(images))print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
Output:
GroundTruth: cat ship ship plane
第二步,使用神经网络进行预测
outputs = net(images)predicted = torch.max(outputs, 1)print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]for j in range(4)))
outputs 输出是 10 个类别的权重,一个类别的权重越高,神经网络就越认为该图像属于该类别 Output:
Predicted: cat car car plane
效果似乎还不错
再接下来看看神经网络在整个数据集上的表现
correct = 0total = 0with torch.no_grad():for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
Output:
Accuracy of the network on the 10000 test images: 54 %
准确率还可以,比随机偶然的10%(从 10 个类中随机选择一个类)还是高出不少的
最后再看下不同类别的准确率
class_correct = list(0. for i in range(10))class_total = list(0. for i in range(10))with torch.no_grad():for data in testloader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs, 1)c = (predicted == labels).squeeze()for i in range(4):label = labels[i]class_correct[label] += c[i].item()class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))
Output:
Accuracy of plane : 61 %Accuracy of car : 85 %Accuracy of bird : 46 %Accuracy of cat : 23 %Accuracy of deer : 40 %Accuracy of dog : 36 %Accuracy of frog : 80 %Accuracy of horse : 59 %Accuracy of ship : 65 %Accuracy of truck : 46 %

若有收获,就点个赞吧
0 人点赞
