DataNode
数据块在DN上的存储包括两部分:数据块本身、元数据(数据checksum、数据大小、时间戳)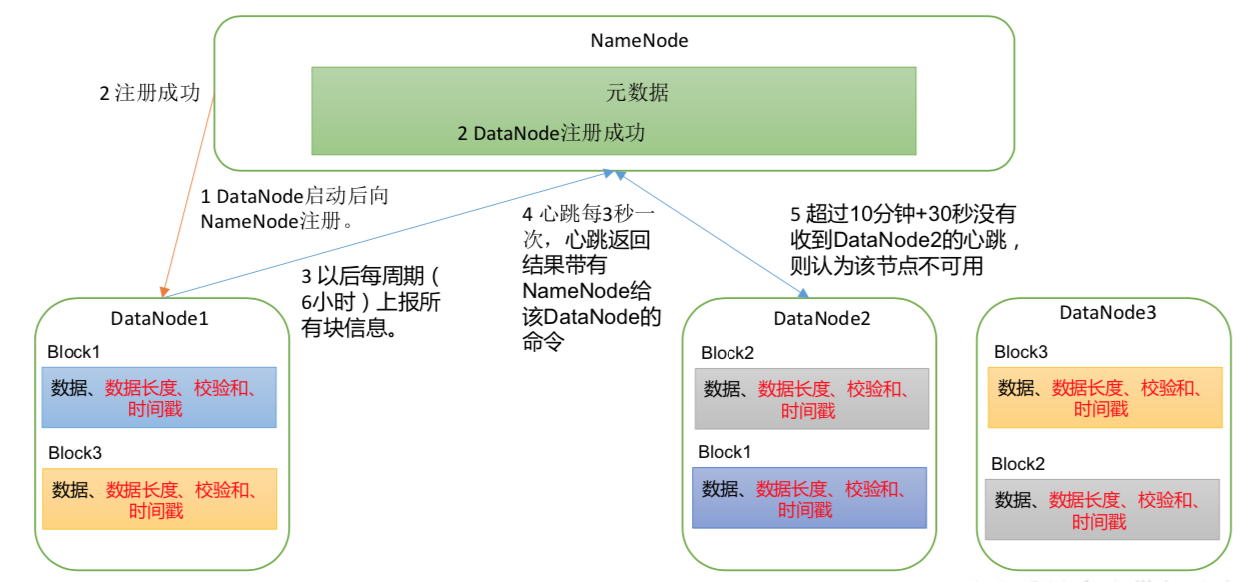
//超过10分半节点不通信 视为不可用节点。TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒//hdfs-site.xml<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property><property><name>dfs.heartbeat.interval</name><value>3</value></property>
//hdfs-site.xml//DN 向 NN 汇报当前块信息的时间间隔,默认 6 小时<property><name>dfs.blockreport.intervalMsec</name><value>21600000</value><description>Determines block reporting interval in milliseconds.</description></property>//DN扫描本节点块信息列表的时间间隔,默认6小时<property><name>dfs.datanode.directoryscan.interval</name><value>21600s</value></property>
NameNode
作用
- fsimage是检查点,是目录树,但是没有块对应的datanode信息(因为datanode会汇报块信息,namenode再把 block -> datanodes list 存储在BlocksMap的数据结构中)
- edits是操作日志
SecondaryNamenode
作用
1、帮助namenode合并 edits生成fsimage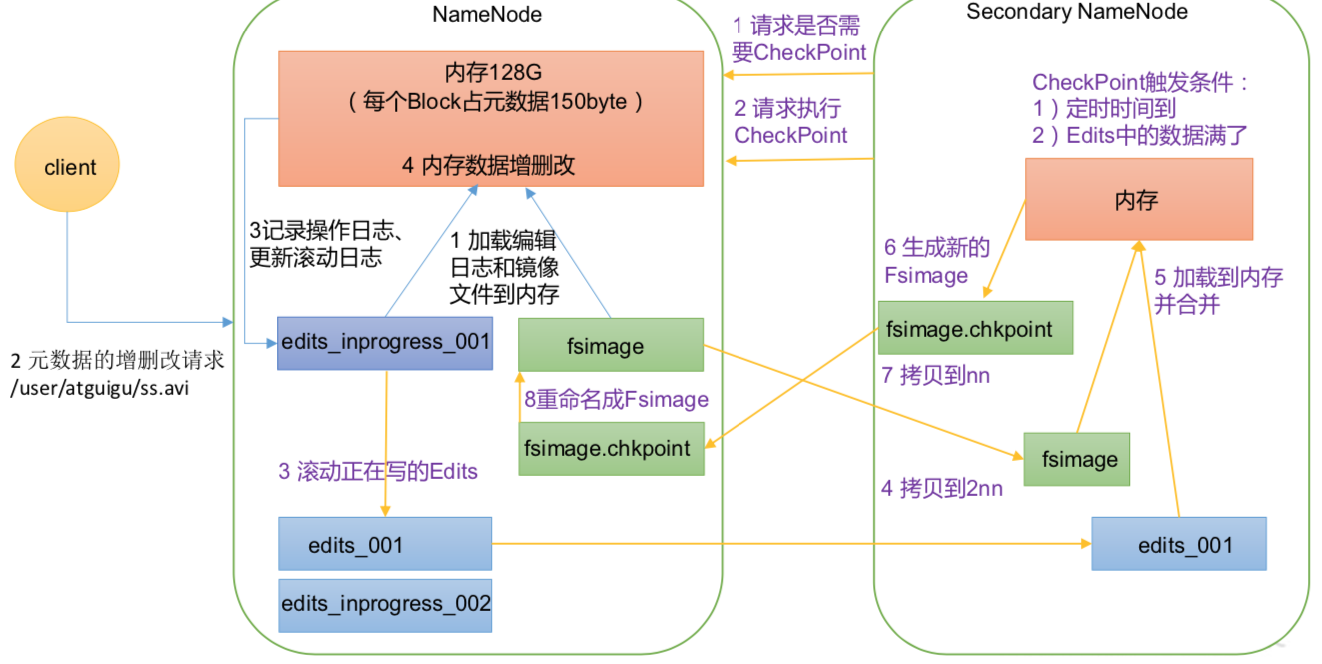
//hdfs-site.xml//每小时执行一次合并<property><name>dfs.namenode.checkpoint.period</name><value>3600s</value></property>//或操作次数达到100万执行一次合并<property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value></property>//1 分钟检查一次操作次数<property><name>dfs.namenode.checkpoint.check.period</name><value>60s</value></property>
HA
要点
- 元数据管理方式需要改变
两个namenode内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(journal和NFS两个主流实现);
- 需要一个状态管理功能模块
实现了一个zkfc,常驻在每一个namenode所在的节点,每一个zkfc负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfc来负责切换,切换时需要防止brain split现象的发生。
- 必须保证两个NameNode之间能够ssh无密码登录
- 隔离(Fence),防止脑裂即同一时刻仅仅有一个NameNode对外提供服务
1、ssh kill
2、shell脚本(用户自定义的一个脚本是断网还是断电,在ssh kill没有成功的情况下启动)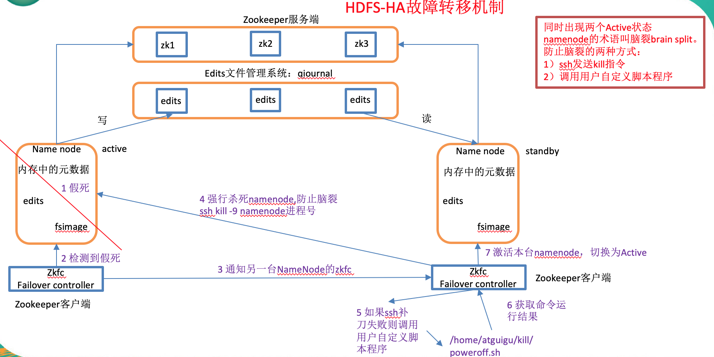
JournalNode
JN必须是奇数个,如3、5、7、9个等等。当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
1、active状态的NameNode的edits有任何修改时,会告知大部分的JournalNodes进程。
2、standby状态的NameNode只可读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的edits
3、standby可以确保在集群出错时,命名空间状态已经完全同步了
ZKFC
zkfc是Hadoop中通过ZK实现故障自动切换的一个实用工具。
FC是要和NN一一对应的,两个NN就要部署两个FC。它负责监控NN的状态,并及时的把状态信息写入ZK
1、zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点
2、active namenode失效之后,zkfc会先进行杀死本namenode操作 然后另一台zkfc会更改standby namenode状态为active

若有收获,就点个赞吧
0 人点赞
