检查点(checkpoint)
- 检查点保存:barrier的offset、状态
-
检查点的生成三部曲
barrier在上下游分区间的传递:广播到下游(watermark也一样)
- 1、由jobManager 在source阶段生成一批批的barrier
- 2、barrier是等待所有上游分区的 barrier都到齐,才进行checkpoint。专业名词叫【barrier对齐】,1.11版本之后可以设置取消barrier对齐(见下面代码框)。
- 三个source,jobManager生成了同一批barrier, ID为1,那么下游的sum算子要收到三个source ID1的barrier,才会进行checkpoint
- 3、状态后端在 状态存入检查点之后,会通知source任务、source任务会通知jobManager,检查点完成!
【barrier对齐】举个栗子:
先keyedBy 》》》sum》》》process》》》sink
1、flink重启任务
- 2、使用最近的检查点恢复状态
-
检查点算法
基于Chandy Lamport算法的分布式快照。将检查点的保存、数据处理分离开。
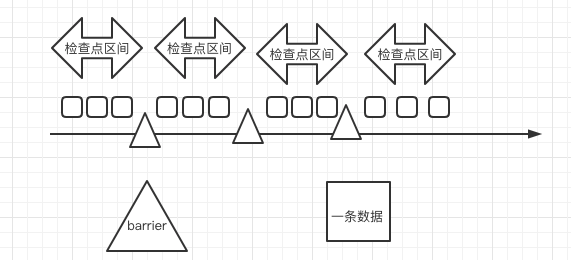
- 检查点分界线 barrier:区分检查点区间,barrier表示处理完这个数据 就进行checkpoint
- 检查点ID:每一个检查点区间都会有一个检查点ID
- 利用写时复制(copy-on-write)机制,可以在处理数据的同时 异步生成状态状态快照
使用
```java env.enableCheckpointing(1000L * 60); // 60秒 CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 配置存储检查点到 JobManager 堆内存 checkpointConfig.setCheckpointStorage(new JobManagerCheckpointStorage()); // 配置存储检查点到文件系统 // checkpointConfig.setCheckpointStorage(new FileSystemCheckpointStorage(“hdfs://namenode:40010/flink/checkpoints”)); //一个检查点60秒内还没完成则超时失败 默认10分钟 checkpointConfig.setCheckpointTimeout(60000L); // //前者检查点结束 与 后者检查点开始,的最小时间间隔 给处理业务留下充足时间。 当设置了本配置时,maxConcurrentCheckpoints 的值强制为 1 checkpointConfig.setMinPauseBetweenCheckpoints(500L); // 最多同时执行的检查点个数 checkpointConfig.setMaxConcurrentCheckpoints(1); // 检查点在job失败、取消时是否保留:RETAIN_ON_CANCELLATION作业失败的时候不会自动清理 DELETE_ON_CANCELLATION默认 作业失败的时候会自动清理 checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 检查点失败时,job是否失败退出 默认true checkpointConfig.setFailOnCheckpointingErrors(false); // 不再执行检查点 barrier对齐操作,但是必须设置为exactly once且setMaxConcurrentCheckpoints(1) // 可以将下一检查点区间的【数据】也保存进检查点。这样,当我们遇到一个分区barrier时就不需等待对齐,而是可以直接启动状态的保存了 // 背压情况下 可能导致检查点过大 因为缓存了很多数据 checkpointConfig.enableUnalignedCheckpoints(true);
---<a name="Y38LF"></a>### 保存点(save points)- 检查点是自动的保存、保存点是手动的保存。- 使用场景:flink版本升级、暂停重启应用、调整并行度。前提是算子的计算逻辑不变,因为保存的之前逻辑的状态。<a name="YDDSv"></a>#### 算子ID保存点是以【算子ID-状态名称】这样命名的,如果不设置算子状态 重启可能会变化 而无法兼容。所以强烈建议每一个算子手动指定ID```javaDataStream<String> stream = env.addSource(new StatefulSource()).uid("source-id") //指定addSource的uid.map(new StatefulMapper()).uid("mapper-id") //指定map算子的uid.name("mapper-id") //指定map算子的name.print();
使用
// 停止flink任务 并在指定目录创建save pointbin/flink stop --savepointPath [:targetDirectory] :jobId// 从一个save point启动flink任务bin/flink run -s :savepointPath [:runArgs]
老马的疑问:
数据流并不是排序好的,怎么知道 某一个数据是否在 检查点区间内?
数据从source进来 添加了barrier之后, 先后顺序就不会再改变了吗?貌似是!!!

若有收获,就点个赞吧
0 人点赞
