CLI
本机beeline可以直接连,具体命令如下
!connect jdbc:hive2://
安装配置
配置模板:https://github.com/deadwind4/xuanwu/tree/master/hive
配置好hive-site.xml后要运行一下命令初始化MySQL中关于Hive的Schema
schematool -dbType mysql -initSchema
分区
一个分区对应一个目录。
create table par_tab (name string,nation string)partitioned by (sex string);
分桶
CREATE TABLE bucketed_user (id INT) name STRING)CLUSTERED BY (id) INTO 4 BUCKETS;
缺陷
如果通过数据文件LOAD 到分桶表中,会存在额外的MR负担。
性能调优
mapjoin
在Hive0.11后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机
hive.auto.convert.join
默认值为true,自动开户MAPJOIN优化
hive.mapjoin.smalltable.filesize
默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中
hive.auto.convert.join=true(关闭自动MAPJOIN转换操作)hive.ignore.mapjoin.hint=false(不忽略MAPJOIN标记)hive.mapjoin.smalltable.filesize=25000000(默认25M)
select /*+MAPJOIN(b,c)*/ a.a1,a.a2,b.b2 from tablea a JOIN tableb b ON a.a1=b.b1 JOIN tbalec c on a.a1=c.c1
数据倾斜
where key != null 过滤,Hive会把null当成一个key进行reduce
坑
版本问题 客户端连不上,报下面这个错
Required field ‘client_protocol’ is unset!”
UDF注册问题
HiveServer2和Spark ThriftServer都有这个问题
问题1:
一旦Server启动,UDF绑定的类就驻留到内存中,想更改逻辑要修改类名。
问题2:
同名类但内部逻辑不同,则以FUNC_ID最小(最先注册)的逻辑为准。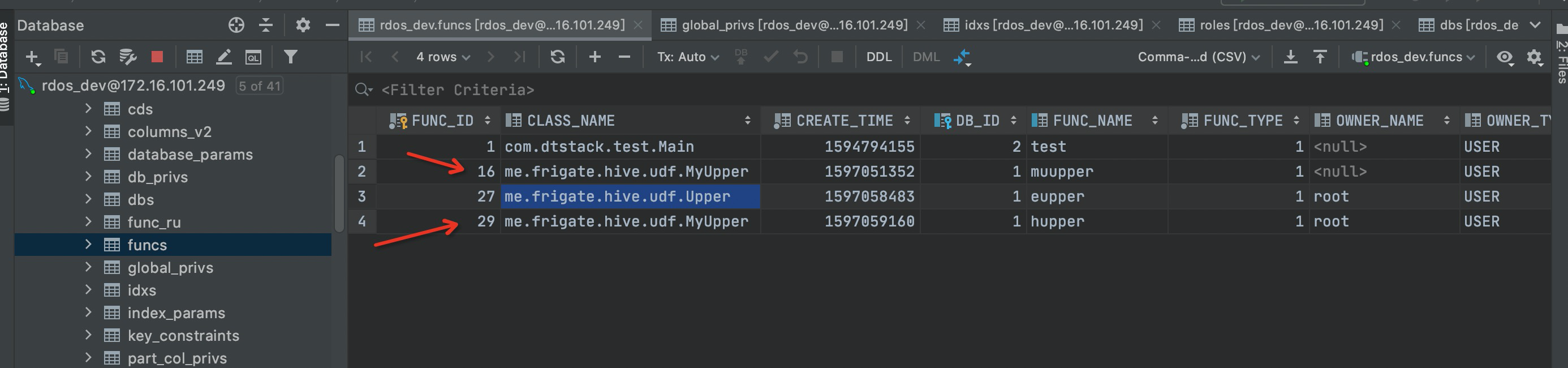
https://stackoverflow.com/questions/59135553/how-to-reload-the-updated-custom-udf-function-in-hive
https://docs.cloudera.com/documentation/enterprise/6/6.1/topics/cm_mc_hive_udf.html
https://docs.cloudera.com/HDPDocuments/HDP3/HDP-3.1.5/using-hiveql/content/hive_register_udf.html
https://www.cnblogs.com/yurunmiao/p/12964995.html
内存问题
爆OOM问题是java.opts这俩JVM选项低。一般是0.9倍的 memory.mb
set mapreduce.map.memory.mb=4096;set mapreduce.map.java.opts=-Xmx3686m;set mapreduce.reduce.memory.mb=4096;set mapreduce.reduce.java.opts=-Xmx3686m;set mapreduce.map.memory.mb=2048;set mapreduce.map.java.opts=-Xmx1843m;set mapreduce.reduce.memory.mb=2048;set mapreduce.reduce.java.opts=-Xmx1843m;
Hive 元数据管理
表结构

若有收获,就点个赞吧
0 人点赞
