配置
ResourceManager
yarn.scheduler.minimum-allocation-vcoresyarn.scheduler.maximum-allocation-vcores #单Container最大最小虚拟CPU个数yarn.scheduler.minimum-allocation-mbyarn.scheduler.maximum-allocation-mb #单任务申请最大最小内存数yarn.resourcemanager.max-completed-applicaitons 应用完成列表默认10000yarn.resourcemanager.rm.container-allocation.expiry-interval-ms 默认60000,超时AM没有使用容器则强制回收。yarn.resourcemanager.scheduler.monitor.enable true 开启抢占模式,默认falseyarn.resourcemanager.scheduler.monitor.policies 抢占策略yarn.scheduler.capacity.resource-calculator 可以设置资源比较器yarn.resourcemanager.scheduler.address #默认8030yarn.resourcemanager.address #默认8032
NodeManager
配置前缀yarn.nodemanager
yarn.nodemanager.resource.cpu-vcores #目前推荐将该值设值为与物理CPU核数数目相同。yarn.nodemanager.vmem-pmem-ratio #默认2.1虚拟内存比例。如果运行时内存超过申请内存*2.1。#NM就会kill掉这个Container,任务执行过程就会出现异常。yarn.nodemanager.resource.memory-mb #物理内存总量,Yarn如果不开硬件检测,默认8192mb。yarn.nodemanager.resource.detect-hardware-capabilities 硬件检测默认falselocal-dirs #本地可用目录列表,通常存储应用中间结果log-dirs #存放日志目录列表
健康检查
yarn.nodemanager.health-checker. #自定义脚本健康检查script.path #脚本绝对路径,如果脚本为空则不启动检查线程。interval-ms #默认600 000毫秒 10分钟。脚本执行频率。script.timeout-ms #如果脚本默认1200 000毫秒(20分钟)没响应,则为不健康。script.opts #传入脚本参数,多参数用逗号隔开。yarn.nodemamanger.disk-health-checker #磁盘健康检查enable #默认开启,磁盘检查。min-healthy-disks #默认0.25,低于这个比例则认为不健康。
事例脚本
#!/bin/bashMEMORY_RATIO=0.1free_mem=`grep MemFree /proc/meminfo | awk '{print $2}'`total_mem=`grep MemTotal /proc/meminfo | awk '{print $2}'`limit_mem=`echo | awk '{print int("'${total_mem}'"*"'${MEMORY_RATIO}'")}'`if [[ ${free_mem} -lt ${limit_mem} ]]; thenecho "ERROR, total_mem=${total_mem}, free_mem=${free_mem}, limit_mem=${limit_mem}"elseecho "OK, total_mem=${total_mem}, free_mem=${free_mem}, limit_mem=${limit_mem}"fi
日志
输出应用日志
yarn logs -applicationId application_1561533776511_4716 > log.txt
#配置多久后聚合后的日志文件被删除, 配置成 -1 或者一个负值就不会删除聚合日志.yarn.log-aggregation.retain-seconds: 86400yarn.nodemanager.remote-app-log-dir: /tmp/logsyarn.nodemanager.remote-app-log-dir-suffix: logs
权限
命令
开启history服务器,收集聚合日志。
hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
yarn application -kill application_1436784252938_0013
调试
开启远程调试模式
配置环境变量在启动
export YARN_NODEMANAGER_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,address=8788,server=y,suspend=y"
开启Debug日志模式
0x01 使用 Hadoop Shell 命令
bin/hadoop daemonlog -getlevel ${nodemanager-host}:8042 \org.apache.hadoop.yarn.server.nodemanager.NodeManagerbin/hadoop daemonlog -setlevel ${nodemanager-host}:8042 \org.apache.hadoop.yarn.server.nodemanager.NodeManager DEBUG
其 中,nodemanager-host 为 NodeManager 服 务 所 在 的 host,8042 是 NodeManager 的 HTTP 端口口号。
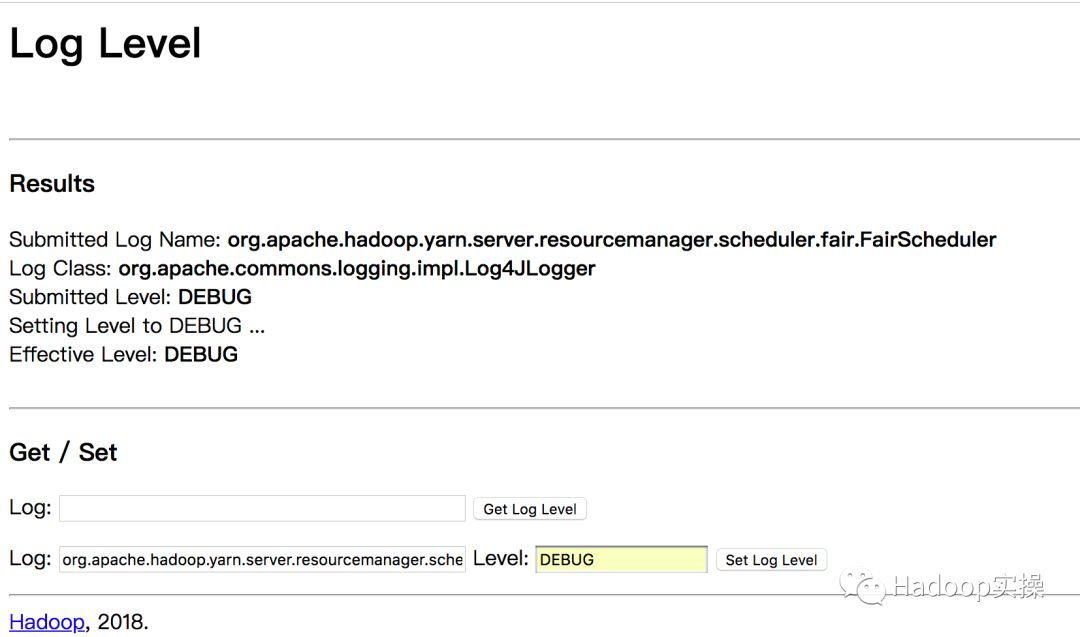
0x02 Web后台设置
RM、NM、JobHistory设置地址如下。
http://${rm_host}:8042/logLevelhttp://${nm_host}:8042/logLevelhttp://${jhs_host}:19888/logLevel
0x03 修改 log4j.properties 文件
其他两种方式重启会重置,这种可以永久修改。
log4j.logger.org.apache.hadoop.yarn.server.nodemanager.NodeManager=DEBUG
有时为了专门调试一个 Java 文件,可以把该文件日志输出到一个文件中,可在 log4j.properties 中添加以下内容:
# 定义输出方式为自定义的 TTOUTlog4j.logger.org.apache.hadoop.yarn.server.nodemanager.NodeManager=DEBUG,TTOUT# 设置 TTOUT 的输出方式为输出log4j.appender.TTOUT =org.apache.log4j.FileAppender# 设置文件路径log4j.appender.TTOUT.File=${hadoop.log.dir}/NodeManager.log# 设置文件的布局log4j.appender.TTOUT.layout=org.apache.log4j.PatternLayout# 设置文件的格式log4j.appender.TTOUT.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
这样配置会把NodeManager.java的Debug日志输出到NodeManager.log中。
自己在代码里注入日志
//类里注入下面这行代码public static final Log LOG = LogFactory.getLog(NodeManager.class);//想打日志的地方写上LOG.debug("Start to lauch NodeManager...");
坑
硬盘使用超过90%,NodeManager会失效。无法在接收任务。硬盘扩容后会自动恢复。
java.net.BindException: Problem binding to [h3:8031]
和HDFS的NameNode在一台机器上运行start-yarn.sh。会报RM的8031被占用,可以换个节点启动RM。
org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManager
java.lang.NoClassDefFoundError:org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager
复制 “hadoop-yarn-server-timelineservice-2.8.3.jar” 从 ~\hadoop-2.8.3\share\hadoop\yarn\timelineservice 到~\hadoop-2.8.3\share\hadoop\yarn 目录.
stop-yarn.sh要在RM的节点上才行。要不RM不会Stop。
内存不够问题
出现以下日志
doesn't satisfy minimum allocations,
说明这个选项太大了,机器资源无法满足。RM会发送SHUTDOWN信号杀死NM。
yarn.nodemanager.resource.memory-mbyarn.nodemanager.resource.cpu-vcores
备忘
目前要想修改NM可用资源量要重启NM,未来可能会加入动态修改可用资源(YARN-291)。
参考资料
yarn-maximum-attempt
http://johnjianfang.blogspot.com/2015/04/the-number-of-maximum-attempts-of-yarn.html

若有收获,就点个赞吧
0 人点赞
