概述
Zookeeper的角色
Leader
Learner包括Follower、Observer。
Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
只有Leader可以提供写服务。
端口作用
- 2181:对client端提供服务
- 3888:选举leader使用
- 2888:集群内机器通讯使用(Leader监听此端口)
host1的2181接收到数据后,2888端口会向host2、host3同步数据。
工作原理
两种工作模式
1) recovery(恢复模式),这个过程泛指集群服务器的启动和恢复,因为恢复也可以理解为另一种层面上的”启动”–需要恢复历史数据的启动
2) broadcast(广播模式),这是启动完毕之后,集群中的服务器开始接收客户端的连接一起工作的过程,如果客户端有修改数据的改动,那么一定会由leader广播给follower,所以称为”broadcast”.
工作步骤
- 首先每个服务器读取配置文件和数据文件,根据serverid知道本机对应的配置(就是前面那些地址和端口),并且将历史数据加载进内存中.
- 集群中的服务器开始根据前面给出的quorum port监听集群中其他服务器的请求,并且把自己选举的leader也通知其他服务器,来来往往几回,选举出集群的一个leader.
- 选举完leader其实还不算是真正意义上的”leader”,因为到了这里leader还需要与集群中的其他服务器同步数据,如果这一步出错,将返回2)中重新选举leader.在leader选举完毕之后,集群中的其他服务器称为”follower”,也就是都要听从leader的指令.
- 到了这里,集群中的所有服务器,不论是leader还是follower,大家的数据都是一致的了,可以开始接收客户端的连接了.如果是读类型的请求,那么直接返回就是了,因为并不改变数据;否则,都要向leader汇报,如何通知leader呢?就是通过前面讲到的leader_listen_port.leader收到这个修改数据的请求之后,将会广播给集群中其他follower,当超过一半数量的follower有了回复,那么就相当于这个修改操作哦了,这时leader可以告诉之前的那台服务器可以给客户端一个回应了.
1),2),3)对应的recovery过程,4)对应的broadcast过程.
Session
客户端和服务端建立的第一个TCP长连接,Session生命周期开始。ZK端口2181.
此长连接可以:心跳、向ZK发送请求、接收ZKWatch事件。
sessionTimeout内与ZK集群任意一台服务器再次建立连接,Session仍然有效。
sessionID是会话的全局唯一标识。
ZNode(节点)
ZNode在内存中组成一颗树,用/分割。
例如/app1/p_1。每个上都会保存自己的数据内容,同时还会保存一系列属性信息。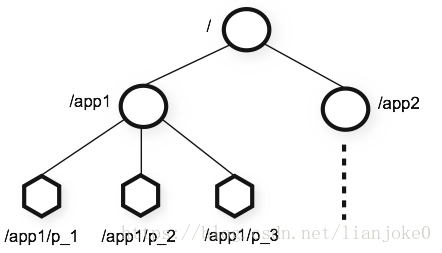
ZNode可以分为持久节点和临时节点两类。
持久节点:一旦创建,除非主动移除,否则将一直保存在Zookeeper上。
临时节点:它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
Watch机制
ZK的订阅发布也就是watch机制,是一个轻量级的设计。
因为它采用了一种推拉结合的模式。一旦服务端感知主题变了,那么只会发送一个事件类型和节点信息给关注的客户端,而不会包括具体的变更内容,所以事件本身是轻量级的,这就是所谓的“推”部分。然后,收到变更通知的客户端需要自己去拉变更的数据,这就是“拉”部分。
ACL
CREATE、READ、WRITE、DELETE、ADMIN
参考资料
ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
5分钟让你了解 ZooKeeper 的功能和原理
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/chubby-osdi06.pdf
开启Kerberos问题

若有收获,就点个赞吧
0 人点赞
