一、集群启动
Standalone模式
Standalone集群启动
概述
TaskManager向ResourceManager注册
TaskManager主动和jobmanager.rpc.port: 6123建立TCP连接。如果TaskManager比JobManager先启动,会不停向rpc.port请求建立TCP连接。TCP连接建立成功后,互换akka框架内部RPC地址(应用层握手)。TM会调用ResourceManagerGateway.registerTaskExecutor向RM进行注册。
注册上报信息有TM地址、端口、ID、硬件信息。详细参数如下。
String taskExecutorAddress,ResourceID resourceId,int dataPort,HardwareDescription hardwareDescription,this.numberOfCPUCores = numberOfCPUCores;this.sizeOfPhysicalMemory = sizeOfPhysicalMemory;this.sizeOfJvmHeap = sizeOfJvmHeap;this.sizeOfManagedMemory = sizeOfManagedMemory;
注册成功RM会返回TaskExecutorRegistrationSuccess。
TaskManager向ResourceManager上报Slot信息
远程调用ResourceManagerGateway.sendSlotReport向RM的SlotManager发送SlotReport类(里面有一组SlotStatus)实例上报TM的Slot信息。
/** SlotID to identify a slot. */private final SlotID slotID;/** The resource profile of the slot. */private final ResourceProfile resourceProfile;/** If the slot is allocated, allocationId identify its allocation; else, allocationId is null. */private final AllocationID allocationID;/** If the slot is allocated, jobId identify which job this slot is allocated to; else, jobId is null. */private final JobID jobID;//ResourceProfile 主要是以下信息/*** Creates a new ResourceProfile.** @param cpuCores The number of CPU cores (possibly fractional, i.e., 0.2 cores)* @param heapMemoryInMB The size of the heap memory, in megabytes.* @param directMemoryInMB The size of the direct memory, in megabytes.* @param nativeMemoryInMB The size of the native memory, in megabytes.* @param networkMemoryInMB The size of the memory for input and output, in megabytes.* @param managedMemoryInMB The size of managed memory, in megabytes.* @param extendedResources The extended resources such as GPU and FPGA*/
此时JobManager并不启动。不提交任务JobManager不启动。
Standalone的HA模式
概述
HA模式主要多了通过ZK选举Leader、服务注册、服务发现。Flink使用的LeaderLatch选举过程为最粗暴的抢占式,谁先抢到谁就是Active其他没抢到就为Standby。Flink Master一共包含4个组件Dispatcher,ResourceManager、JobManager、RestServer。选主的ZK节点路径可以通过配置修改。
Leader选举过程
- Flink会在ZK的/leaderlatch/resource_manager_lock路径下创建临时顺序节点,节点编号最小的成为Leader下图中最小编号为29。也就是率先创建的节点获得领导权。任何存活的Master节点在此路径下都有自己的编号,Master挂掉则对应的临时节点消失。

- 当编号最小的节点获得领导权后会对比ZK上的最小SessionID和自己的发送的SessionID是否一致。如果一致,则向此节点路径写入自己的akkaRpc框架通信地址和SessionID完成服务注册。此时选主过程完成。等待TM等组件进行服务发现。
- TM启动会使用ZooKeeperLeaderRetrievalService类监听ZK的这个路径/leader/resource_manager_lock进行服务发现,从而获得Active的Master地址。
注意:如果ZK Session超时前Leader节点恢复则不会重新选举。
Yarn集群启动
YarnClient创建Flink应用阶段
0x01 获取Yarn集群信息并创建应用
以下所有请求均是Client向yarn.resourcemanager.address = RM.ASM = 8032 发送。
获取全部节点信息:ApplicationClientProtocol.getClusterNodes
返回:节点ID(节点ID里有主机名和端口)、状态、机架名(rack)、http地址、总资源、已使用资源等信息 。
获取队列信息请求:ApplicationClientProtocol.getQueueInfo
创建应用请求:ApplicationClientProtocol.getNewApplication
返回:单调递增ApplicationId(例如application_1570379089091_0019)和maxCapability(单Container最大可申请内存和VCores)
0x02 上传依赖到HDFS
所有依赖上传应用暂存目录/user/${linux_user_name}/.flink/${yarn_application_id}。应用结束会删掉此目录。
依赖分三类:conf、lib、plugins。
- conf目录下三个文件:flink-conf.yaml、logback.xml、log4j.properties。
- lib目录下所有文件:flink-dist_2.11-1.9.0.jar、flink-table_2.11-1.9.0.jar、slf4j-log4j12-1.7.15.jar等。
- plugins目录下所有文件:README.txt等。
注意:
conf目录下文件和flink-dist2.11-1.9.0.jar文件比较特殊,上传到暂存目录的根目录。其他文件和在本地相对路径一样直接映射到HDFS。
flink-conf.yaml文件名会变为${yarn_application_id}-flink-conf.yaml${random}.tmp (random是随机的JavaLong类型正整数),TM启动时不会用这个文件,因为在Yarn中AM的地址和端口是动态的。
最后调用ClientProtocol.setPermission给暂存目录设置700权限。
Flink on Yarn 缓存文件类型为LocalResourceType._FILE,可见性为_LocalResourceVisibility._APPLICATION。
_
0x03 提交应用到Yarn集群,轮询获取提交结果
调用后RM会开始拉起AM。会发送所有依赖在HDFS上的路径和程序执行入口主类等信息。ApplicationClientProtocol.submitApplication
Yarn-Session的入口主类是YarnSessionClusterEntrypoint,Per-Job是YarnJobClusterEntrypoint。
插曲:
由于Yarn的yarn.resourcemanager.store.class配置成ZKRMStateStore,所以RM收到Client的提交后,把所有启动AM的元信息(submitApplication提交的信息)通过ZK:2181写到/rmstore/ZKRMStateRoot/RMAppRoot/${yarn_application_id}节点。ZK:2888端口在节点间同步数据。作用是应用挂了后,从ZK读元信息来重启恢复应用。
submitApplication收到返回后,每250毫秒发送ApplicationClientProtocol.getApplicationReport一次,这样不停轮询。
轮询一共四种返回,前三种代表启动前的AM的三种状态ACTIVATED、ASSIGNED、LAUNCHED,第四种返回AM信息。
前三种具体返回:
ACTIVATED
Application is Activated, waiting for resources to be assigned for AMDetails : AM Partition = <DEFAULT_PARTITION> ;Partition Resource = <memory:6144, vCores:6> ;Queue's Absolute capacity = 100.0 % ;Queue's Absolute used capacity = 0.0 % ;Queue's Absolute max capacity = 100.0 %;
ASSIGNED
Scheduler has assigned a container for AM, waiting for AM container to be launched
LAUNCHED
AM container is launched, waiting for AM container to Register with RM
当AM启动调用ApplicationMasterProtocol.``registerApplicationMaster发送host、rpc_port、tracking_url到RM.scheduler:8030后,轮询出现第四种返回,应用创建成功。
tail3 主机名http://tail2:8088/proxy/application_1570379089091_0019/ tracking_url web后台的跳转urlhttp://tail3:36037 AM服务端口
如果RM没收到AM注册,则再次尝试拉起AM attemptid会加一。重复_ACTIVATED、ASSIGNED、LAUNCHED这三个状态,直到成功拉起,或达到最大阈值。
Flink设置的的重启最大次数会被Yarn本身限制住,不能超过Yarn本身的最大值。也就是说下面这俩参数以小的会生效。
yarn.application-attempts: 10 #flink配置yarn.resourcemanager.am.max-attempts: 100 #yarn配置
getApplicationReport返回AM注册的信息后改为1秒轮询一次。
RM拉起AM阶段
0x00 创建日志聚合目录
由于Yarn开启了日志聚合(yarn.log-aggregation-enable设置true)在HDFS创建目录 ${remoteRootLogDir}/${user}/${suffix}/${appid}(例如/tmp/logs/root/logs/application_1570379089091_0027)
${remoteRootLogDir}=yarn.nmodemanager.remote-app-log-dir默认/tmp/logs
${suffix}=yarn.nmodemanager.remote-app-log-dir-suffix默认logs
设置目录权限770
0x01 RM向NM发起启动容器请求
RM先向NM通过DIGEST-MD5算法认证自己。
认证后,RM向NM发送 ContainerManagementProtocol.startContainers 远程调用
参数ContainerLaunchContext和Token。ContainerLaunchContext最主要三个属性:依赖资源在HDFS上的路径、环境变量、启动容器运行命令(命令就是运行YarnSessionClusterEntrypoint这个Java入口类)。
如果Container的Token没验证通过会返回
new InvalidToken("Invalid container token used for starting container on : "+ context.getNodeId().toString());
真实例子:
Invalid container token used for starting container on : tail1:33016
Token校验失败会重新申请容器再拉起。
0x02 资源本地化
NM收到请求后,从HDFS下载运行所需的所有依赖至Container工作目录(路径为: ${yarn.nodemanager.local-dirs}/usercache/${user}/appcache//);
0x03 容器启动
运行YarnSessionClusterEntrypoint这个Java类。
启动Flink的ResourceManager包含YarnResourceManager(YarnResourceManager extends ResourceManager
*0x04 HA模式额外步骤
创建HDFS目录 /${high-availability.storageDir}/${application_id}/blob
通过ZK进行选主:
但是和Standalone不同的是,只会启动一个AM,所以这个AM指定会获得Leader(Active)。
向ZK写AM元数据:
写启动AM的容器上下文到/rmstore/ZKRMStateRoot/RMAppRoot/${application_id}
写AM容器主机、端口、Token到/rmstore/ZKRMStateRoot/RMAppRoot/${application_id}/${app_attempt_id}。attempt几次就写几个。
0x05 AM注册并开始心跳
AM向RM发送远程调用ApplicationMasterProtocol.registerApplicationMaster传递host、rpc_port、tracking_url到RM.scheduler:8030进行注册。
注册成功后每隔5秒ApplicationMasterProtocol.allocate进行一次心跳,AM申请Worker容器也是同一个TCP连接内使用allocate远程方法进行申请。即心跳和申请容器是同一个方法,所以在申请容器时allocate调用间隔会小于5秒,等申请完毕后恢复正常心跳频率。
二、提交作业
概述
提交作业机制有两类,Standalone和Yarn-Session模式一类,Yarn Per-Job模式自己一类。
前者采用HTTP POST,在Body中放JobGraph和应用Jar包;后者是Client生成JobGraph,把JobGraph和应用Jar包上传HDFS。AM从HDFS读取。
在Yarn-Session模式中提交Job后才会拉起TM,Yarn-Session提交作业已经包含Standalone所以本文直接展示Yarn-Session和Per-Job提交过程。
提交作业具体步骤
主要四步:Client提交Job、AM拉起TM、NM运行容器、JM分发Task。
Client提交阶段
0x01 Client获取AM信息
Client(运行Yarn-Session的Client不是一个,flink run 自己创建的Client)向RM.ASM:8083获取AM主机名和地址(ApplicationClientProtocol.getApplicationReport)。
0x02 Yarn-Session提交Job
Client通过HTTP POST向AM提交JobGraph和非Yarn模式一样。只不过Standalone的POST地址是flink-conf.yaml写死的,而Yarn是动态生成的AM地址。
如图HTTP POST jm_host:8081/v1/jobs提交了JobGraph、Jar包、JobArtifact。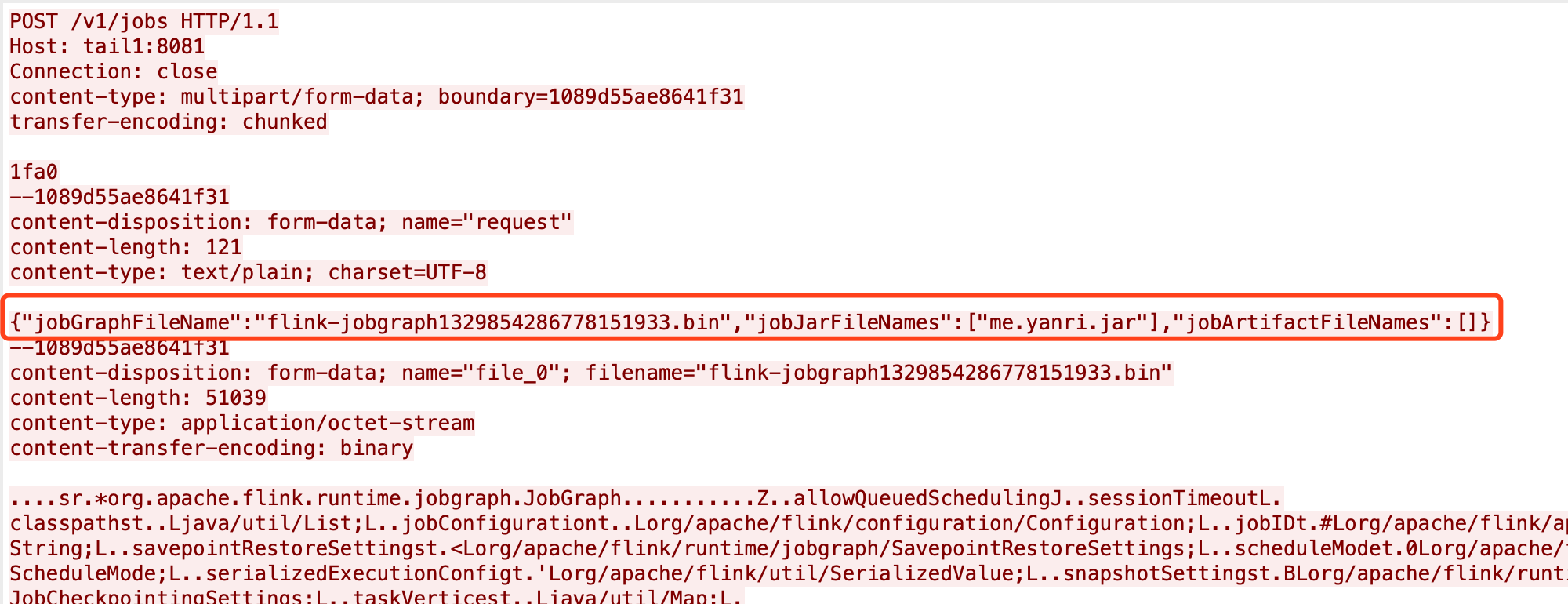
返回Job后台查看地址
{"jobUrl":"/jobs/cd68c50927a2c0121e74891b2f10938d"}
*Per-Job的提交作业
Yarn的Client在上传AM依赖到HDFS时目录多了application_1572569671434_00035234493208555882243.tmp里是JobGraph
以及Flink应用程序Jar包(例如me.wordcount-jar-with-dependencies.jar)。
Flink的RM请求拉起TM阶段
0x01 AM向RM申请容器
FlinkResourceManager向RM.scheduler:8030请求调用ApplicationMasterProtocol.allocate分配容器,由于此请求也用于5秒一次心跳,此时allocate会极小于5秒调用一次。RM返回分配的NM主机名、端口、ContainerToken。
0x02 HA模式额外步骤
写ZK:
创建/flink/${application_id}/running_job_registry/${job_id} ,运行时写入RUNNING状态。
向写/flink/${application_id}/jobgraphs/${job_id}入JobGraph在HDFS的路径
真实路径举例:
/flink/application_1572569671434_0010/running_job_registry/43acf413eeb432a4134ed403dafb7e66/flink/application_1572569671434_0010/jobgraphs/43acf413eeb432a4134ed403dafb7e66
写HDFS:
把JobGraph写入HDFS以下路径/flink/ha/${application}/blob/job_${job_id},/flink/ha/submittedJobGraphXXX
真实路径举例:
/flink/ha/submittedJobGraph01f99fe0f0bd/flink/ha/application_1572569671434_0010/blob/job_43acf413eeb432a4134ed403dafb7e66
总结:ZK里存的是小对象元数据,HDFS里存的是大对象数据。
0x03 创建Checkpoint目录
开启检查点会有这步
AM创建HDFS检查点目录:
/${state.checkpoints.dir}/${job_id}
/${state.checkpoints.dir}/${job_id}/shared
/${state.checkpoints.dir}/${job_id}/taskowned
举例:
/flink/checkpoint/cd68c50927a2c0121e74891b2f10938d
/flink/checkpoint/cd68c50927a2c0121e74891b2f10938d/shared
/flink/checkpoint/cd68c50927a2c0121e74891b2f10938d/taskowned
0x03 生成taskmanager-conf.yaml
生成taskmanager-conf.yaml并上传HDFS暂存目录。文件格式为${UUID.random.UUID()}-taskmanager-conf.yaml,前缀是随机UUID。
真实路径举例:/user/root/.flink/application_1570379089091_0019/6de714ea-9cf5-4389-ac91-c8f066d529e9-taskmanager-conf.yaml
taskmanger-conf.yaml和flink-conf.yaml区别是TM里面有动态生成的Flink Master地址(JM和YarnAM在一台机器上所以可以获得地址)。供TM启动时读取。两文件具体区别如下:
f3c83617-2943-4ef2-8555-5eece7f4465c-taskmanager-conf.yamlweb.port: 0jobmanager.rpc.address: tail3taskmanager.memory.size: 264241152bweb.tmpdir: /tmp/flink-web-9a2d9747-1524-45cd-9e00-2838142dc9b4jobmanager.rpc.port: 46396rest.address: tail3application_1570379089091_0011-flink-conf.yaml3560774894264262758.tmpjobmanager.rpc.address: tail1jobmanager.rpc.port: 6123
0x04 AM向NM拉起容器
AM写完taskmanager-conf.yaml就带Token向分配NM的ContainerManagementProtocol.startContainers
TM容器启动这个类YarnTaskExecutorRunner。
*0x05 AM不断尝试拉起TM
如果TM Container没拉起来。会重复上面所有步骤。重复过多RM会换个NM节点返回给AM继续尝试拉起TM Container。每隔10秒重复一次。
0x06 TM与RM建立心跳
心跳在后文
NM启动TM容器阶段
0x01 读HDFS依赖
TM读HDFS上的taskmanager-conf.yaml以及其他依赖
0x02 TM注册以及上报Slot信息
TM向FlinkRM发送远程调用ResourceManagerGateway.registerTaskExecutor、ResourceManagerGateway.sendSlotReport注册TM以及上报Slot信息。和Standalone模式一样上文已经有详解。
AM向TM分发Task阶段
0x01 RM向TM请求Slot
此时RM早已接到JM的Slot请求。RM向TM请求Slot。TaskExecutorGateway.requestSlot
0x02 TM向JM注册
TM向JM注册JobMasterGateway.registerTaskManager。JobMasterGateway.offerSlots给JM。
0x03 JM向TM分发Task
JM向TM向TaskExecutorGateway.submitTask。提交成功返回Acknowledge(Flink里通用消息确认类)。每个subtask分发都会收到一个确认。
0x04 TM运行Task并上报状态
TaskManager启动线程运行Task。通过调用JobMasterGateway.updateTaskExecutionState向JM上报一次Task状态。
private final JobID jobID;private final ExecutionAttemptID executionId;private final ExecutionState executionState;private final SerializedThrowable throwable;/** Serialized user-defined accumulators */private final AccumulatorSnapshot accumulators;private final IOMetrics ioMetrics;
0x05 TM与JM建立心跳
详情在后文
三、运行中
心跳检测
Flink的ResoureManager和TaskManager之间
主要heartbeatFromResourceManager和heartbeatFromTaskManager两个调用
对 ResourceManager 的每次心跳会附上自己的可用 Slot 信息,这样 ResourceManager 可以保持获得最新的可用资源信息。作为补充,当一个 Slot 变为可用时 TaskManager 会直接通知 ResourceManager 以避免心跳带来的延迟。
ResourceManager 会根据 TaskManager 的心跳和通知来得出自己的资源视图。(哪些 Slot 被哪个 JobManager 持有的视图)。
TM会向RM发送SlotReport类来上报Slot状态。具体包含以下信息
SlotReport.SlotStatus[].SlotIDSlotReport.SlotStatus[].AllocationIDSlotReport.SlotStatus[].JobIDSlotReport.SlotStatus[].ResourceProfileResourceProfile.cpuCoresResourceProfile.heapMemoryInMBResourceProfile.directMemoryInMBResourceProfile.nativeMemoryInMBResourceProfile.networkMemoryInMBResourceProfile.managedMemoryInMBResourceProfile.extendedResources #额外信息可能包含GPU和FPGA信息
Yarn 模式心跳还会带上容器ID:container_e08_1570379089091_0019_02_000003
Flink Master内的JobManager和TaskManager之间
主要heartbeatFromJobManager和heartbeatFromTaskManager两个调用
JM向发送TM AllocatedSlotReport类,里面主要包括以下三个值
AllocatedSlotReport.JobIDAllocatedSlotReport.AllocatedSlotInfos[].slotIndexAllocatedSlotReport.AllocatedSlotInfos[].AllocationId
TM向JM发送 AccumulatorReport类,主要有以下属性。
AccumulatorReport.AccumulatorSnapshot[]AccumulatorSnapshot.JobIDAccumulatorSnapshot.ExecutionAttemptIDAccumulatorSnapshot.userAccumulators<String, Accumulator>
ApplicationMaster和Yarn的ResourceManager之间
ApplicationMasterProtocol.allocate每5秒调用一次,AM.YarnResourceManager向RM.Scheduler:8030发送心跳。如果超过10秒没收到会触发AM Failover。此调用也用来YarnResourceManager向RM申请Worker容器。申请时自然缩短5秒间隔。
检查点(Checkpoint)
0x01 AM创建Checkpoint目录
AM创建HDFS目录(mkdirs)/${state.checkpoints.dir}/${job_id}/chk-${checkpoint_id},其中${checkpoint_id}从1开始增。例如:/flink/checkpoint/cd68c50927a2c0121e74891b2f10938d/chk-1
0x02 AM触发Checkpoint
JobMasterGateway extendsCheckpointCoordinatorGateway
JM远程调用TaskManagerGateway.triggerCheckpoint向TMSource触发检查点CheckpointOptions.CheckpointType中有检查点是增量还是全量以及是同步还是异步
ExecutionAttemptID executionAttemptID,JobID jobId,long checkpointId,long timestamp,CheckpointOptions checkpointOptions,boolean advanceToEndOfEventTime
0x03 TMsubtask做Checkpoint并上报JM
两种情况:确认或拒绝。
TM的每个subtask(物理执行图的节点)确认会发送CheckpointCoordinatorGateway.acknowledgeCheckpoint
final JobID jobID,final ExecutionAttemptID executionAttemptID,final long checkpointId,final CheckpointMetrics checkpointMetrics,final TaskStateSnapshot subtaskState
subtaskState里有operator的所有状态快照用operatorId区分放Map里。
如果采用FSStateBackend,会先写FS然后再发acknowledgeCheckpoint并把文件路径(${checkpointDataUri}/${job_id}/chk-${checkpoint_id}/${random.UUID})附带在响应体里。真实路径例子:
/flink/checkpoint/a3b15fb9f844912db92d653b858b818a/chk-24/047439fc-3759-4b88-8012-fa50383dde06
如果subtask拒绝会发送CheckpointCoordinatorGateway.declineCheckpoint
,此时AM会立即删掉此检查点目录。
0x04 JM 写HDFS的metadata
收到所有acknowledgeCheckpoint后:
写HDFS文件${checkpointDataUri}/${job_id}/chk-${checkpoint_id}/_metadata
例如: /flink/checkpoints/a3b15fb9f844912db92d653b858b818a/chk-24/_metadata
删掉上一个Checkpoint(可以配置保留多个,默认只保留1个)
例如:/flink/checkpoints/a3b15fb9f844912db92d653b858b818a/chk-23/
0x05 HA模式多出步骤
对ZK操作:
写当前检查点:/flink/${application_id}/checkpoints/${job_id}/${checkpoint_id}/${UUID}
删掉上一个:/flink/${application_id}/checkpoints/${job_id}/${checkpoint_id - 1}/${UUID}
计数:/flink/${application_id}/checkpoint-counter/${job_id}
真实路径:
/flink/application_1572569671434_0010/checkpoints/43acf413eeb432a4134ed403dafb7e66/0000000000000000317/59ad2cc8-875e-4acd-beed-1599abcaefb6/flink/application_1572569671434_0010/checkpoints/43acf413eeb432a4134ed403dafb7e66/0000000000000000316/59ad2cc8-875e-4acd-beed-1599abcaefb6/flink/application_1572569671434_0010/checkpoint-counter/43acf413eeb432a4134ed403dafb7e66
对HDFS操作:
写HDFS的/flink/ha/completedCheckpointc41ab92017eb。
0x06 JM确认Checkpoint完成
所有subtask都会收到JM的confirmCheckpoint请求,并且返回Acknowledge(Flink Rpc 通用响应)。
四、取消作业与集群关闭
取消作业
0x01 GET请求取消
Yarn模式向Tracking Url发送HTTP GET /proxy/${yarn_application_id}/jobs/${job_d}/yarn-cancel
实例:
GET /proxy/application_1572569671434_0004/jobs/eb6527ecaab2a35480cb93a9a40d66c1/yarn-cancel
680
0x02 JM释放Slot并与TM断开连接
JM向TM发起远程调用TaskManagerGateway.freeSlot(AllocationID``)来释放Slot每个Slot都会调用一次。
全部freeSlot请求发送完调用TaskExecutorGateway.disconnectJobManager(JobId, Exception)断开与TM连接。
其中 FlinkException
new FlinkException("Stopping JobMaster for job " + jobGraph.getName() +'(' + jobGraph.getJobID() + ").");
0x03 TM释放Slot上报RM并JM断开连接
TM收到JM的freeSlot请求会向RM发送ResourceManagerGateway.notifySlotAvailable上报此Slot已可用。
具体参数如下:
ResourceManagerGateway.notifySlotAvailable(InstanceID instanceId,SlotID slotID,AllocationID oldAllocationId)
所有Slot释放后向JM发起远程调用JobMasterGateway.disconnectTaskManager(ResourceID, Exception)从而断开连接。
其中Exception参数格式:
new FlinkException("TaskExecutor " + getAddress() +" has no more allocated slots for job " + jobId + '.'");
真实Exception例子:
TaskExecutor akka.tcp://flink@tail2:37184/user/taskmanager_0 has no more allocated slots for job c4f7fa9fbeb215f1ae6fb990bccc05f8.
*0x04 HA模式独有
清理HDFS,删除:
${high-availability.storageDir}/${applicationid}/blob/job${job_id}
${high-availability.storageDir}/completedCheckpointXXX
${high-availability.storageDir}/submittedJobGraphXXX
清理ZK:
任务完成现将DONE写入/flink/${application_id}/running_job_registry/${job_id}
然后删掉一下路径所有数据:
/flink/${application_id}/running_job_registry/${job_id}
/flink/${application_id}/leaderlatch/${job_id}/job_manager_lock
/flink/${application_id}/jobgraphs/${job_id}
Per-Job模式集群关闭
0x01 AM向RM发送结束请求
每隔100毫秒不停发ApplicationMasterProtocol.finishApplicationMaster直到调用返回 RMStateStore已经删除。finishApplicationMaster主要上报应用完成时的状态和诊断信息(diagnostics)
状态一共以下5种。
/** Undefined state when either the application has not yet finished */UNDEFINED,/** Application which finished successfully. */SUCCEEDED,/** Application which failed. */FAILED,/** Application which was terminated by a user or admin. */KILLED,/** Application which has subtasks with multiple end states. */ENDED
RM收到finishApplicationMaster请求后:
向ZK/rmstore/ZKRMStateRoot/RMAppRoot/${application_id}/${application_attempt_id}写NM地址、端口、Token等。
向/rmstore/ZKRMStateRoot/RMAppRoot/${application_id}写AM容器启动元数据(依赖文件在HDFS路径、环境变量、启动命令)。
具体路径实例:
/rmstore/ZKRMStateRoot/RMAppRoot/application_1572569671434_0005/appattempt_1572569671434_0005_000002
/rmstore/ZKRMStateRoot/RMAppRoot/application_1572569671434_0005
0x02 AM删除暂存目录
AM 调用HDFS delete 删除暂存目录(/user/${user_name}/.flink/${application_id}),例如:/user/root/.flink/application_1572569671434_0005
*0x03 HA模式独有
清理HDFS,删除${high-availability.storageDir}/${application_id}/blob
0x04 容器关闭
调用ContainerManagementProtocol.stopContainers关闭容器。
调用stopContainers之前都要使用DIGEST-MD5对主机进行认证。
AM先关TM容器,RM关AM容器。
0x05 上传聚合日志
NM上传应用日志到HDFS的日志聚合目录( /${remoteRootLogDir}/${user}/${suffix}/${applicationid})
文件名格式:${nm_host}${nm_port}
应用每个使用过的NM都会上传一份。
上传中有.tmp结尾,上传好后会调用HDFS rename去掉.tmp。
举例:
上传中:/tmp/logs/root/logs/application_1572569671434_0005/tail2_44769.tmp
上传完毕:/tmp/logs/root/logs/application_1572569671434_0005/tail2_44769
Yarn-Session与Per-Job不同的地方
直接执行yarn application -kill ${application_id}后,暂存目录不会被删除,所有集群依赖还在HDFS。
总结
作业取消后
目录/${state.checkpoints.dir}/${job_id}/下的检查点数据还在,实例:
/flink/checkpoints/5973da61d4ed806f7e3a9f1cf2bcfa95/
集群关闭后
目录/${high-availability.storageDir}/${application_id}/还在只是变成空目录。
实例:/flink/ha/application_1572569671434_0008/
ZK依然保存启动AM的元数据,两个目录:
/rmstore/ZKRMStateRoot/RMAppRoot/application_1572569671434_0008存有启动AM的容器上下文。
/rmstore/ZKRMStateRoot/RMAppRoot/application_1572569671434_0008/appattempt_1572569671434_0008_000001存有AM容器的主机、端口、Token。

若有收获,就点个赞吧
0 人点赞
