状态使用
实现有状态算子
从使用角度讲可以把状态分为系统状态和自定义状态。系统状态是Flink算子自带的,比如Window内置的状态存有相关数据供触发计算时计算(比如窗口时间到了会触发聚合操作)。
下面将详细讲述用户自定义状态。
状态类型
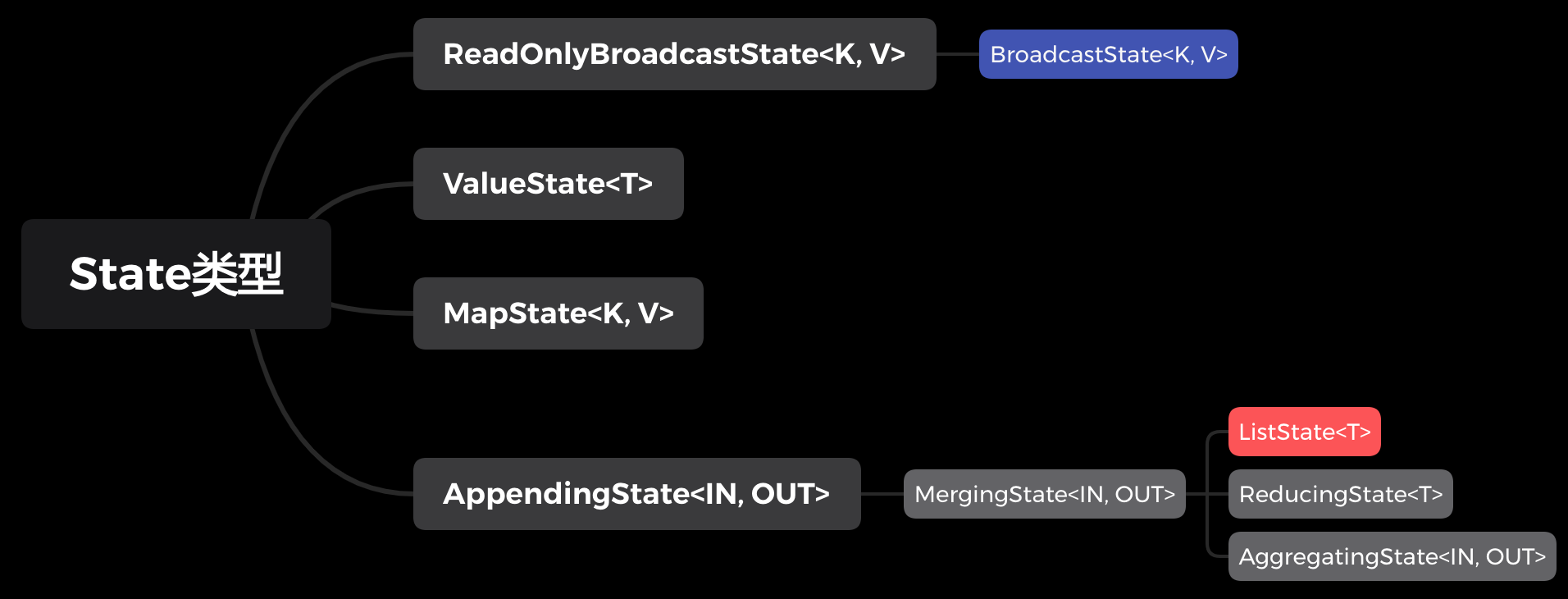
Flink内置了多种不同类型的状态,可供用户按需使用。
下图是各种状态的继承关系图。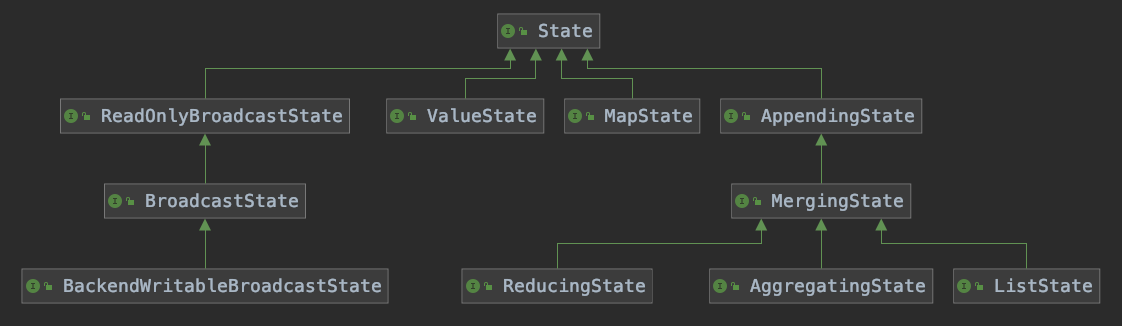
总结一下上图:
- ListState是Keyed State和 Operator State共有。
- BroadcastState是Operator State独有。
- 其他都是Keyed独有。
使用实例介绍
Keyed State示例
https://github.com/deadwind4/flink-training/blob/master/src/main/java/me/training/flink/state/Average.java
上诉代码中map回调函数相当于作用当前记录。
也就是说每条记录过来只会修改所对应的key的sum值(ValueState)。不同key之间彼此是隔离的。
Operator State示例
三个要点:
- 使用Operator State要实现CheckpointedFunction或ListCheckpointed接口。
- 这两个接口都有一个共性就是都要实现,做Checkpoint和从Checkpoint中恢复的两个逻辑。
- Opertator State全部都是类似List的类型,目的是扩容之后可以把List中的每个元素均匀分配给所有并行算子。
实现CheckpointedFunction接口
https://github.com/deadwind4/flink-training/blob/master/src/main/java/me/training/flink/state/BufferingSink.java实现ListCheckpointed接口
https://github.com/deadwind4/flink-training/blob/master/src/main/java/me/training/flink/state/CounterSource.java
配置
StateBackend(状态后端)选择
不同后端的区别如下图。状态后端主要在做Checkpoint时快照存储的方式不同,存储状态时差别不大。RocksDB的Keyed State存在RocksDB,防止Keyed State过大。
设置Time-To-Live (TTL)
为了防止Keyed State随时间增长过于巨大,所以引入TTL机制,设置时间定期清理状态。
设置实例代码如下:
import org.apache.flink.api.common.state.StateTtlConfig;import org.apache.flink.api.common.state.ValueStateDescriptor;import org.apache.flink.api.common.time.Time;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);stateDescriptor.enableTimeToLive(ttlConfig);
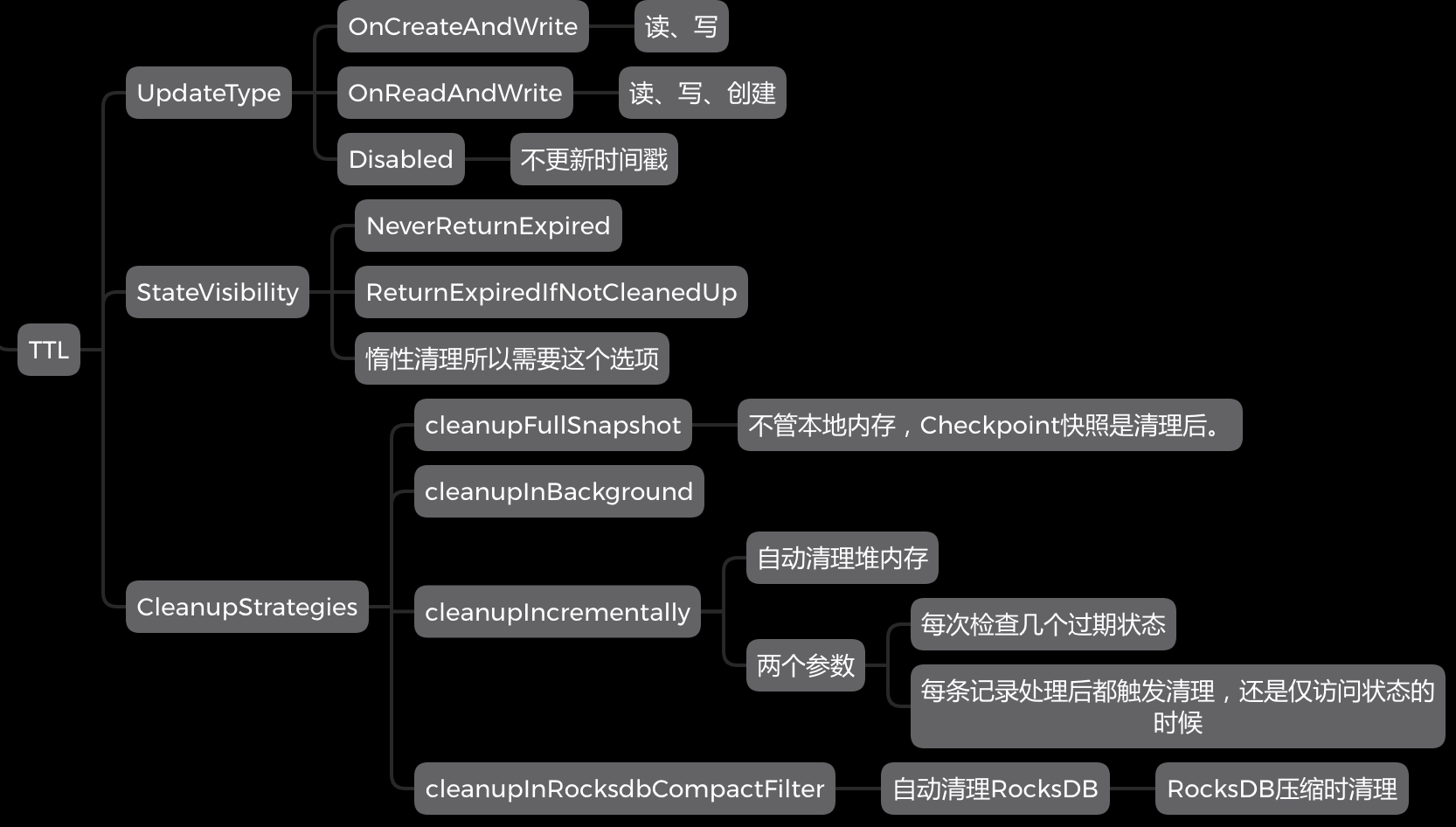
配置除了时间外还包含3个选项:
- UpdateType:设置刷新类型。OnReadAndWrite选项是指Read、Write、Create都刷新倒计时。
- StateVisibility:配置过期但还没被清除的数据是否可见。由于清理过期数据是惰性的,不是过期了马上就没,可能到定期清理时才会消失。为了满足业务需求,所以添加这个选项。
- CleanupStrategies:清理策略。
- cleanupFullSnapshot策略内存中状态并不会被清理,只是做Checkpoint的快照时快照清理后变小了。
- cleanupIncrementally策略特定条件触发后检查N个状态,如过期则触发清理。
- cleanupRocksdbCompactFilter策略在RocksDB定期压缩时清理。
额外知识点:
TTL时间设置的源码加入了整数溢出保护。具体如下。
public static boolean expired(long ts, long ttl, long currentTimestamp) {return getExpirationTimestamp(ts, ttl) <= currentTimestamp;}private static long getExpirationTimestamp(long ts, long ttl) {long ttlWithoutOverflow = ts > 0 ? Math.min(Long.MAX_VALUE - ts, ttl) : ttl;return ts + ttlWithoutOverflow;}
特殊的广播状态
作用,把数据流甲的每个数据广播到流乙。
广播状态是Operator state的一种,但用法特殊一点。
使用广播状态只需要三步。
- 创建BroadcastStream。
- 调用connect()与事实数据流DataStream连接。
- 调用process()使用ProcessFunction实现接收到广播的处理逻辑。
应用场景:动态更新配置。向甲数据流发送配置,广播到乙数据流,乙数据流根据配置修改代码逻辑。
//TODO 示例
状态故障恢复
概述
状态故障恢复使用Checkpoint机制。核心思想就是定期保存数据,故障后从保存的数据中恢复曾经的状态。
这种机制必须借助外部持久化存储系统。
需要两部分配备持久化存储:
- 数据源(Source)是持久化系统,意味着可重放(例如Kafka)。
- 状态定期存储到持久化系统(例如HDFS)。
将整个数据流划分成一个又一个阶段
故障恢复的两种模式
exactly-once:准确恢复状态值,不多不少。
at-least-once:恢复状态值后可能会变多。
at-least-once存在的意义是很多场景并不需要计算的数值非常准确。例如,一些海量日志处理,一段时间内报警10001次和10002次数量级是一样对最终的业务没有影响。使用at-least-once可以降低延迟。具体降低延迟的原理后面讲述。
配置注意事项
config``.``setMinPauseBetweenCheckpoints``(``500``);
这个选项是设置两次Checkpoint见最小的时间间隔。为了防止单次Checkpoint时间过长,刚做完,就开始做下次Checkpoint,导致Flink处理数据效率下降,甚至压根就不处理,一直在做无意义的Checkpoint。
而且如果不配置这个值,会导致做检查点的时间重叠,会出现并发做多个。
示意图如下,绿框代表做Checkpoint的时间,空白代表正常处理数据的时间。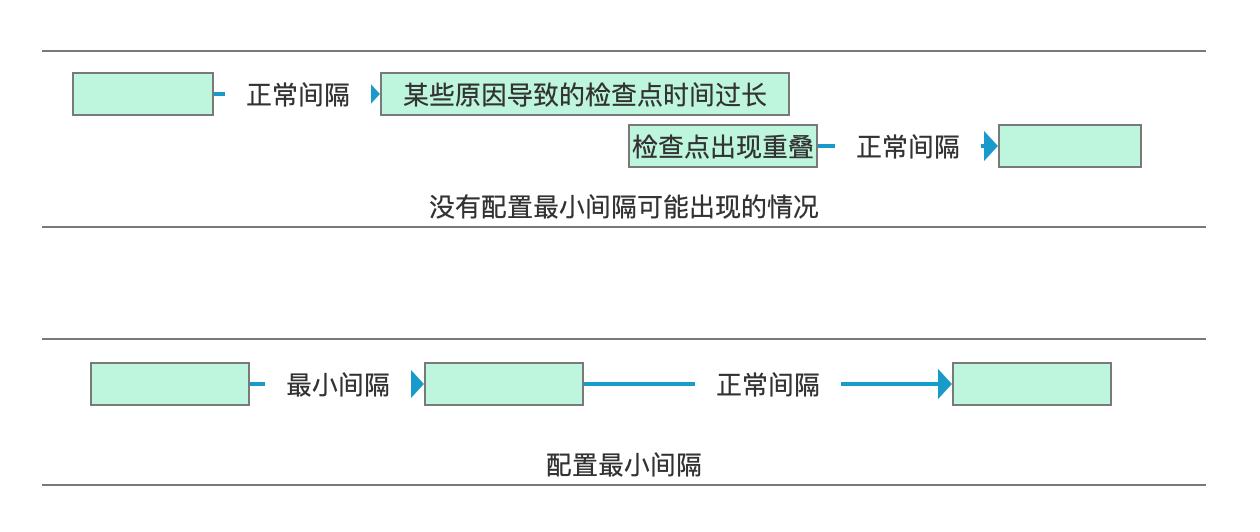
集群扩容再分配
总体核心思想就是均匀分配,根据线程数取模。只是两种Operator State和Keyed State取模细节不一样,核心原理是一样的。
Keyed State再分配
Key Groups重新均匀分配到所有并行算子上。
Key Groups详细介绍
Operator State再分配(Redistribute)
两种方式
Even-split redistribution:
重启后均匀分配到每个算子。
Union redistribution:
重启后每个算子获得所有状态。这个不造咋用就不能乱用,会导致每个节点的State线性增长,撑爆内存。
广播状态每个算子都一样所以再分配就在所有算子里都复制一遍。

若有收获,就点个赞吧
0 人点赞
