何为Key Groups
Key-Groups是Flink对Key进行分组。进入Flink的数据有无限种可能,把无限可能的Key通过某种算法分成有限个组。
为何存在Key Groups
两大作用:
一:把Key均匀分散到每个并行算子。
Key Groups中的所有组均匀分配到现有的并行度上。实现在脱离业务的框架层面尽可能均匀的将Key打散到每个并行算子中。
二:集群重启后,进入Flink的包含Key的数据,能找到重启之前对应的状态。
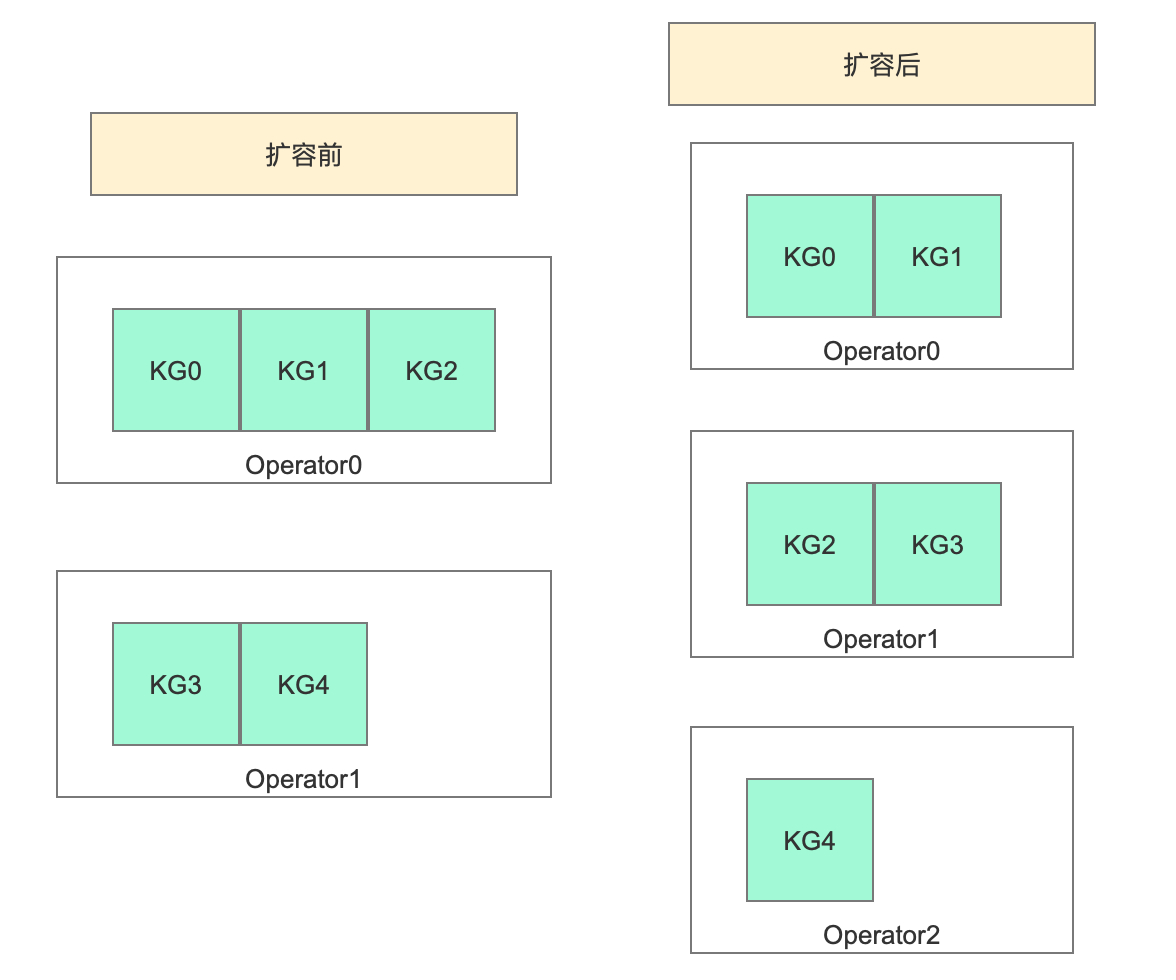
集群扩容后,并行算子数量增加。之前的持久化的状态现在恢复转移到新的算子中。key的数据条目,先映射到所属Key Groups编号,再通过Key Groups编号映射到对应机器上的并行算子。这个算子拥有之前Key-Group中所有的Keyed State。整个这条逻辑就保证的集群重启后,新来数据能找到之前的Keyed State。
具体示意图和算法
Key计算所属组算法
公式:key.hashCode() % N
N为组数。一句话就是先算Hash再取模数。这样所有的key都转换成0到N-1之间的数。
举例:key的hashCode为11,最大并行度是10,那么Key Group内会包含KG-0到KG-9。 11 % 10 = 1。那么这个key会分配到KG-1中。
Key-Group分配到并行算子算法
原则是尽可能均匀将Key-Group分给Operator。Flink采用最简单粗暴的方式。除以算子并行度,整除部分直接可以均匀分配,余数部分逐一分给前N个算子。
举例:假如有Key-Groups有8组,算子并行度为3,8 / 3 = 2 余 2。前2个Operator分配3个Key-Group,剩下1个Operator分配2个Key-Group。Key-Group和Operator是对齐的,即编号小的KG在编号小的Operator里。
Key Groups模式的限制
最大并行度限制
截止到Flink1.9版本,Key Groups的组数在任务第一次启动后不可无代价改变。
Checkpoint的状态快照根据Key Groups编号分组保存。一旦Key Groups数量变化,目前版本Flink无法映射到之前的Checkpoint状态快照。会导致所有状态快照会失效。
由于Key Groups的这个特性,引出最大并行度概念,Key Groups的组数就等于最大并行度。也就是不改变Key Groups组数的前提下,并行度最大只能和Key Groups数相等。如果超过相当于有Operator分不到Key Group变成空转。启动Job时Flink会直接报错。
Flink Job Manager中会打印如下报错日志。
Caused by: org.apache.flink.runtime.JobException: Vertex Map’s parallelism (4) is higher than the max parallelism (2). Please lower the parallelism or increase the max parallelism.
存在最大并行度限制的原因
如果最大并行度变动,Checkpoint不失效,那么在集群启动时,要把所以Key Groups编号重新计算。有时Keyed State是相当大的,重新计算所有Keyed State所属组编号会耗费很长的启动时间。截止Flink1.9版本还不支持这个功能。未来的Flink有可能会加入,即使加入了,使用时也要注意集群启动耗时问题。
具体使用
最大并行度取值
设置代码如下
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();ExecutionConfig executionConfig = env.getConfig();executionConfig.setMaxParallelism(4);
如果没有手动设置则按照以下规则:
默认值第一次启动时设置:
- 当任务并行度小于 128 时,最大并行度默认是 128。
- 任务并行度大于等于 128 时,最大并行度取值为:parallelism + (parallelism / 2) 不会大于 2^15 = 32768
注意
调高最大并行度产生更多Key Groups组数,使状态元数据增大,Checkpoint快照也随之增大,降低性能。
所以要在满足业务的前提下设置尽可能小的最大并行度。

若有收获,就点个赞吧
0 人点赞
