原文链接:http://javascript.info/regexp-greedy-and-lazy,translate with ❤️ by zhangbao.
量词的使用第一眼看上去很简单,但实际上也可以很复杂。
我们应该理解查找是怎样进行的,如果我们想写出比 /\d+/ 这样更加复杂的例子来。
让我们看下下面的例子:
例如:”Hello World“ 要变成 «Hello, world»。
一些国家是写作 „Witam, świat!”或者 「你好,世界」。不同的语言选择不同的替换符号,但是原理都是一样的,我们以 «...» 开始。
在替换之前,我们先要找到字符串里的所有引号。
正则表达式像这样:/".+"/g,一个引号后面跟上一个或者更多字符,然后再跟上一个引号。
但是我们会发现有问题……
let reg = /".+"/g;let str = 'a "witch" and her "broom" is one';alert( str.match(reg) ); // "witch" and her "broom"
我们看到这没有按照我们预期的结果显示。
不是但打印 "witch" 和 "broom" 两个结果,而是一个结果:"witch" and her "broom"。
这可以解释为”贪婪是万恶之源”。
贪婪查找
为了查找一个匹配项,正则引擎会使用下面的算法进行查找:
在字符串里的每个索引位置
在该位置匹配模式,
如果没有匹配,就去到下一个位置。
这些简单的词语不足以表达上面例子查找失败的原因。下面我们详尽阐述模式”.+”的查找方式。
- 第一个匹配到的字符是引号”。
正则表达式尝试在源字符串 a "witch" and her "broom" is one 索引位置 0 处进行匹配,但是发现的是 a。
所以,更进一步,查找原字符串里的下一个索引位置,去匹配模式里的第一个字符,最后在索引位置 3 处发现了引号:
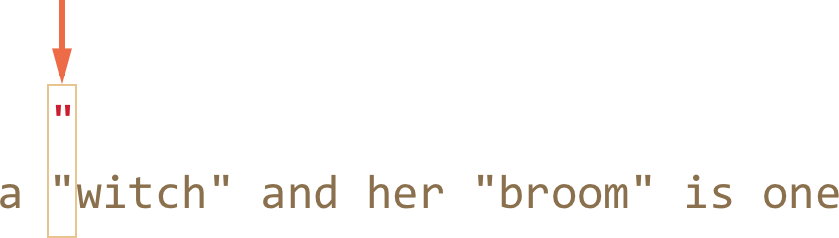
- 引号找到之后,引擎尝试查找撇批模式的剩余部分,查看原字符串的剩余部分是否符合
.+"的规则。
在我们这个例子里,下一个模式字符是 .(点),它表示”除换行符外的任意字符”,所以下一个字符串字符”w“ 是匹配的:
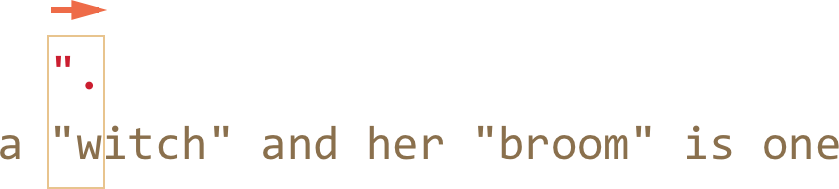
- 因为是
.量词的原因,正则引擎一个接一个字符向下继续匹配。
什么时候结束呢?别忘了所有这里的字符都是匹配这个点的,所以一直到匹配到字符串结束:

- 好的,现在匹配量词
.+结束,开始匹配模式里的下一个字符,是一个引号"。但是有一个问题:已经匹配到字符串结束了,不再有可匹配的字符了!
正则表达式明白了,这可能是因为匹配了太多 .+ 的原因,于是就开始回溯了。
换句话说,之前的匹配位置又向前缩短了一个字符:

现在认为 .+ 匹配到字符串结束前的那个字符,然后模式的剩余部分从这空出来的位置尝试进行匹配。
如果这里有引号的话,正则匹配就完全结束了,但最后一个字符是”e“,并不匹配。
- 所以引擎继续减少之前
.+的匹配数量:

嗯,引号 " 不匹配 n。
- 引擎继续回溯:不断减少
.+的匹配数量,直到匹配模式的剩余部分(在这个例子里是"):

终于匹配到了。
所以返回了第一个匹配结果
"witch" and her "broom"。接下来在第一个匹配项之后接着查找,但是在剩下的字符串is one里,已经没有引号了,所以不再产出匹配结果。
这就是整个正则引擎匹配的过程,但这可能并不是我们想要的结果。
在贪婪模式下(默认),量词会尽可能多的去重复。
正则引擎会尝试获取 .+ 能匹配的尽可能多的字符,然后在一个一个减少以求匹配模式的剩余部分。
但是我们想要的可不是这样的结果,我们想要的是接下来要将的惰性模式。
惰性模式
与贪婪模式相反的是,惰性模式表示”重复尽可能少的次数”。
我们可以通过在一个量词的后面加上问号 ? 启用它。所以就变成 *?、+? 甚至是 ??。
? 本身是可以作为量词使用的,表示匹配零或者多个,但是当它加在 另一个(包含本身)量词 之后,含义就变了——从贪婪模式转换到了惰性模式。
正则 /".+?"/g 就会按照我们预想的结果,找到”witch“和”broom“:
let reg = /".+?"/g;let str = 'a "witch" and her "broom" is one';alert( str.match(reg) ); // witch, broom
为了更好理解这个改变,我们接下来一步步跟踪匹配过程:
- 第一步是一样的:模式从原字符串的索引位置 3 处,匹配到了 “:
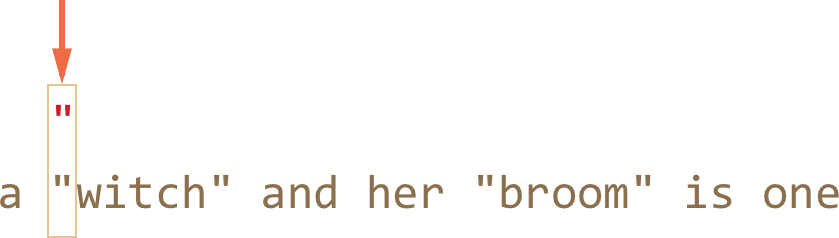
- 下一步类似:引擎找到与量词点 . 匹配的项。
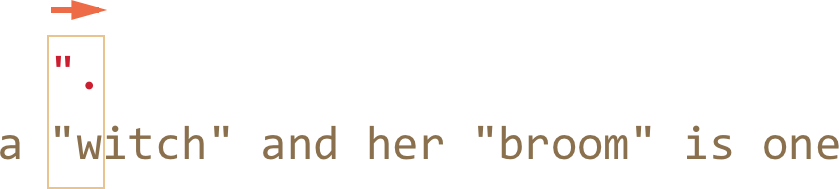
- 加下来的引擎行为就不一样了。因为使用了惰性模式
+?,引擎先不再尝试匹配更多一个字符,而是停下来,尝试匹配模式的剩余部分(也就是"):

如果这里有引号的话,查找就会停止了,但是这里是 i,是不匹配的。
- 然后正则表达式引擎增加了量词 . 的匹配字符数,然后再一次尝试匹配模式的剩余部分。
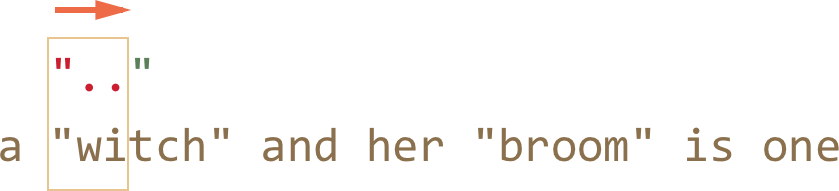
又失败了,所以量词 . 的匹配字符数又增加了。
- ……直到模式的剩余部分匹配了:
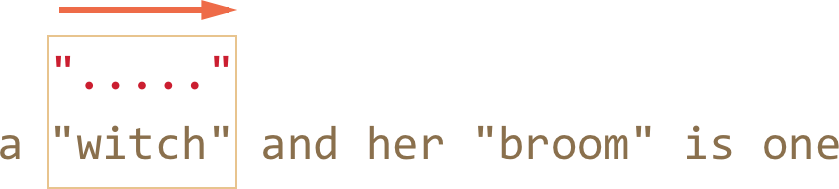
- 下一次查找的开始的位置,从当前匹配项的后一个索引位置开始,最后产生了又一个结果:

从上面例子里,我们看到了惰性模式 +? 在字符串上的匹配过程,量词 +? 与 ?? 工作机制类似——正则引擎只在模式的剩余部分无法匹配的情况下,才去开始增加前一项模式的匹配的字符数。
惰性模式只能使用 量词 + ? 的形式才能启用。
否则其他任何量词都是走贪婪模式。
例如:
alert( '123 456'.match(/\d+ \d+?/g) ); // 123 4
模式
\d+尝试匹配尽可能多的数字(贪婪模式),所以在找到123后就停止了,因为下一个字符是空格 ‘然后模式里有个空格,就匹配了。
接着是
\d+?,这就启用了惰性模式,它发现了一个数字4,然后又从现在这个位置匹配模式的剩余部分。但是在
\d+?之后不再有需要匹配的任何模式内容了。
惰性模式如果不是需要,绝不会继续增加匹配项,匹配就结束了,任务完成了。所以我们得到了匹配结果”123 4“。
- 下一个查找位置就是从字符
5开始的了。
注意:优化
现代正则表达式引擎可以优化内部算法以更快地工作,所以它们可能与刚才描述的算法执行上会有一点不同。
但是如果为了理解正则表达式是如何工作的,才去写正则表达式,我们不需要一定知道,它们只在内部用于优化。
复杂的正则表达式很难优化,因此搜索可能就是像我们描述的那样工作的。
可选方法
使用正则表达式,同一件事,可以有多种方式解决。
在这个场景下,我们不用惰性模式查找字符串里的引号,而是使用这个正则 "[^"]+":
et reg = /"[^"]+"/g;let str = 'a "witch" and her "broom" is one';alert( str.match(reg) ); // witch, broom
正则表达式 "[^"]+" 会给到正确的结果, 因为它查找的是一个引号后面跟的是非引号 [^"],然后是闭合引号。
当正则引擎查找 [^"]+ 的时候,在遇到闭合引号后就停止了重复查找,完整匹配。
请注意,这并不是替换了惰性模式的方法。
只会有些不一样。有时我们需要这个或另一个。让我们再看一个例子,其中懒惰的量词失败了,而会用这个变体是 OK 的。
比如,我们想要查找 <a href="..." class="doc"> 里的 href:
那一个可以使用呢?
首先想到的是: /<a href=".*" class="doc">/g。
让我们看看:
let str = '...<a href="link" class="doc">...';let reg = /<a href=".*" class="doc">/g;// 看,是可以的!alert( str.match(reg) ); // <a href="link" class="doc">
但是如果文本里不只有一个链接呢?
let str = '...<a href="link1" class="doc">... <a href="link2" class="doc">...';let reg = /<a href=".*" class="doc">/g;// 天哪,一个匹配项里有两个链接alert( str.match(reg) ); // <a href="link1" class="doc">... <a href="link2" class="doc">
现在匹配结果是错的,就像之前的那个”魔法”例子。量词 .* 尽可能多的找匹配字符。
匹配看起来是这样的:
<a href="....................................." class="doc"><a href="link1" class="doc">... <a href="link2" class="doc">
让我们修改模式,变为 .*? 所表示的惰性模式:
let str = '...<a href="link1" class="doc">... <a href="link2" class="doc">...';let reg = /<a href=".*?" class="doc">/g;// 现在可以了!alert( str.match(reg) ); // <a href="link1" class="doc">, <a href="link2" class="doc">
匹配看起来是这样的:
<a href="....." class="doc"> <a href="....." class="doc"><a href="link1" class="doc">... <a href="link2" class="doc">
这样为什么可以,想必也不用多说了,上面已经说过了。我们再试一个文本:
let str = '...<a href="link1" class="wrong">... <p style="" class="doc">...';let reg = /<a href=".*?" class="doc">/g;// 匹配好像不对啊alert( str.match(reg) ); // <a href="link1" class="wrong">... <p style="" class="doc">
我们可以看到正则不仅匹配了一个链接,而且在它之后还有很多文本,包含 <p...>。
怎么发生的呢?
首先,正则找到了链接的开头
<a href="。然后开始查找
.*?,嗯,找到了一个字符,然后停下来检查模式的剩余部分,然后再接着找另一个。
量词 .*? 消费字符一直到 class="doc">。
哪里能找到它?如果我们看一下文本,就会发现唯一的 class="doc" 超出了链接范围,在 <p> 标签页中。
- 所以我们匹配的是:
<a href="..................................." class="doc"><a href="link1" class="wrong">... <p style="" class="doc">
所以这里的懒惰模式不管用。
我们需要模式去查找 <a href="...something..." class="doc">,但是贪婪和惰性变体都有问题。
正确的变体应该是 href="[^"]*",它会查找 href 特性里面的所有字符,直到找到最近的引号停止,这就是我们想要的。
例子:
let str1 = '...<a href="link1" class="wrong">... <p style="" class="doc">...';let str2 = '...<a href="link1" class="doc">... <a href="link2" class="doc">...';let reg = /<a href="[^"]*" class="doc">/g;// 正常工作了alert( str1.match(reg) ); // null, 没有匹配项,这是正确的。alert( str2.match(reg) ); // <a href="link1" class="doc">, <a href="link2" class="doc">
总结
量词有两种工作方式:
贪婪
默认情况下,正则表达式引擎会尽可能多地重复量词。例如,\d+ 消耗所有可能的数字。当不可能消耗更多(没有更多的数字或字符串结束)时,它将继续与模式的其余部分相匹配。如果没有匹配,那么它就会减少重复的次数并再次尝试。
惰性
通过在量词后面添加问号 ? 的方式启用。正则引擎尝试在每次重复量词之前匹配模式的剩余部分。
正如我们所看到的,懒惰模式并不是贪婪搜索的”万能药”。另一种选择是一种“微调”的贪婪搜索,带有排除性。很快我们就会看到更多的例子。
(完)

若有收获,就点个赞吧
0 人点赞
