TF-IDF
https://blog.csdn.net/u011630575/article/details/80179494
ALS(交替最小二乘法)
http://www.6aiq.com/article/1525160905109
分类(classification)
决策树
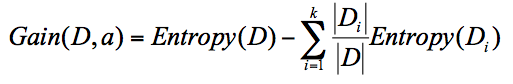
信息增益 = 信息熵 - 条件熵
ID3用信息增益,C4.5用信息增益率,CART用gini系数。
信息熵越大决策树越好
减少最大深度,可以降低过拟合。
随机森林
就是多棵决策树结果加权平均。
随机决策森林甚至能知道其内部哪棵决策树是最准确的,因而可以增
加其权重。
朴素贝叶斯(Naive Bayes Classifier)
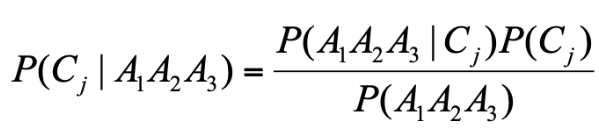
支持向量机(Support Vector Machine)
逻辑回归(Logistic Regression)
KNN(K-近邻算法)
计算距离方式
- 欧氏距离
- 曼哈顿距离
- 闵可夫斯基距离
- 切比雪夫距离
- 余弦距离
聚类(clustering)
K-means(K均值)
求欧式距离代码
def distance(a: Array[Int], b: Array[Int]) = {math.sqrt(a.zip(b).map(x => x._1 - x._2).map(x => x * x).sum)}
标准差公式
math.sqrt(n*sumSq-sum*sum)/n
检验模型质量可以求平均质心距离或信息熵或Gini(基尼)不纯度。
GMMs(高斯混合模型)
LDA
特征转化
https://yq.aliyun.com/articles/577701
参考资料
https://endymecy.gitbooks.io/spark-ml-source-analysis/
设:AE = x,B坐标原点
向量CE = BE - BC = (x, 4) - (4, 0) =(x-4, 4)
向量EF = CE顺时针旋转90度 = ( (x-4)cos(-90) - 4sin(-90), (x-4)sin(-90) + 4cos-(90) ) = (4, 4-x)
向量BF = BE + EF = (x, 4) + (4, 4-x) = (x+4, 8-x)
|BE| = sqrt(16 + x^2)
|EF| = sqrt((x+4)^2 + (8-x)^2)
设: f(x) = √2|BE|+|EF|
f(x) = √2*sqrt(16 + x^2) + sqrt((x+4)^2 + (8-x)^2)
f’(x) = 2√2*x/sqrt(16+x^2) + 24/sqrt((x+4)^2 + (8-x)^2)
因为 x 属于 [0 ,4]
所以f’(x) 恒大于等于 0,f(x)单调递增
minf(x) = f(0)
= √24+ √80
=4√2 + 4*√2
=4(√2+√5)

若有收获,就点个赞吧
0 人点赞
