TableEnvironment
TableEnvironment 是flink中集成TableAPI和SQL的核心概念,它可以
1、注册catalog、在catalog中注册表
- catalog可以理解为元数据、里面有database、然后是table
- Table类型 需要在catalog注册之后 才能sql直接使用
tableEnv.createTemporaryView("NewTable", newTable);
2、DataStream与Table互相转换
3、执行sql
4、注册UDF
日常简单获取tableEnv
//这个默认是什么?1.11及之后默认是blink版本 之前是老版本StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
老版本planner获取tableEnv
// 基于老版本planner的流处理EnvironmentSettings oldStreamSetting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();StreamTableEnvironment oldStreamTableEnv = StreamTableEnvironment.create(env, oldStreamSetting);// 基于老版本planner的批处理ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
新版本blink-planner获取tableEnv
//基于Blink的流处理EnvironmentSettings blinkStreamSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();StreamTableEnvironment blinkStreamTableEnv = StreamTableEnvironment.create(env, blinkStreamSetting);//基于blink的批处理EnvironmentSettings blinkBatchSetting = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();TableEnvironment blinkBatchTableEnv1 = TableEnvironment.create(blinkBatchSetting);
输入
sql可以使用的表
- 表结构:CSV、JSON、parquet 定义了底层存储的方式、表的序列化方式。 需要引入额外pom
``java // 方法一:连接外部系统 tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector' = ... )"); // kafka CREATE TABLE KafkaTable (userSTRING,urlSTRING,ts` TIMESTAMP(3) METADATA FROM ‘timestamp’ —【METADATA FROM】 使用Kafka的元数据字段timestamp生成一个新字段ts ) WITH ( ‘connector’ = ‘kafka’, ‘topic’ = ‘events’, ‘properties.bootstrap.servers’ = ‘localhost:9092’, ‘properties.group.id’ = ‘testGroup’, ‘scan.startup.mode’ = ‘earliest-offset’, ‘format’ = ‘csv’) // 文件 CREATE TABLE MyTable ( column_name1 INT, column_name2 STRING, … part_name1 INT, part_name2 STRING ) PARTITIONED BY (part_name1, part_name2 ) WITH ( ‘connector’ = ‘filesystem’, — 连接器类型 ‘path’ = ‘…’, — 文件路径 ‘format’ = ‘…’) — 文件格式
// 方法二:从Table对象、dataStream:createTemporaryView 第二个参数可是table 可是dataStream tableEnv.createTemporaryView(“NewTable”, newTable); tableEnv.createTemporaryView(“NewTable”, dataStream,$(“timestamp”).as(“ts”), $(“url”));
// 方法三:从Table对象:直接以字符串拼接添加到SQL中,在解析时会自动注册一个同名的虚拟表到环境中,这样就省略了创建虚拟视图的步骤 Table clickTable = tableEnvironment.sqlQuery(“select url, user from “ + eventTable);
<a name="WVTU6"></a>#### Table对象```java// 方法一:从DataStream:提取Event中的属性 作为表的字段Table eventTable = tableEnv.fromDataStream(eventStream);Table eventTable2 = tableEnv.fromDataStream(eventStream,$("timestamp").as("ts"),$("url"));// 方法二:从sql可以使用的表Table eventTable = tableEnv.from("NewTable");
转换
使用sql
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
使用table-api
Table maryClickTable = eventTable.where($("user").isEqual("Alice")).select($("url"), $("user"));
Table >>> dataStream
// 仅插入流:select简单查询之后得到的tabletableEnv.toDataStream(aliceVisitTable).print();>>>+I[./home, Alice] +I表示【插入】// 更新日志流:group by 之后得到的tabletableEnv.toChangelogStream(groupTable).print();>>>+I[Bob, 1] +I表示【插入】-U[Alice, 1] -U表示【更新前】+U[Alice, 2] +U表示【更新后】
输出
// 方法一:executeInsert + 连接外部系统tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");TableResult tableResult = table1.executeInsert("outputTable");// 连接到控制台 打印输出CREATE TABLE outputTable (user STRING,cnt BIGINTWITH ('connector' = 'print');// 更新流输出到kafkaCREATE TABLE pageviews_per_region (user_region STRING,pv BIGINT,uv BIGINT,PRIMARY KEY (user_region) NOT ENFORCED) WITH ('connector' = 'upsert-kafka',--更新流 以主键形式进行唯一标识 删除就是value为null。--kafka并不支持数据修改'topic' = 'pageviews_per_region','properties.bootstrap.servers' = '...','key.format' = 'avro','value.format' = 'avro');INSERT INTO pageviews_per_regionSELECTuser_region,COUNT(*),COUNT(DISTINCT user_id)FROM pageviewsGROUP BY user_region;// 更新流:输出到mysql 需定义主键CREATE TABLE output (id BIGINT,name STRING,age INT,status BOOLEAN,PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:3306/mydatabase','table-name' = 'users');--mysql真正表名是users output只是flink-catalog里的名字// 更新流:输出到esCREATE TABLE MyTable (user_id STRING,user_name STRINGuv BIGINT,pv BIGINT,PRIMARY KEY (user_id) NOT ENFORCED) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://localhost:9200','index' = 'users');// 更新流:输出到hbase 只支持hbase1.4 2.2CREATE TABLE MyTable (rowkey INT,family1 ROW<q1 INT>,family2 ROW<q2 STRING, q3 BIGINT>,family3 ROW<q4 DOUBLE, q5 BOOLEAN, q6 STRING>,PRIMARY KEY (rowkey) NOT ENFORCED) WITH ('connector' = 'hbase-1.4','table-name' = 'mytable','zookeeper.quorum' = 'localhost:2181');INSERT INTO MyTableSELECT rowkey, ROW(f1q1), ROW(f2q2, f2q3), ROW(f3q4, f3q5, f3q6) FROM T;// 方法二:executeSql + 连接外部系统tableEnv.executeSql("insert into outputTable select ** from table1 where user = 'Alice'");
动态表、持续查询
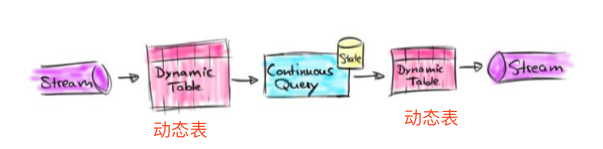
- 与数据库的静态数据不同,flink是动态数据的查询。叫做动态表
-
动态表的三种编码方式
名词解释:通过发送编码消息的方式告诉外部系统要执行的操作
更新流跟撤回流的主要区别在于,更新(update)操作由于有 key 的存在, 只需要用单条消息编码就可以,因此效率更高。
append-only追加流
只做insert操作
-
retract撤回流
有添加add、撤回retract操作。
本流的工作模式:增删改:增add、删retract、改retract+add
update更新流
有更新upsert、删除delete操作
本流的工作模式:增删改:增upsert、删delete、改upsert
- 需要动态表有主键、唯一key

若有收获,就点个赞吧
0 人点赞
