HDFS2.0架构图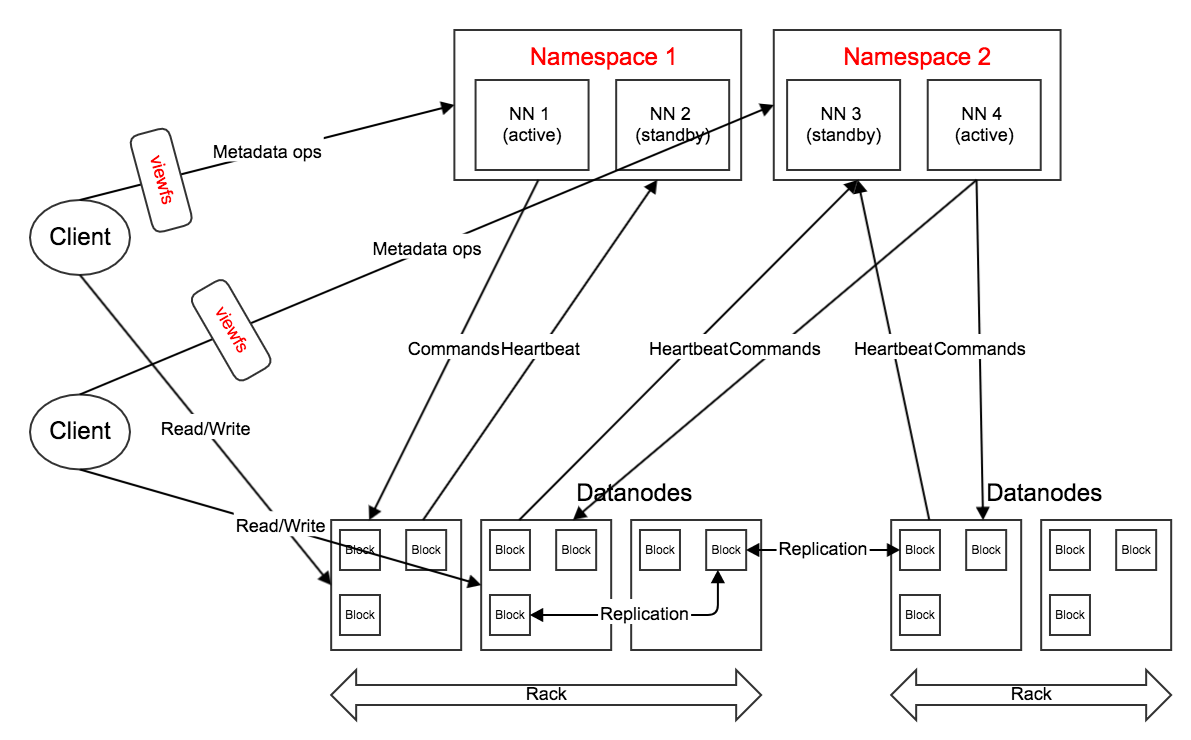
其他
小文件合并
hadoop fs -cat hdfs://path/*.txt | hadoop fs -appendToFile - hdfs://newpath/hdfs.txt
block
文件上传前需要分块,这个块就是block,一般为128MB。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
block id
BP-1034052771-172.16.212.130-1405595752491:blk_1075892982_2152381
block 长度
Block 副本数
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
机架感知(Rack-aware)
默认不开启。机架感知脚本接收IP返回RackID(例如Rack1)
<property><name>topology.script.file.name</name><value>/path/to/script</value></property>
*Federation
HDFS Federation采用了经典的Client Side Mount Table。
解决NameNode单点问题的水平横向扩展方案。
目的突破NameNode内存瓶颈。每个NameNode管理名字空间的一部分。例如(甲NameNode管理/foo,乙管理/bar)。
Namenode维护一个namespace volume(命名空间卷)里面包含命名空间元数据和Block Pool两部分。
namespace volume彼此独立,Datanode要向所有Namenode注册。
Federation将多个Namespace合并为一个视图,用户可通过viewfs访问。
Block Pool
Cluster ID
NameNode格式化(formated)会创建新的Cluster ID
Quorum Journal Manager
NFS不能保证只有一个Namenode写,所以推荐使用QJM。
安全模式
ViewFS
管理多个 namespace
访问/foo/bar
会读core-site.xml等于访问hdfs://nnhost:9000/foo/bar
<property><name>fs.defaultFS</name><value>hdfs://nnhost:9000</value></property
多个集群,每个集群有多个NN每个NN有自己的NS。
ViewFS实现了所有HDFS的接口,用户使用起来完全透明。
<property><name>fs.default.name</name><value>viewfs://clusterX</value></property>

若有收获,就点个赞吧
0 人点赞
