概述
本文基于1.12版本。在企业中基于Flink做二次开发,扩展编写新的Connector这个知识一定是要熟练掌握的。
Flink会通过SPI机制扫描所有Factory实现类。所以实现Connector的第一步就是实现Factory。
SQL 中的Connector 主要是实现接口DynamicSourceTableFactory DynamicSinkTableFactory这两个Factory的子接口。
这个地址中有个File Sink Connector,是最精简的Connector了。所有复杂的代码都可以从中衍生出来。可以先学习这个最简单的。
https://github.com/deadwind4/luna-flink/tree/master/flinkx-connectors/flinkx-connector-file
Connector编写两个重要部分
- 启动时执行的代码
- 运行时执行的代码
下面将详解讲解每个相关类以及关键节点的实现。
一、启动时代码实践
启动时主要是在Client端执行,主要就是两个类DynamicTableFactory和DynamicTableSource/Sink。
DynamicTableFatory类
Source Sink Lookup三种表创建的统一入口,命名XxxDynamicTableFactory。
这个类只做三件事:配置DDL选项、校验用户输入的选项、创建DynamicTableSource/Sink。
1、DDL选项配置
DDL配置选项只需要实现如下3个方法即可。
- factoryIdentifier():Connector唯一标识
- requiredOptions():必选项
- optionalOptions():可选项
factoryIdentifier()方法返回值就对应SQL语句中的connector选项。用于识别唯一的connector。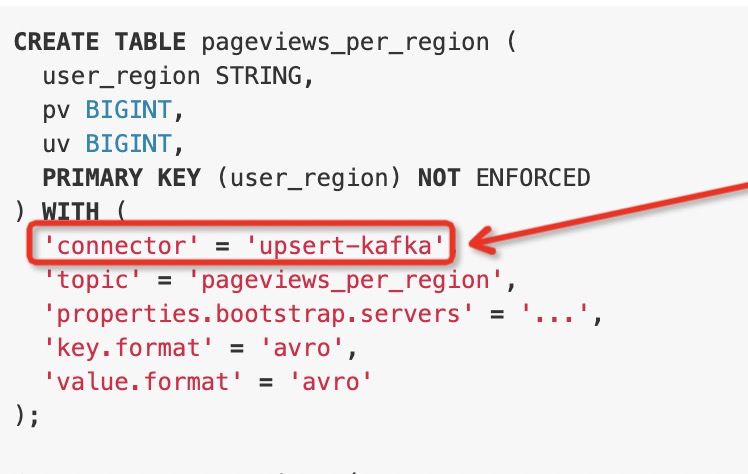
ConfigOption类
除了’connector’之外的选项都是ConfigOption类型。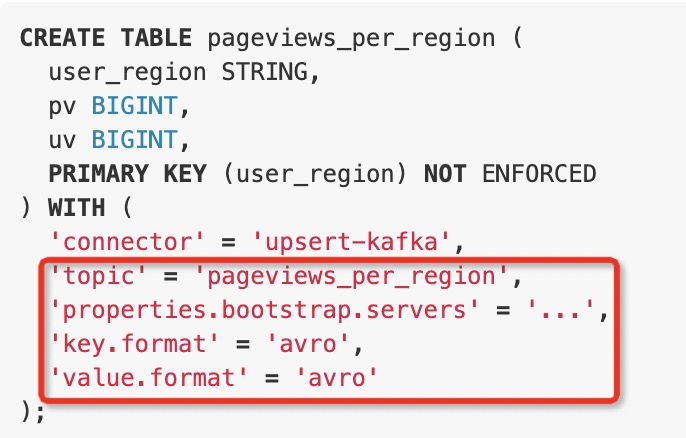
public static final ConfigOption<String> URL =ConfigOptions.key("url").stringType().noDefaultValue().withDescription("the jdbc database url.");
2、校验选项值并且创建DynamicTableSource/Sink
createDynamicTableSource/Sink方法的实现
- 提取并校验选项
- *获取format
- 创建DynamicTableSource/Sink
选项相关的三段关键代码
提取选项
final TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);final ReadableConfig tableOptions = helper.getOptions();
通过官方工具函数校验选项
// Flink JDBC Connectorhelper.validate();// Flink Kafka Connectorhelper.validateExcept(PROPERTIES_PREFIX);
自定义方法校验选项
// Flink JDBC ConnectorvalidateConfigOptions// Flink Kafka ConnectorvalidatePKConstraints
整体样例,原子JDBC Connector
@Overridepublic DynamicTableSink createDynamicTableSink(Context context) {final FactoryUtil.TableFactoryHelper helper =FactoryUtil.createTableFactoryHelper(this, context);final ReadableConfig config = helper.getOptions();helper.validate();validateConfigOptions(config);JdbcOptions jdbcOptions = getJdbcOptions(config);TableSchema physicalSchema =TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());return new JdbcDynamicTableSink(jdbcOptions,getJdbcExecutionOptions(config),getJdbcDmlOptions(jdbcOptions, physicalSchema),physicalSchema);}
其他
*Format获取
有些Connector需要获取Format,例如Kafka
return helper.discoverOptionalDecodingFormat(DeserializationFormatFactory.class, FactoryUtil.FORMAT).orElseGet(() ->helper.discoverDecodingFormat(DeserializationFormatFactory.class, VALUE_FORMAT));
TableFactoryHelper工具类
helper 里会存储表配置信息等。不仅仅只是个工具方法集合。
DynamicTableSource/Sink类
主要用途只有一个:创建SinkRuntimeProvider
DynamicTableSink的作用是创建DynamicTableSink;DynamicTableSink的作用是创建SinkRuntimeProvider;而SinkRuntimeProvider有如下三种子接口。
- DataStreamSinkProvider
- OutputFormatProvider
- SinkFunctionProvider
也就是说 OutputFormat、SinkFunction、DataStream这三个类都可以直接对接Flink SQL的DDL语句。
JDBC Connector源码片段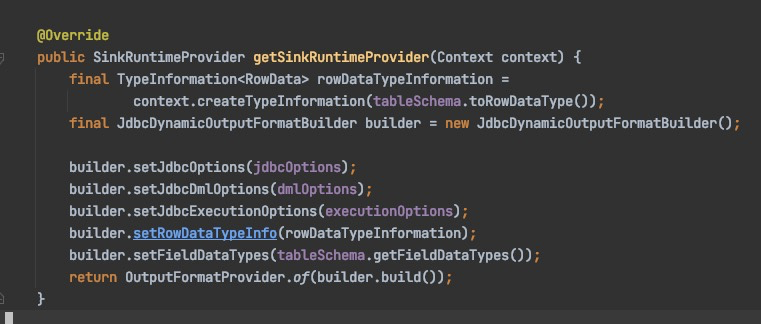
HBase Connector 源码片段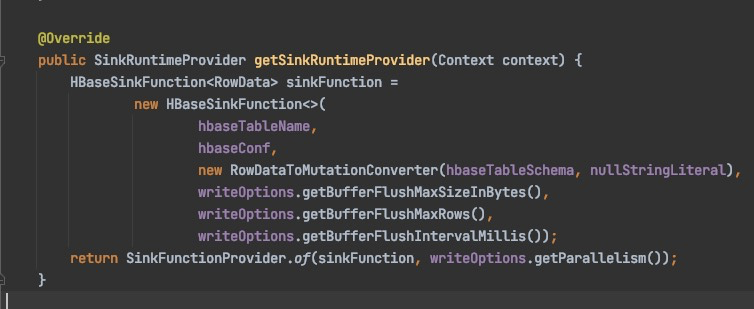
如下4个方法直接参照其他Connector编写即可。
- copy()
- asSummaryString()
- equals()
- hashCode()
二、运行时(Runtime)代码实现
运行时代码实现,主要就是序列化和反序列化RowData。创建的 Scan/SinkRuntimeProvider 内部就是运行时代码实现了,也可以看作是DataStream API代码逻辑。
数据类型使用介绍
DataType、LogicType、RowData之间的关系:利用DataType中的LogicType这个元数据类,读写RowData中的数据。
换一个角度:从TableSchema中获取DataType。从DataType获取LogicType。用LogicType生成RowData转换器。
1、RowData类型介绍
何为RowData
真正在Flink Runtime算子间传递的对象。可以简单理解成数组,只有索引和数据。内部字段不带数据类型等元信息。
RowData本身不包含Schema信息。解析的时候要使用外部Schema信息。本质只是对一块连续内存的封装。
为何需要RowData
Connector对RowData的操作
把JSON转成RowData。把RowData拼接成SQL插入数据库。
2、LogicType类型介绍
一个子类就是一个SQL类型,其他一概不管。下图红框中的每一项都对应一个LogicType子类。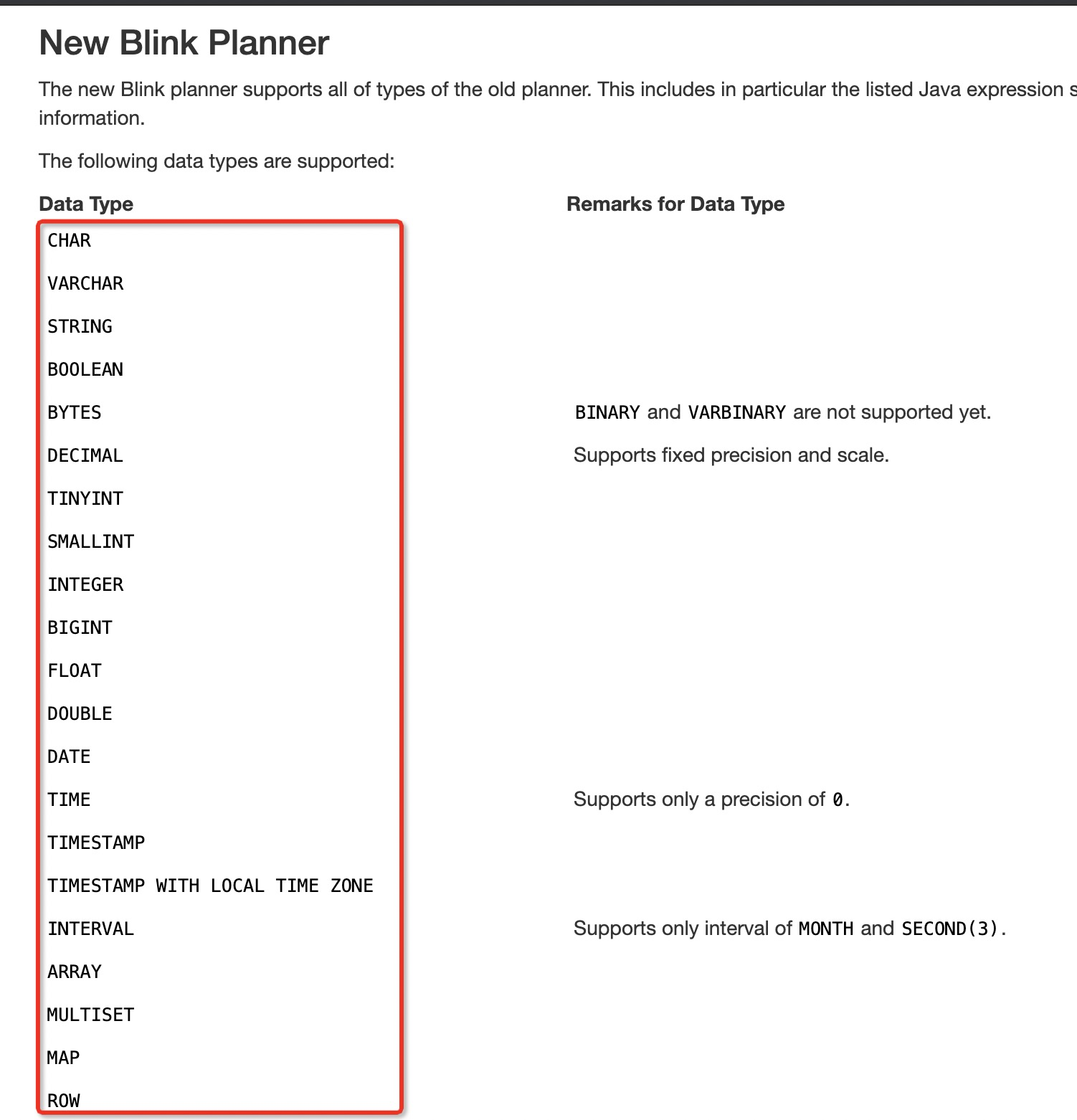

3、DataType类型介绍
DataType绑定一个LogicType。
DataType只有4个子类。
LogicType对应FlinkStreamSQL这个代码。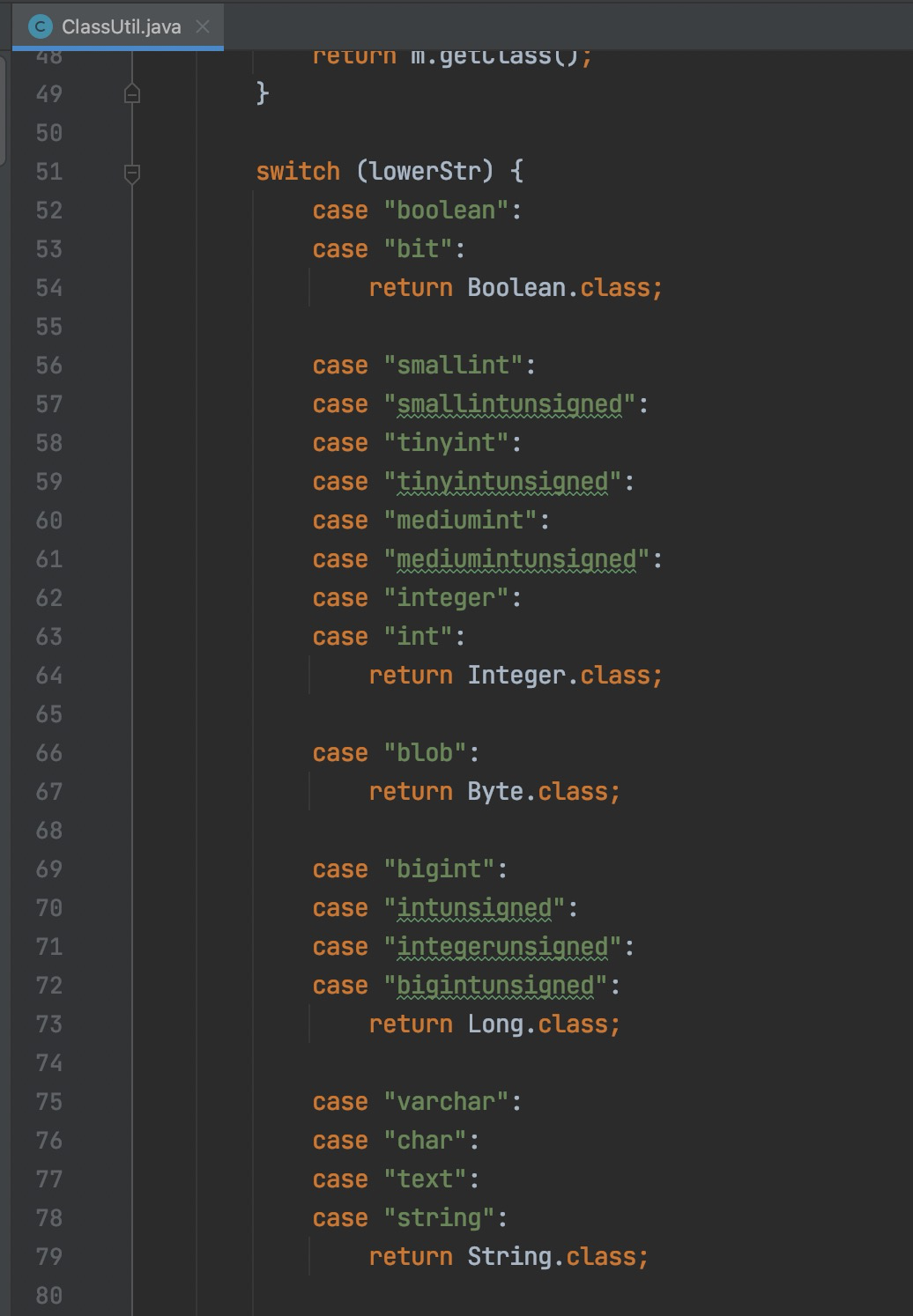
运行时最关键的
Converter类
此类作用利用LogicType读写RowData数据,此类命名不是Flink强制规定,但是大家约定俗称为Converter。
可以参考源码中json format包的JsonToRowDataConverters类。
下图是JDBC Connector 源码片段: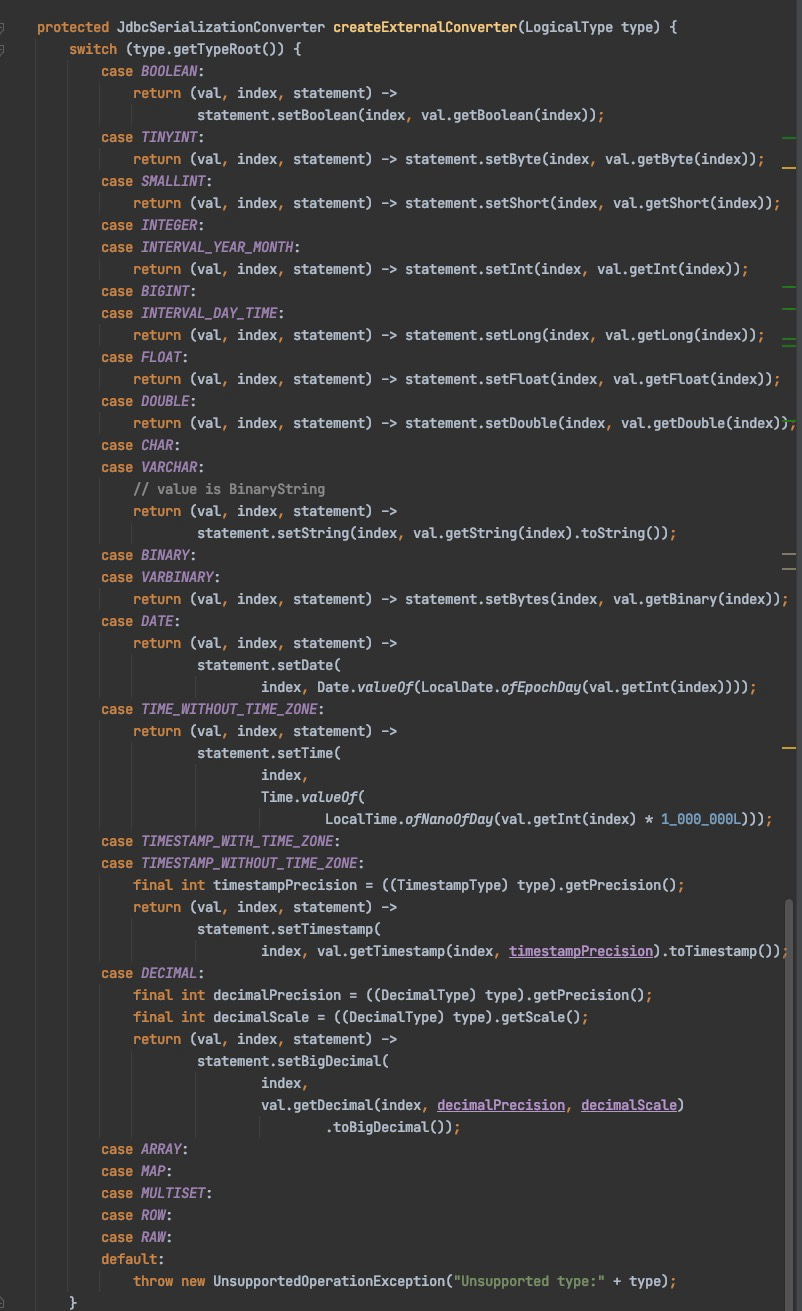
常用代码整理
DataType转换TypeInfomation
final TypeInformation<RowData> rowDataTypeInformation =context.createTypeInformation(tableSchema.toRowDataType());
DataType与LogicType与RowData配合
遍历出LogicType
final LogicalType[] logicalTypes =Arrays.stream(fieldDataTypes).map(DataType::getLogicalType).toArray(LogicalType[]::new);
获取物理列Schema
TableSchema physicalSchema =TableSchemaUtils.getPhysicalSchema(context.getCatalogTable().getSchema());
StringData类型
StringData是Flink自己封装的String,底层是内存块。
数据存入GenericRowData要使用StringData
// 将String转换成StringDataStringData.fromString()
附录(以下可以先不看)
Format
如下两个方法SPI加载Format
FactoryUtil.TableFactoryHelper helper;DecodingFormat<DeserializationSchema<RowData>> deFormat = helper.discoverOptionalDecodingFormat(DeserializationFormatFactory.class, FactoryUtil.FORMAT)EncodingFormat<SerializationSchema<RowData>> enFormat = helper.discoverOptionalEncodingFormat(SerializationFormatFactory.class, FactoryUtil.FORMAT)
FactoryUtil类
使用此类的三大目的:获取DDL配置项,校验DDL配置项,获取SPI注册的Format。
基本所有Connector共用的字段在FactoryUtil中都提供了,可以直接获取使用。例如format、sink.parallelism、key.format、value.format
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);final ReadableConfig tableOptions = helper.getOptions();
此类中有DDL配置字段的校验方法。非常灵活巧妙。
TableHelper类
包命名规范
com.xxx.flink.connectors.jdbccom.xxx.flink.connectors.jdbc.table
包名com.dtstack.flink.connectors.*.table 是Connector SQL使用部分。
OutputFormat是对写入外部系统这个动作本身进行抽象。
插件加载步骤
- SPI指定Classloader加载并new出全部Factory()
- 根据父接口过滤 例如:DeserializationFormatFactory
- 根据identifier最终锁定。
PlannerBase Scala类中传递的SPI ClassLoader
其他细节备忘
调度采用子进程模式
使用大量的FactoryUtil
Flink使用Guava是直接把Precondition的源码复制过来用,减少依赖。
ChangelogMode
主键校验
Only INSERT没有主键
如果是Only INSERT 不做任何处理,如果不是会根据Key进行分区。保证同一个Key都汇聚到同一个并行度。
DataSteam部分
DecodingFormat 启动时
DeserializationSchema 运行时
与之前版本的区别
新版本用DynamicSinkTableFactory DynamicTableSink 代替之前TableFactory和TableSink。
更巧妙的地方在于所有Flink插件(Connector以及JSON等序列化器)全部继承自接口Factory。通过SPI加载,统一接口全部管控。

若有收获,就点个赞吧
0 人点赞
