流转换
类型变换,防止用户API调用出错,在编译阶段就可以检查出来。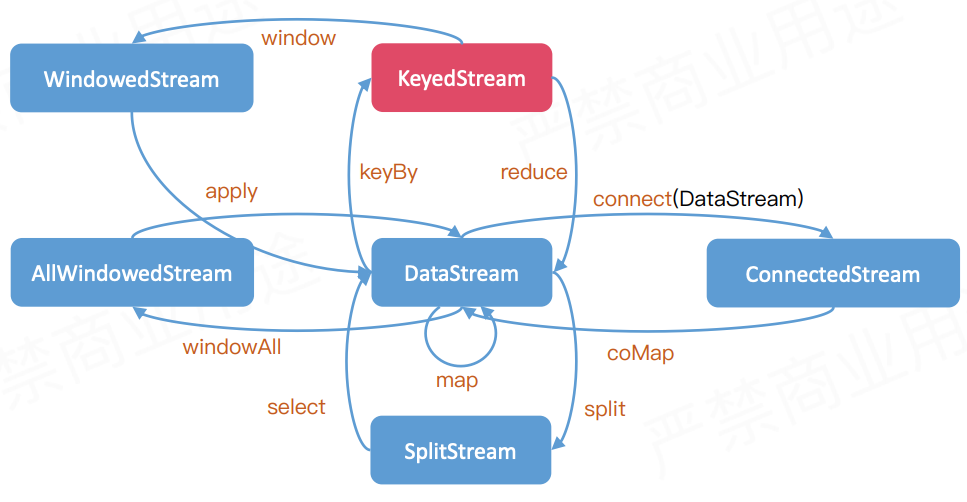
基于单条记录
合并多条流
拆分单条流
split,sideoutput,select().map()
Split和Select都过期了 用 Side Output
基于键
KeySelector
KeyedStream<Action, Long> actionsByUser = actions.keyBy((KeySelector<Action, Long>) action -> action.userId);
// Tuple指定键keyBy(0, 1);// POJO和TuplekeyBy("foo");// 如果foo是POJO,那么递归选取所有字段。keyBy("f0");// scala TuplekeyBy("_1");keyBy("1");// 嵌套keyBy("foo.bar");// 通配符指定所有字段为键// JavakeyBy("*");// ScalakeyBy("_");
其他
dataStream.global(); // 发往第一个subtaskdataStream.broadcast(); // 广播到下游所有subtaskdataStream.forward(); //一一对应发送。上下游并行度一样,如果不一样在解析执行图会报错。dataStream.shuffle(); // 随机发送dataStream.rebalance(); //轮流发送(Round-Robin)dataStream.recale(); //本地轮流发送 (Local Round-Robin)dataStream.partitionCustom(); //自定义单播,自定义回调函数返回下游一个subtask编号
聚合
类型
类型对应TypeInfomation进行序列化。
Tuple类型不支持Null。Row类型支持Null字段。
Kyro不推荐,可能会出Bug。
DataStream<String>DataStream<Tuple2<String, Integer>>
时间转换
环境推断
会自动推断运行环境,运行本地模式还是远程模式。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentval env = StreamExecutionEnvironment.getExecutionEnvironment
Function生命周期
Checkpoint
// 默认checkpoint功能是disabled的,想要使用的时候需要先启用StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】env.enableCheckpointing(1000);// 高级选项:// 设置模式为exactly-once (这是默认值)env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】env.getCheckpointConfig().setCheckpointTimeout(60000);// 同一时间只允许进行一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpointenv.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint// ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
RichFuntion
Kafka
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.9.0</version></dependency>
val properties = new Properties()properties.setProperty("bootstrap.servers", "localhost:9092")// only required for Kafka 0.8properties.setProperty("zookeeper.connect", "localhost:2181")properties.setProperty("group.id", "test")stream = env.addSource(new FlinkKafkaConsumer08[String]("topic", new SimpleStringSchema(), properties)).print()
Note
Flink1.9有新的KafkaSerializationSchema来代替KeyedSerializationSchema
最佳实践
运行时代码用Java写(UDF和Connector等)。Scala封装了很多不好优化。
坑
could not find implicit value for evidence parameter of type xxx 解决办法
import org.apache.flink.streaming.api.scala._
https://ververica.cn/developers/flink-basic-tutorial-1-basic-concept/
type是关键字前外别出现在json中

若有收获,就点个赞吧
0 人点赞
