拉链表:解决维度表变化
- 拉链表:记录每条信息的生命周期的表
-
缓慢变化维的三种处理方式
假设马狗蛋的手机号 从110 变成了120
1、覆盖:数据库保存一行 马狗蛋 120。 (直接把马狗蛋 110覆盖了)
2、拉链表:数据库保存两行 代理键100 马狗蛋 110 2021-01-01 2021-10-01
代理键 101 马狗蛋 120 2021-10-01 9999-99-99
3、加列:数据库保存一行 马狗蛋 110 120如何获取每日变化数据
最好表内有创建时间和操作时间(Lucky! 阿里的数据库规范要求必需有这两个字段的)
- 如果没有,可以利用第三方工具监控比如canal,监控MySQL的实时变化进行记录(麻烦)。
逐行对比前后两天的数据, 检查md5(concat(全部有可能变化的字段))是否相同(low)
过程详解
理论

- 实操:使用动态分区

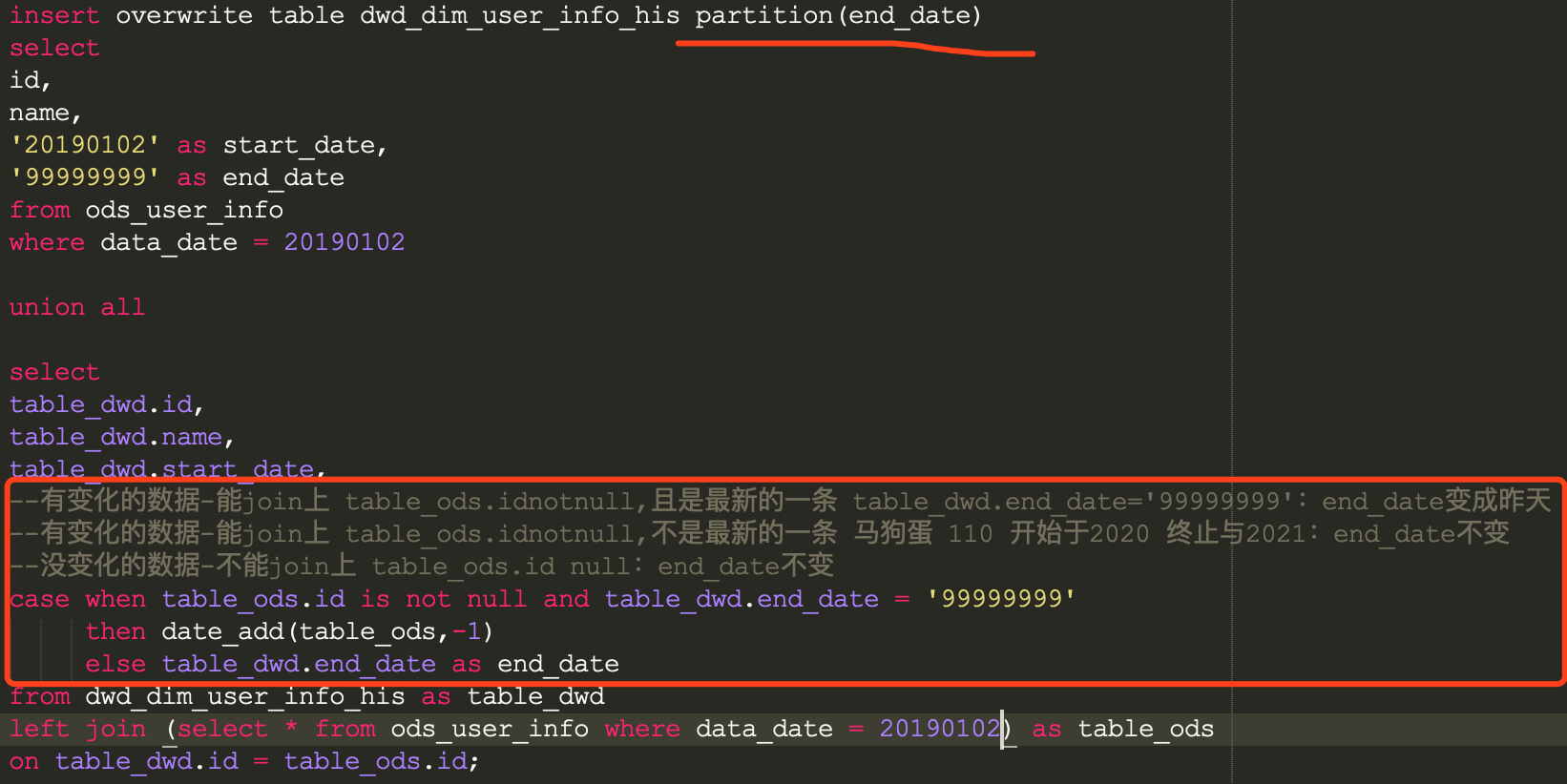
重跑的问题
- 问题:用上面的sql,一天的数据不能重复跑,会重复增加【union all前部分】的数据
- 解决方案:【union all后部分】加筛选
- from (select * from dwd_dim_user_info_his as table_dwd where start_date < 20190102
- 问题:重跑历史的某一天
解决方案:【union all后部分】加筛选 + 循环跑到最新一天
每天全量保存一份维度表 作为一个分区。 dwd join 当天的分区即可
- 在拉链表之上做一层视图, 如下
- select * from A where dt = 20201010 等价于
- select * from A_origin where start_dt <= 20201010 and end_dt > 20201010
维度退化
减少维度表、事实表增加维度字段:
举个栗子:
1、SKU表、SPU表、商品一级分类表、商品二级分类表、商品三级分类表。
2、这5张表可以整合成一张最细粒度SKU 的维度表
减少join
举栗子:
1、SKU(最小维度)、SPU、商品一级分类、商品二级分类、商品三级分类。
2、事实表里不仅仅存储SKU,还把后续的4个维度也存储上。
######### 需注意:
在Kimball的维度建模中,通常按照星形模型的方式来设计,对于维度的获取采用的是通过事实表的外键关联专门的维表的方式,谨慎使用退化维度。
而在大数据领域的事实表设计中,则大量采用退化维度的方式,在事实表中存储各种类型的常用维度信息。这样设计的目的主要是为了减少下游用户使用时关联多个表的操作。 通过冗余存储 来减少计算开销。
维度抽取
事实表里一个gender字段本来存储的 ‘男’ ‘女’。
然后事实表改为存储1、2,并在码表里增加解释:1代替男 2代替女。

若有收获,就点个赞吧
0 人点赞
