DataStream
Function接口
计算逻辑
Map 等算子都是
�
org.apache.flink.streaming.api.operators包
StreamOperator接口
AbstractStreamOperator#initializeState类。
双流JOIN StreamingJoinOperator类中。
状态
程序入口
Client
执行bin/flink run xxx会调用CliFrontend类的run方法。
FlinkYarnSessionCli
YarnSessionClusterEntrypoint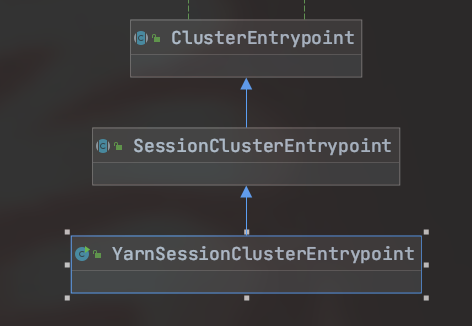
YarnJobClusterEntrypoint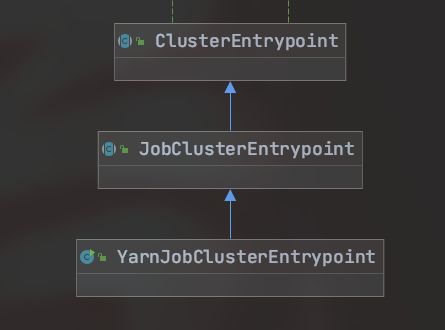
1.12 以上
env.execute("Streaming WordCount SideOutput");
下面代码会进行分流
CompletableFuture<JobClient> jobClientFuture =executorFactory.getExecutor(configuration).execute(streamGraph, configuration, userClassloader);
到底是使用yarn或k8s的什么模式。一个模式实现一个PipelineExecutor接口。
public interface PipelineExecutor {/*** Executes a {@link Pipeline} based on the provided configuration and returns a {@link* JobClient} which allows to interact with the job being executed, e.g. cancel it or take a* savepoint.** <p><b>ATTENTION:</b> The caller is responsible for managing the lifecycle of the returned* {@link JobClient}. This means that e.g. {@code close()} should be called explicitly at the* call-site.** @param pipeline the {@link Pipeline} to execute* @param configuration the {@link Configuration} with the required execution parameters* @param userCodeClassloader the {@link ClassLoader} to deserialize usercode* @return a {@link CompletableFuture} with the {@link JobClient} corresponding to the pipeline.*/CompletableFuture<JobClient> execute(final Pipeline pipeline,final Configuration configuration,final ClassLoader userCodeClassloader)throws Exception;}
SQL
http://aitozi.com/BinaryRow-implement.html
源码解释

若有收获,就点个赞吧
0 人点赞
