MidiMax压缩算法
简介
在很多时间序列问题中,例如金融时序数据,经常需要对其进行可视化以方便了解数据,都知道金融数据是非常巨大的,所以如果需要可视化的话需要花费较多的RAM,磁盘等计算存储资源,介绍一种压缩算法“Midimax”,该算法会通过数据大小压缩来提升时间序列图的效果。该算法的设计有如下几点目标:
- 不引入非实际数据。只返回原始数据的子集,所以没有平均、中值插值、回归和统计聚合等;
- 快速且计算量小;
- 它应该最大化信息增益。这意味着它应该尽可能多地捕捉原始数据中的变化;
由于取最小和最大点可能会给出夸大方差的错误观点,因此取中值点以保留有关信号稳定性的信息。
Midimax压缩算法
算法伪代码
向算法输入时间序列数据和压缩系数(浮点数)。
- 将时间序列数据拆分为大小相等的非重叠窗口,其中大小计算为:3表示从每个窗口获取的最小、中值和最大点。因此,要实现2的压缩因子,窗口大小必须为6。更大的压缩比需要更宽的窗口。
- 按升序对每个窗口中的值进行排序。
- 选取最小点和最大点的第一个和最后一个值。这将确保最大限度地利用差异并保留信息。
- 为中间值选取一个中间值,其中中间位置定义为。因此,即使窗口大小是均匀的,也不会进行插值。
- 根据原始索引(即时间戳)对选取的点重新排序。
案例展示
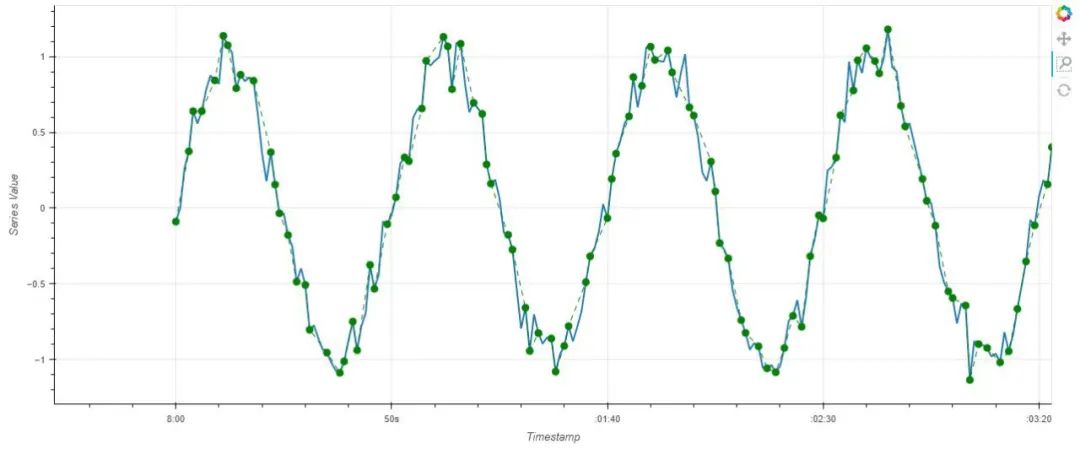
- 蓝色是原始的图;
-
代码
'''代码摘自:https://medium.com/towards-data-science/midimax-data-compression-for-large-time-series-data-daf744c89310'''import pandas as pddef compress_series(inputser: pd.Series, compfactor=2):"""Split into segments and pick 3 points from each segment, the minimum,median, and maximum. Segment length = int(compfactor x 3). So, to achieve acompression factor of 2, a segment length of 6 is needed.Parameters----------inputser : pd.SeriesInput data to be compressed.compfactor : floatCompression factor. The default is 2.Returns-------pd.SeriesCompressed output series."""# If comp factor is too low, return original dataif (compfactor < 1.4):return inputserwin_size = int(3 * compfactor) # window size# Create a column ofsegment numbersser = inputser.rename('value')ser = ser.round(3)wdf = ser.to_frame()del serstart_idxs = wdf.index[range(0, len(wdf), win_size)]wdf['win_start'] = 0wdf.loc[start_idxs, 'win_start'] = 1wdf['win_num'] = wdf['win_start'].cumsum()wdf.drop(columns='win_start', inplace=True)del win_size, start_idxs# For each window, get the indices of min, median, and maxdef get_midimax_idxs(gdf):if len(gdf) == 1:return [gdf.index[0]]elif gdf['value'].iloc[0] == gdf['value'].iloc[-1]:return [gdf.index[0]]elif len(gdf) == 2:return [gdf.index[0], gdf.index[1]]else:return [gdf.index[0], gdf.index[len(gdf) // 2], gdf.index[-1]]wdf = wdf.dropna()wdf_sorted = wdf.sort_values(['win_num', 'value'])midimax_idxs = wdf_sorted.groupby('win_num').apply(get_midimax_idxs)# Convert into a listmidimax_idxs = [idx for sublist in midimax_idxs for idx in sublist]midimax_idxs.sort()return inputser.loc[midimax_idxs]
小结
Midimax是一种简单轻量级的算法,可以减少数据的大小,并进行快速的图形绘制,可以发现:
Midimax在绘制大型时序图时可以保留原始时序的趋势;可以使用较少的点捕获原始数据中的变化,并在几秒钟内处理大量数据。
- Midimax会丢失部分细节;压缩过大的话可能会有较多信息丢失。
参考文献
https://github.com/edwinsutrisno/midimax_compression

若有收获,就点个赞吧
0 人点赞
