分区数优化
cpu个数决定并行度、task个数决定分区数。所以这里的标题叫分区数优化 而不是并行度优化
- 数据倾斜的本质是某个key的数据量过大,经过shuffle都聚到同一个task了,所以这单纯加大分区数是没用的,并不能解决数据倾斜
- 由于sparksql分区数由 HDFS文件的split个数 决定。如果文件数少 且数据量大的时候,可以读数据后进行reparation
- spark.sql.shuffle.partitions # DF DS的分区数设置。shuffle分区个数 也就是task个数。默认200,需要修改为总核数的2-3倍
spark.default.parallelism # RDD的分区数设置
输出小文件过多
coalesce(1) 本算子所在的stage只有一个task
- 本着合并小文件、文件块大小为128M、gzip压缩不可切割 的情况下。 在知道文件很小的情况下 可以用coalesce(1), 若输出数据总大小超过128M 则coalesce(总大小/128M)
SELECT /+ COALESCE(3) / FROM t
SELECT /+ REPARTITION(3) / FROM t;
- distribute by XXX:
谓词下推
.config(‘spark.sql.adaptive.localShuffleReader.enabled’, True)
NodeManager中一个长期运行的辅助服务,通过该服务来抓取shuffle数据,减少了Executor的压力。用于提升Shuffle计算性能
.config(‘spark.shuffle.service.enabled’, True)
默认true: 写入hdfs成功会生成SUCCESS文件。改为false
.config(‘mapreduce.fileoutputcommitter.marksuccessfuljobs’, False)
默认true:使用spark parquet serde;false:使用hive serde. hive和spark的parquet约定不一致,使用spark写hive表会出错
.config(‘spark.sql.hive.convertMetastoreParquet’, False)
hive动态分区
.config(‘hive.exec.dynamic.partition’, True) .config(‘hive.exec.dynamic.partition.mode’, ‘nonstrict’) .config(‘hive.exec.max.dynamic.partitions’, ‘100000’) .enableHiveSupport() )
再加下面其他的参数
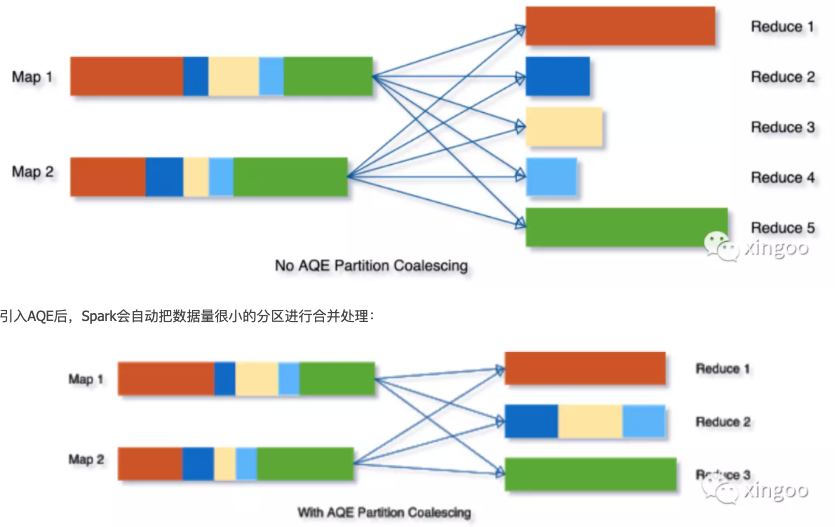
动态资源分配- CDH中默认开启,Apache默认不开启。- 所以在cdh中会有指定submit资源不起作用 而是自动分配。 一个任务可能8G内存就好 CDH给分配10G 会有点资源浪费。- 集群资源充足时,可将动态分区合并和动态分配资源结合使用- 开启动态分配资源后,submit时设置的excutor-number、core、memory将不起作用,而是自动根据数据量设置.config('spark.dynamicAllocation.enabled', True) <br />.config('spark.dynamicAllocation.shuffleTracking.enabled', True) #文件跟踪<a name="tZ4cZ"></a>### spark3.0<a name="My78a"></a>#### exlpain优化- exlpain **formatted **select * from table 加formatted可以简洁的展示出执行计划<a name="Uhl7n"></a>#### join type hint- broadcast join开启- sparkSession.sql("select /*+ BROADCASTJOIN(school) */ * from student left join school on student.schoolid=school.id").show- spark.table("src").join(spark.table("records").hint("broadcast"), "key").show()- shuffle hash join开启- sparkSession.sql("select /*+ SHUFFLE_HASH(school) */ * from student left join school on student.schoolid=school.id").show- sort merge join开启- sparkSession.sql("select /*+ SHUFFLE_MERGE(school) */ * from student left join school on student.schoolid=school.id").show<a name="ACYjI"></a>#### AQE 自适应查询- CBO优化中 开始会根据数据的统计信息进行代价计算。AQE就是执行过程中 还会多次进行代价计算 多次动态调整执行计划。- .config('spark.sql.adaptive.enabled', True)动态分区合并,解决小文件问题```shell# 默认true。根据运行时统计信息重新优化查询计划--conf spark.sql.adaptive.enabled=true \# 默认true。合并shuffle分区,减少小文件--conf spark.sql.adaptive.coalescePartitions.enabled=true \# 默认64M。合并小文件的大小,是分区的输入大小 此处的256M输出 orc-snappy约55M--conf spark.sql.adaptive.advisoryPartitionSizeInBytes=262144000 \# 默认true 自动的设置合并小文件的大小。 建议设置为false 以使用自配置的大小--conf spark.sql.adaptive.coalescePartitions.parallelismFirst=false \# 默认1M。合并分区后的最小size--conf spark.sql.adaptive.coalescePartitions.minPartitionSize =52428800 \
动态join策略选择
- 运行过程中调整join策略,比如filter之后小表满足broadcast join就广播
数据倾斜优化
- spark3.0之后可以做到自动检测数据倾斜、大表拆分
- 比如分区100个,每个分区的数据量从大到小排序 中位数是100M 最大值是550M,
- 那么 如果550M大于100M*5(第二条) 且550M大于256M(第三条),spark就判定为数据倾斜。
1.spark.sql.adaptive.skewJoin.enabled :是否开启倾斜join检测,如果开启了,那么会将倾斜的分区数据拆成多个分区,默认是开启的,但是得打开AQE。
2.spark.sql.adaptive.skewJoin.skewedPartitionFactor :默认值5,此参数用来判断分区数据量是否数据倾斜,当任务中最大数据量分区对应的数据量大于的分区中位数乘以此参数(5),并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes参数,那么任务此任务数据倾斜
3.spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes :默认值256mb,用于判断是否数据倾斜
动态分区裁剪
原理:join on id,左表对id进行filter,也会应用到右边。提前过滤部分数据
嵌套列的优化
Spark 2.4 对嵌套列(Parquet 和 ORC)不支持下推,需要读取所有的数据,然后再进行 Filter 操作。3.0嵌套列(map struct等)的裁剪支持所有的算子,包括repartitioin。大大减少了IO
额外篇:RBO、CBO
RBO
- rule based optimization 基于规则的优化器
- RBO对数据不敏感,不同的数据导致sql的性能不同
常见表现
cost based optimization 基于代价的优化器
- 原理:根据统计信息(数据量 文件大小 分区数 I/O cpu)、代价模型(cost model)计算各个执行计划的代价,即cost。从中选择代价最低的执行计划
- spark3.0 的AQE是基于CBO的
开启方式:spark.sql.cbo.enabled = true 默认false
spark.sql.cbo.joinReorder.enabled = true 默认false<br /> spark.sql.cbo.planStats.enabled = true

若有收获,就点个赞吧
0 人点赞
