宽依赖、窄依赖
- 窄依赖是 分区 一对一或者多对一, 宽依赖就是 分区 多对多或者一对多
窄依赖:每个父RDD的一个Partition会被 子RDD的一个Partition所使用
宽依赖:每个父RDD的一个Partition会被 子RDD的多个Partition所使用
宽依赖就是shuffle
总述
Spark Shuffle分为map阶段和reduce阶段,或者称之为ShuffleRead阶段和ShuffleWrite阶段。
map task个数:假设Spark任务从HDFS中读取数据,那么初始RDD分区个数由该文件的split个数N决定
reduce task个数:默认取spark.default.parallelism这个配置项的值作为分区数,如果没有配置,则以map端的最后一个RDD的分区数作为其分区数(也就是N)
四种shuffle的小文件差异
40 个 executors,
每个 executor 的 cores 为 5
每个 executor 最多同时执行5个task
假设共300个task
Hash-based Shuffle 300reduce个小文件 :map taskreduce task
优化版-Hash-based Shuffle 540reduce个小文件 :corereduce task
sort-based shuffle 3002个小文件 :2map task
BYPASS版-sort-based shuffle 3002个小文件:2*map task
演化路程
Spark 1.0之前仅支持Hash
Spark 1.2的默认Shuffle机制从Hash变成了Sort。
使用配置
- spark.shuffle.manager设置成’hash’ 》》》Hash Shuffle
Hash
- 小文件:map输出map task * reduce task个数的小文件 task就是分区数的意思
- 过程:对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中
缺点:1、产生大量小文件 产生低效耗时的IO
2、内存不够OOM (内存中保存海量的文件操作句柄) <br />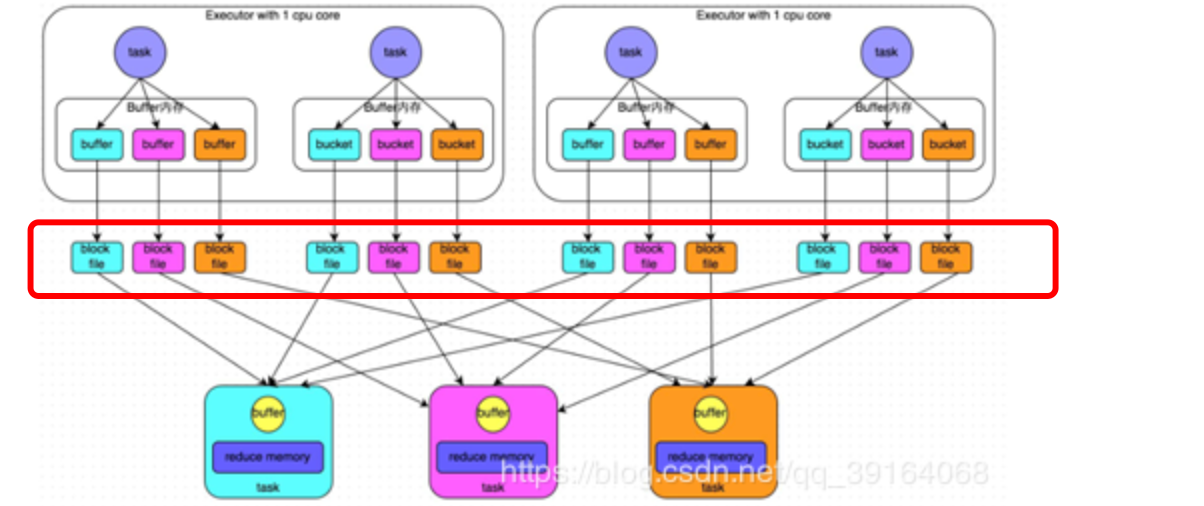
优化版Hash
使用:spark.shuffle.consolidateFiles=true; 设置即可
- 小文件:map输出core*reduce task个数的小文件
- 过程:优化版Hash-based Shuffle中Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup

Sort
- 小文件:map产生2*map task的小文件,即 索引文件、数据文件
- 缺点:task任务过多,同样会导致小文件过多
过程:
1、数据先写入一个数据结构中(默认5M) 根据不同算子 选用不同数据结构(reduceByKey>map join>array)
2、达到临界阈值 写到磁盘中并清空小数据结构(5M)并创建索引文件
3、在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序
4、最后多个临时文件(5M)进行合并merge生成一个大文件,并单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offsetreduce fetch过程
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并、索引文件而已
1、Reducer首先找Driver去获取父Stage中的ShuffleMapTask输出的位置信息,
2、根据位置信息获取index文件,解析index,
3、从解析的index文件中获取Data文件中属于自己的那部分内容; 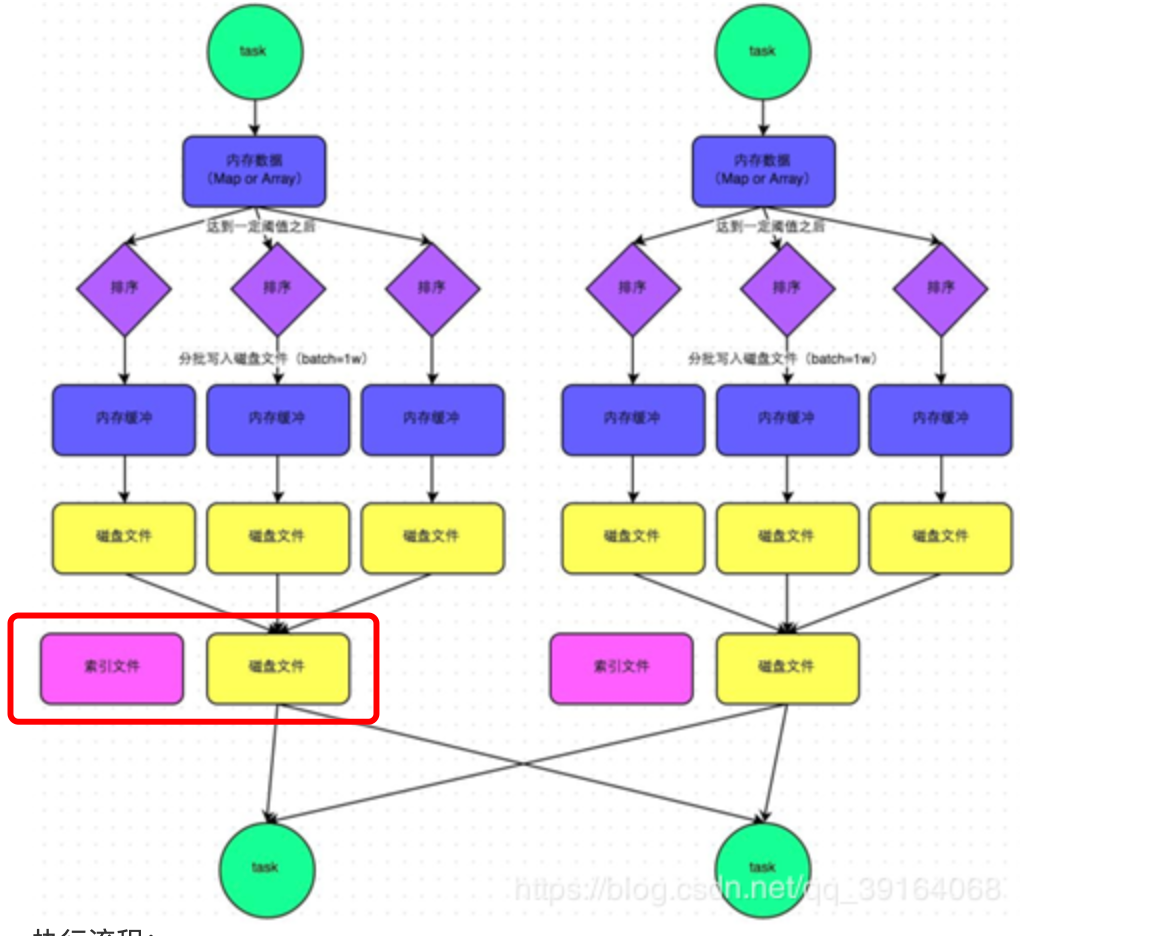
bypass版Sort
- 小文件:map产生2*map task的小文件,即 索引文件、数据文件
- 启动时机:
- shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),会启动bypass
- 算子不是聚合类的shuffle算子(不是reducebykey就启动) 就会启用bypass机制
- 过程:
- 1、先形成map*reduce个数的小文件(跟未经优化的HashShuffleManager是一模一样,hash而不是sort)
- 2、只是在最后会做一个磁盘文件的合并、索引文件而已
- 和sort-based shuffle区别:
第一,磁盘写机制不同;
第二,不需要进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销
钨丝版shuffle
- 与sort shuffle的不同
- 实现了独立的内存管理,避免了JVM的GC
- BinaryData操作,避免序列化和反序列化

若有收获,就点个赞吧
0 人点赞
