- 安装zookeeper
- 安装hadoop
- 初次启动 格式化NN
bin/zkServer.sh start #三台
sbin/hadoop-daemon.sh start journalnode #三台都启动
bin/hadoop namenode -format #NN1上执行
sbin/hadoop-daemon.sh start namenode #在NN1上执行
bin/hdfs namenode -bootstrapStandby #在NN2上执行 同步元数据
sbin/hadoop-daemon.sh start namenode #在NN2上执行,此时两台NN都是standby状态
bin/hdfs haadmin -transitionToActive nn1 #将NN1手动变成active 有时候需要加上 —forcemanual
bin/hdfs haadmin -getServiceState nn1 #获取NN1的状态 - 日常启动方式+格式化ZKFC
sbin/stop-dfs.sh #关闭NN DN
bin/zkServer.sh start #三台
bin/hdfs zkfc -formatZK #在ZK启动的前提下 格式化ZKFC
sbin/start-dfs.sh
此时NN-HA配置完成
可以去zk命令行 查看监听状态:get -s - 启动RM-HA
sbin/start-yarn.sh #rm1上执行
sbin/yarn-daemon.sh start resourcemanager #rm2上执行
bin/yarn rmadmin -getServiceState rm1 #获取RM状态 此时rm2为standby rm1位active
可以去zk命令行 查看监听状态:get -s - 启动jobhistory
sbin/mr-jobhistory-daemon.sh start historyserver #开启jobhistory,使得19888可以访问
jps - 测试mr
随便上传一个文件到hdfs
hadoop jar /opt/ha/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /kms.sh /out3
若执行不成功或卡住 可到/opt/ha/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop1.log 查看日志 - HA格式化namenode 需要先开启journalnode和zookeeper
1、开启zookerper
2、sbin/hadoop-daemon.sh start journalnode #在journalnode服务器上都操作
3、bin/hdfs namenode -format #在NN1上操作 - kill NN RM
kill 一台active NN或之后 另一台会启动为active,
但是被杀的那台并不会变更为standby状态 需要手动启动NN或者RM( bin/… start namenode)。德军说需要等一会另一台才会启动为active
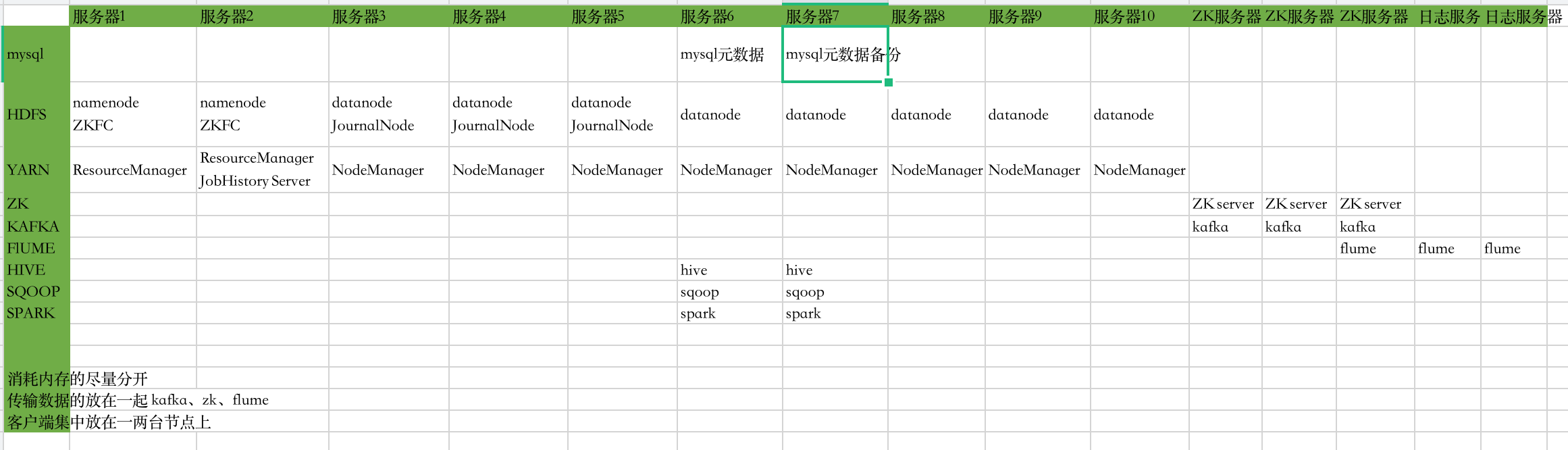
| NameNode DFSZKFailoverController DataNode JournalNode QuorumPeerMain(ZK) ResourceManager NodeManager |
NameNode DFSZKFailoverController DataNode JournalNode QuorumPeerMain ResourceManager NodeManager |
DataNode JournalNode QuorumPeerMain NodeManager |
|---|---|---|
| hadoop1 | hadoop2 | hadoop3 |
准备步骤参考上一篇
安装zookeeper
tar -zxvf zookeeper-3.4.10.tar.gz /opt/egg
vi conf/zoo.cfg
dataDir=/opt/egg/zookeeper-3.4.10/data #这一行本来就有 修改即可
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
/opt/egg/zookeeper-3.4.10/data目录下
vi myid
在三个机器上填上对应的serverID(server.1=hadoop1:2888:3888 hadoop1就是1、hadoop2就是2)
scp 到其余两台机器,并修改myid
bin/zkServer.sh start 三台都启动
安装hadoop
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/egg
vim /etc/profile
##HADOOP_HOMEexport HADOOP_HOME=/opt/ha/hadoop-2.7.2export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
etc/hadoop目录下
vi hadoop-env.sh
vi yarn-env.sh
vi mapred-env.sh
以上三个文件加export JAVA_HOME=/opt/egg/jdk1.8.0_191
mkdir -p /opt/ha/hadoop-2.7.2/data/tmp
三台都执行
core-site.xml
<!-- 把两个NameNode的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-2.7.2/data/tmp</value>
<description>默认在/tmp/{$user}下</description>
</property>
<!-- 配置HDFS-HA自动故障转移 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!-- 开启垃圾桶,垃圾保存时间为一天 单位分钟-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
<!--配置 HDFS 网页登录使用的静态用户
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>-->
hdfs-site.xml
<!-- 数据存放的目录 linux目录,配置hadoop.tmp.dir后 以下三者数据就存到hadoop.tmp.dir了,不再需要配置以下三者了
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/egg/hadoop-2.7.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/egg/hadoop-2.7.2/data/datanode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///opt/egg/hadoop-2.7.2/data/secondary</value>
</property>
-->
<!-- datanode和namenode的心跳时间,默认是五分钟和三秒 -->
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
<description>毫秒</description>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
<description>秒</description>
</property>
<!-- 指定hdfs复制几份 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/ha/hadoop-2.7.2/data/jn</value>
</property>
<!-- 配置HDFS-HA自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 这是配置自动切换的方法,有多种使用方法,具体可以看官网,这里是远程登录杀死的方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 这个是使用sshfence隔离机制时才需要配置ssh免登陆-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
<description>SSH connection timeout, in milliseconds, to use with the builtin shfence fencer. </description>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
分别在两台resourcemanager的yarn-site中添加 rm1\rm2是上文yarn.resourcemanager.ha.rm-ids
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<!-- map task在执行到95%的时候就开始为reduce进行申请资源,默认是0.05有点浪费资源-->
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.95</value>
</property>
conf目录下
vi slaves
hadoop1
hadoop2
hadoop3
scp -r /opt/ha/hadoop-2.7.2 root@hadoop2:/opt/ha
scp -r /opt/ha/hadoop-2.7.2 root@hadoop3:/opt/ha
修改其余两台的 /etc/profile并source
初次启动 格式化NN
bin/zkServer.sh start #三台
sbin/hadoop-daemon.sh start journalnode #三台都启动
bin/hadoop namenode -format #NN1上执行
sbin/hadoop-daemon.sh start namenode #在NN1上执行
bin/hdfs namenode -bootstrapStandby #在NN2上执行 同步元数据
sbin/hadoop-daemon.sh start namenode #在NN2上执行,此时两台NN都是standby状态
bin/hdfs haadmin -transitionToActive nn1 #将NN1手动变成active 有时候需要加上 —forcemanual
bin/hdfs haadmin -getServiceState nn1 #获取NN1的状态
日常启动方式+格式化ZKFC
sbin/stop-dfs.sh #关闭NN DN
bin/zkServer.sh start #三台
bin/hdfs zkfc -formatZK #在ZK启动的前提下 格式化ZKFC
sbin/start-dfs.sh
此时NN-HA配置完成
可以去zk命令行 查看监听状态:get -s
启动RM-HA
sbin/start-yarn.sh #rm1上执行
sbin/yarn-daemon.sh start resourcemanager #rm2上执行
bin/yarn rmadmin -getServiceState rm1 #获取RM状态 此时rm2为standby rm1位active
可以去zk命令行 查看监听状态:get -s
启动jobhistory
sbin/mr-jobhistory-daemon.sh start historyserver #开启jobhistory,使得19888可以访问
jps
测试mr
随便上传一个文件到hdfs
hadoop jar /opt/ha/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /kms.sh /out3
若执行不成功或卡住 可到/opt/ha/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop1.log 查看日志
日常开关机 start-dfs.sh一个脚本包括 NN DN journalnode zkfc 四者的启停,但是它顺序不对 应该按照下面顺序来。
关机
停止historyserver
sbin/stop-dfs.sh #NN1上操作
sbin/stop-yarn.sh #RM1
sbin/yarn-daemon.sh stop resourcemanager #RM2
sbin/hadoop-daemon.sh stop zkfc #两台NN关闭zkfc
sbin/hadoop-daemon.sh stop journalnode #三台都关闭
/opt/egg/zookeeper-3.4.10/bin/zkServer.sh stop #三台
开机
/opt/egg/zookeeper-3.4.10/bin/zkServer.sh start #三台
sbin/hadoop-daemon.sh start journalnode #三台都启动
sbin/hadoop-daemon.sh start zkfc #两台NN启动zkfc
sbin/start-dfs.sh #NN1
sbin/start-yarn.sh #RM1
sbin/yarn-daemon.sh start resourcemanager #RM2
开启historyserver
HA不能自动切换
一台active的namenode挂掉后,另一台namenode也是standby 并不能自动切换到active
第一种情况:
查看zkfc的log日志,看是否会出现下面的Warn或者Exception:
报错:fuser:command not found
解决办法:说明我们的centos系统里面缺少fuser,那我们就可以使用 yum install psmisc 这个命令安装后,fuser就安装好了,直接测试HA,active和standby切换成功!
第二种情况:
root互相登录,可是zkfc服务是hdfs账号运行的,没有权限访问到root的id_rsa文件。更改为hdfs账号免密钥登录恢复正常
第三种情况:
如果sshfence不行,系统会用shell(/bin/true)
shell(/bin/true)
HA格式化namenode 需要先开启journalnode和zookeeper
1、开启zookerper
2、sbin/hadoop-daemon.sh start journalnode #在journalnode服务器上都操作
3、bin/hdfs namenode -format #在NN1上操作
kill NN RM
kill 一台active NN或之后 另一台会启动为active,
但是被杀的那台并不会变更为standby状态 需要手动启动NN或者RM( bin/… start namenode)。德军说需要等一会另一台才会启动为active

若有收获,就点个赞吧
0 人点赞
