总述
仔细分析的话会发现,sort merge join的代价并不比shuffle join小,反而是多了很多。那为什么SparkSQL还会在两张大表的场景下选择使用sort merge join算法呢?
这和Spark的shuffle实现有关,目前spark的shuffle实现都基于sort based shuffle算法,因此在经过shuffle之后partition数据都是按照key排序的。因此理论上可以认为数据经过shuffle之后是不需要sort的,可以直接merge。
综上所述:基于sort based shuffle,sort merge join和hash join 成本差不多大。 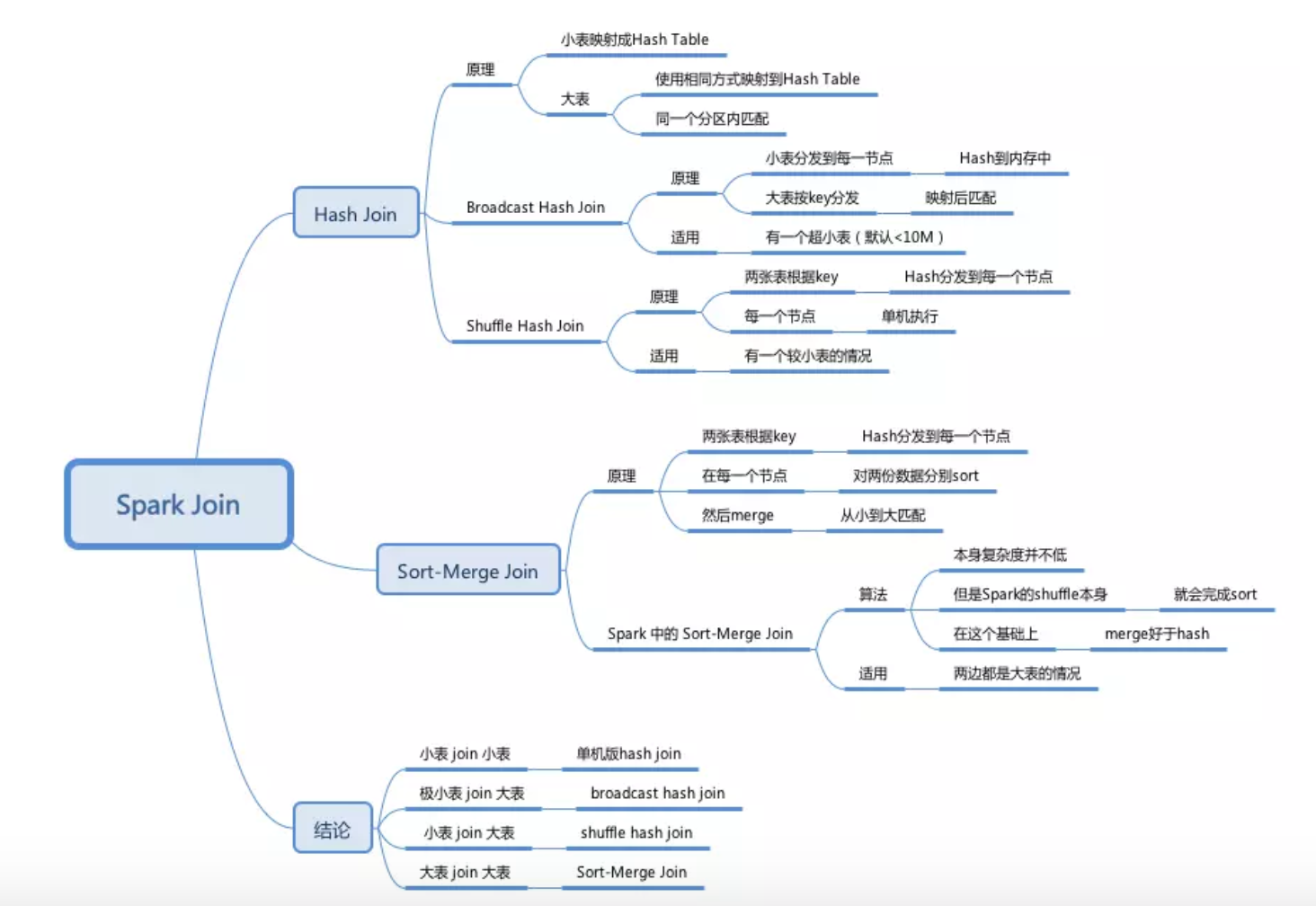
hash-join
broadcast join
1.broadcast阶段:
将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给driver,driver再统一分发给所有executor;要不就是基于BitTorrent的TorrentBroadcast。
2. hash join阶段:
在每个executor上执行单机版hash join,小表映射,大表试探。
shuffle join
1.shuffle阶段:
分别将两个表按照join key进行hash分区,将相同join key的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为shuffle。
2. hash join阶段:
每个分区节点上的数据单独执行单机hash join算法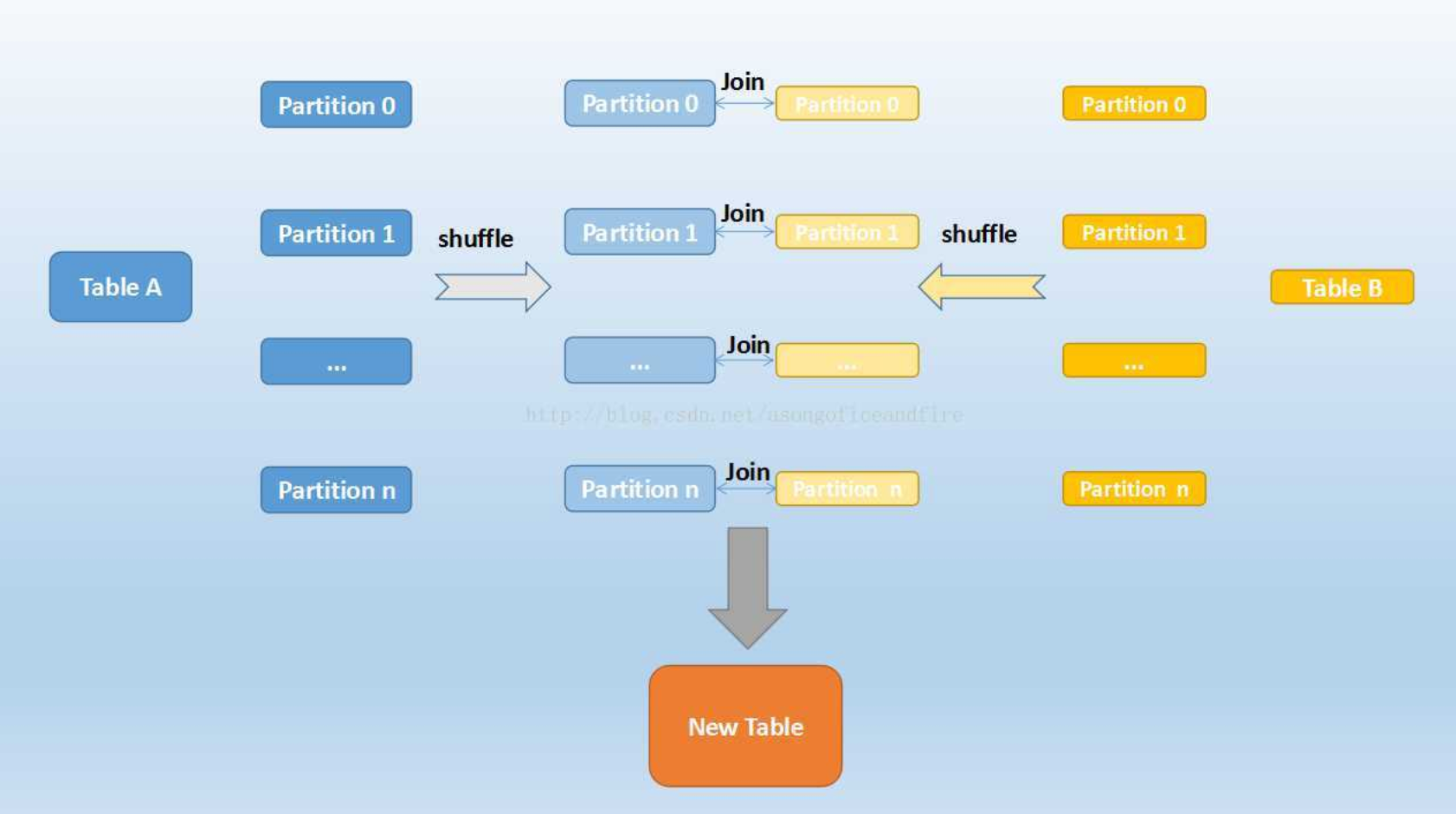
sort merge join
1. shuffle阶段:
将两张大表根据join key进行hash分区,两张表数据会分布到整个集群,以便分布式并行处理。
2. sort阶段:
对单个分区节点的两表数据,分别进行排序。
3. merge阶段:
对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列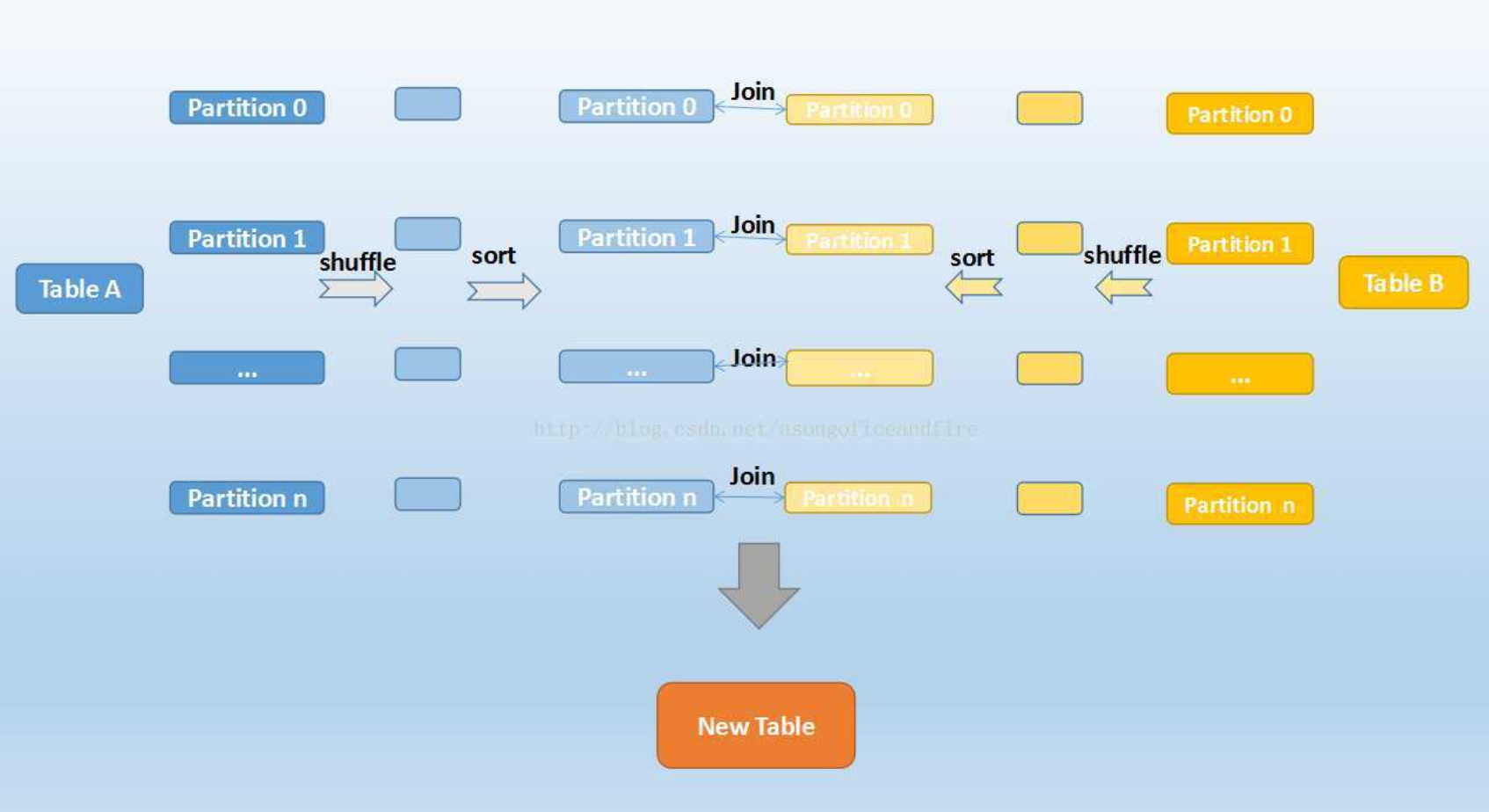

若有收获,就点个赞吧
0 人点赞
