概述
四个状态机RMApp、RMAppAttempt、RMContainer。
RMApp SUBMITTED -> RMAppAttempt > RMContainer
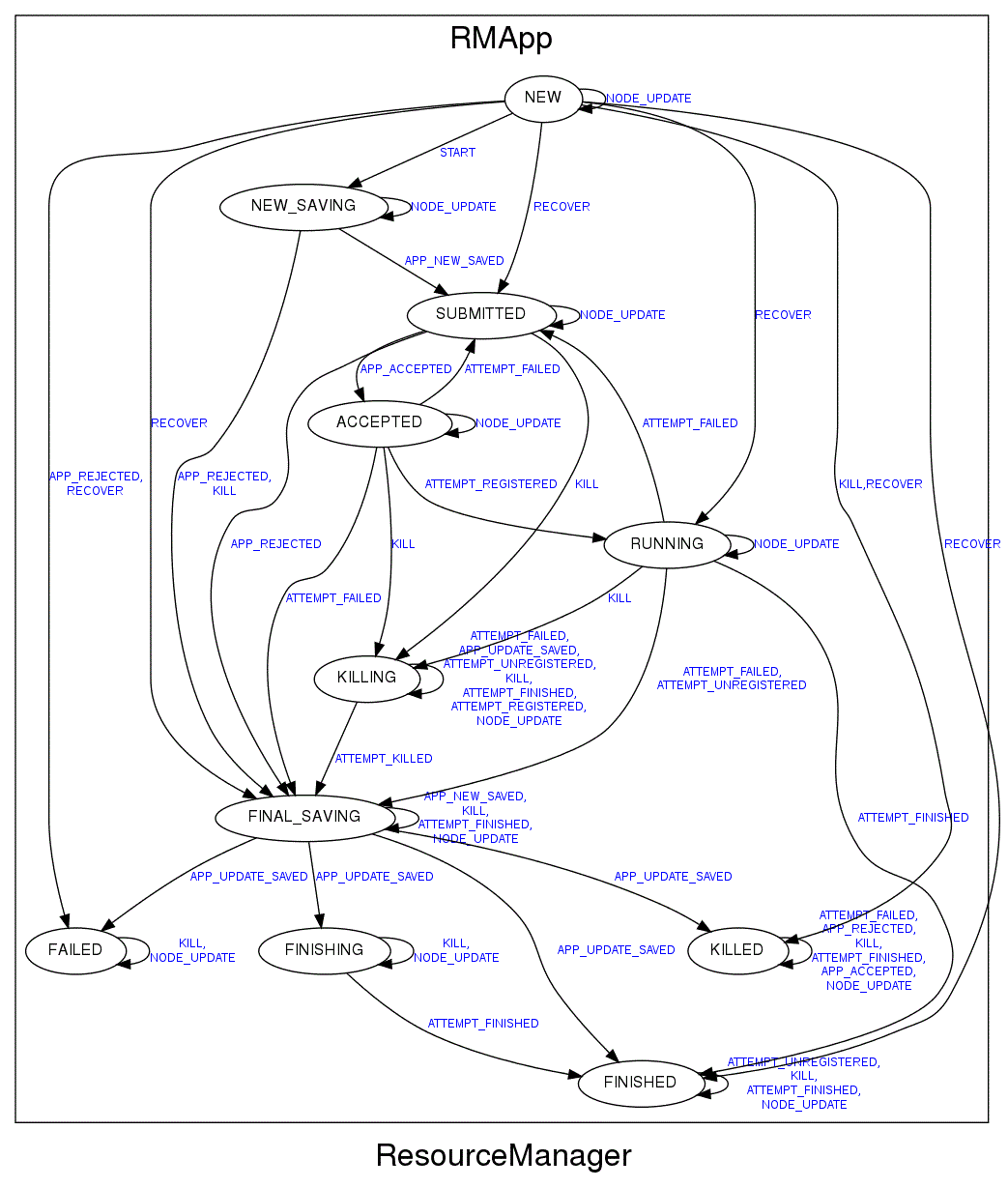
RMApp
应用程序
RMAppImpl除了状态机还保存了应用基本信息(名称、所在队列名、启动时间等)和所有Attempt信息。
状态简介
NEW_SAVEING:此状态时存储应用程序基本信息,以便故障重启恢复应用。
SUBMITTED:经合法性校验会创建RMAppAttempt。
ACCEPTED:资源调度器检查后进入。例如Capacity Scheduler,管理员可以设置提交应用上限,超过上限可以拒绝。
备注:如果RMAppAttempt(AM状态)失败会从ACCEPTED退回SUBMITTED状态。
RUNNING:收到AM注册。
FAILED:ACCEPTED状态出现失败不会立即进入FAILED会进入SUBMITTED进行重试创建RMAttemptImpl。重试次数默认2(yarn.resourcemanager.am.max-attempts)。超过重试次数会从ACCEPTED进入FAILED状态。
KILLED:RM会主动杀死AM。通常是Client下达的指令。
FINISHING:收到ApplicationMasterProtocol.finishApplicationMaster进入此状态。
FINISHED:NM通过心跳上报AM的Container运行结束进入此状态。
事件简介:
RECOVER:yarn.resourcemanager.recovery.enabled配置开启,默认不开。RM重启会让已提交但未运行的的应用发送RECOVER事件。
备注:RUNNING可能直接进入FINSHED。由于AM没有调用finishApplicationMaster。
RMAppAttempt
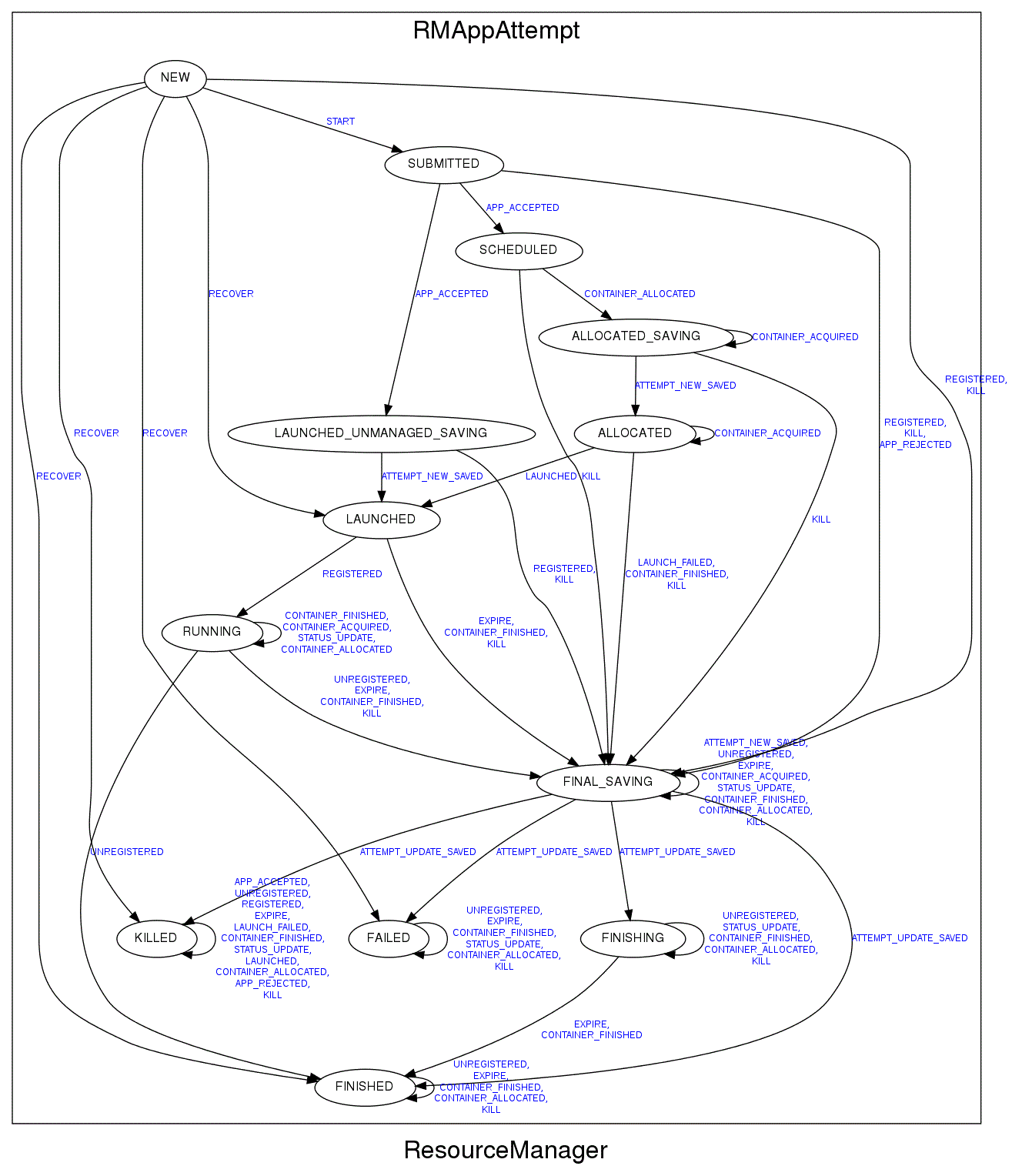
本质就是维护AM生命周期。
保存的额外信息:Attempt的基本信息如:Container信息、AM对外的tracking_url、RPC端口等。
由于失败重启,应用程序每此启动都称为Attempt(尝试)。到达重试上限会放弃。AM重启就会有一个新的RMAppAttempt。RMAppAttempt和AM紧紧绑定。
状态简介:
SUBMITED:创建Token后进入此状态。
SCHDULED:通过ResourceScheduler合法校验后进入此状态。状态中ResourceScheduler向AM分配容器。
ALLOCATED_SAVING:用于启动AM的容器分配好后进入状态。状态中将容器信息存入RMStateStore,以备故障恢复。
ALLOCATED:保存后进入此状态
LAUNCHED:ApplicationMasterLauncher向NM通信拉起AM后,会发送LAUNCHED事件,使状态机进入此状态。状态中ApplicationMasterLauncher会向AMLivelinessMonitor组件注册,以开启对ApplicationMaster的心态监控。
RUNNING:registerApplicationMaster调用后触发REGISTERED事件。从LAUNCHED进入RUNNING状态。
LAUNCHED_UNMANAGED_SAVING:为了方便测试AM的特殊状态,AM运行在客户端。保存故障恢复日志时是这个状态。
RECOVERD:yarn.resourcemanager.recovery.enabled配置。RM重启后从日志恢复AM,恢复完成进入此状态。
FINISHING:如果不是由RM启动的AM(在用户客户端)finishApplicationMaster调用后,会直接进入FINISHED状态而不是FINISHING。
FINISHED:NM通过ResourceTracker.nodeHeartbeat向RM汇报AM的容器退出后。将触发CONTAINER_FINISHED事件进入此状态。
FAILED:
如果AM在一定时间没心跳AMLiveinessMonitor会发送EXPIRE事件。ALLOCATED和LAUNCHED会进入FAILED状态。
ApplicationMasterLauncher在与NM通信拉起AM失败会触发LAUNCH_FAILED事件,使ALLOCATED转换为FAILED。
RMContainer
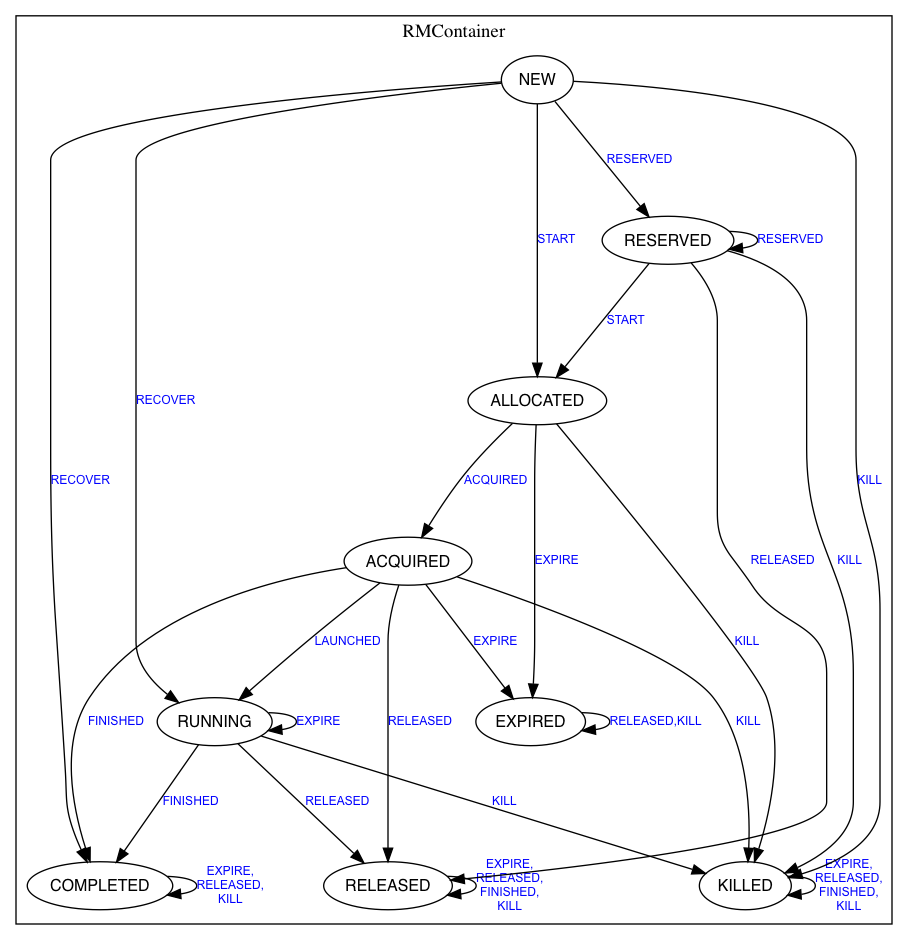
容器,目前容器不支持重用,
状态简介:
RESERVED:当一个节点资源不够且容器只能在此节点启动时。会进入此状态,等待资源充足。
ALLOCATED:RM分配容器但AM还未获取。
ACQUIRED:AM通过allocate拉取分配的容器时,资源调度器(Resource Scheduler)会触发ACQUIRED事件。将容器添加到ContainerAllocationExpirer组件监控列表中。进入此状态。
RUNNING:NM通过心跳把自己启动的一组容器状态上报给RM。触发LAUNCHED事件,进入此状态。从ContainerAllocationExpirer组件监控列表移除。(不存在过期未启动问题了)
RELEASED:用于被抢占等原因。AM通过allocate向RM上报待释放容器列表。触发RELEASED事件,进入此状态。
COMPLETED:NM的ResourceTrakcer.nodeHeartbeat心跳通知RM完成容器列表。触发FINISHED事件进入此状态。
EXPIRED:EXPIRE事件触发。RM分配给AM的容器默认10分钟内没被使用,RM强制收回进入此状态。
KILLED:KILL事件触发。保障更高优先级应用运转会强杀容器;NodeManager心跳超时会导致NM所有容器KILLED;用户杀AM会导致所属容器KILLED。
RMNode
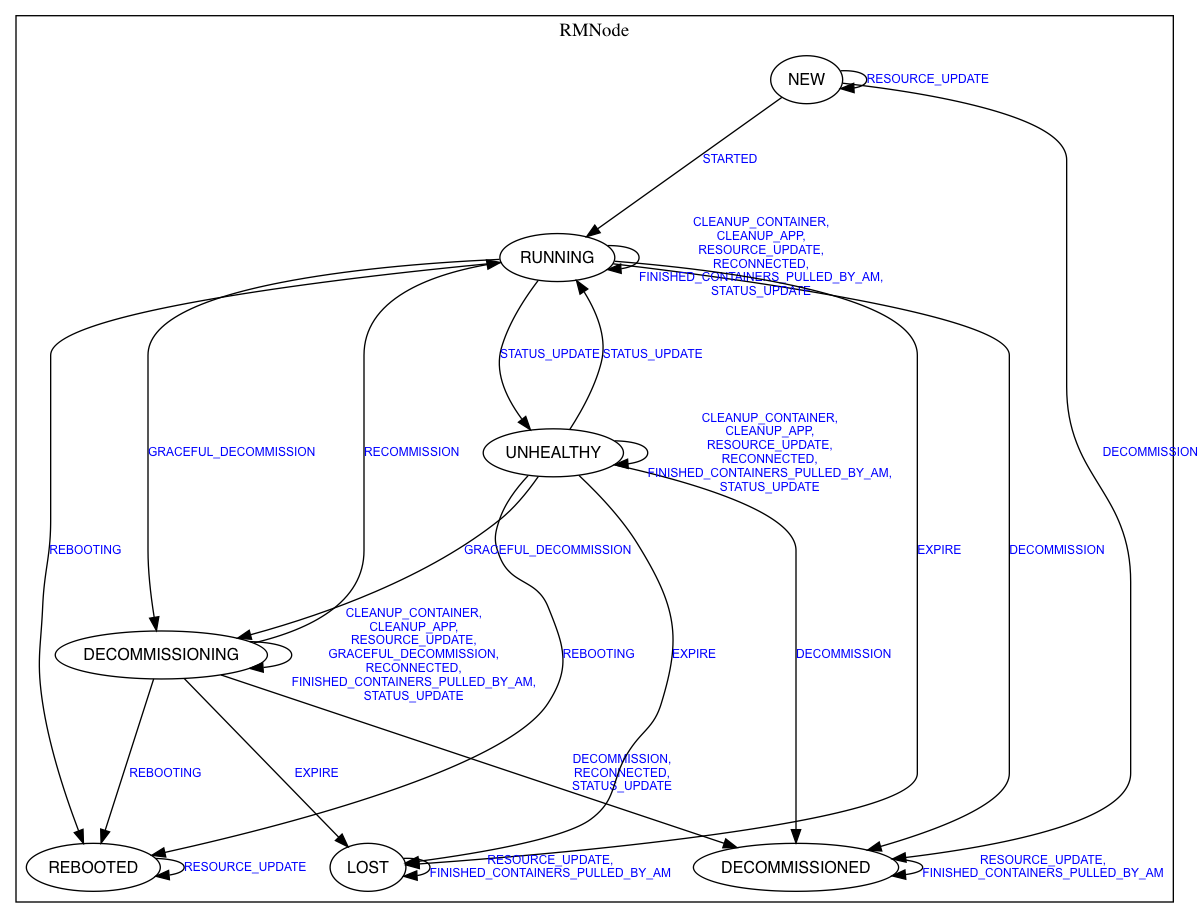
NodeManager生命周期。一个机器可以起多个NodeManager。
状态简介:
RUNNING:ResourceTracker.registerNodeManager调用触发STARTED事件,后进入此状态。
DECOMMSIONED:节点被加入exclude列表则上面的NM与RM通信触发DECOMMISSION事件,进入此状态。
UNHEALTHY:可以在NM上配置健康检测脚本,NM有个线程定期执行。NM通过心跳汇报脚本执行结果给RM。如果不健康进入此状态。
LOST:RM中组件NMLivelinessMonitor会跟踪NM心跳。超时触发EXPIRE事件进入此状态,NM上的容器也变为FAILED。
REBOOTED:如果RM发现NM心跳上报的ID与自己保存的不一致,触发REBOOTING事件进入此状态并要求NM重启已达到同步。

若有收获,就点个赞吧
0 人点赞
