原文链接:https://javascript.info/regexp-character-classes,translate with ❤️ by zhangbao.
有这么一个任务——一个电话号码”+7(903)-123-45-67“,我们要查找字符串里的所有数字,对其它类型的字符我们不关心。
字符类是一个特殊符号,匹配某个特定集合里的任意符号。
例如,”数字”类,写作 \d。我们在模式中使用它,是表示搜索字符串里的数字。
let str = "+7(903)-123-45-67";let reg = /\d/;alert( str.match(reg) ); // ["7"]
上例中的正则不是全局匹配的,只会查找第一个匹配项。
让我们加上 g 标记,查找所有出现的数字。
let str = "+7(903)-123-45-67";let reg = /\d/g;alert( str.match(reg) ); // ["7", "9", "0", "3", "1", "2", "3", "4", "5", "6", "7"]
最常使用的类别:\d \s \w
我们已经介绍了数字字符类。当然还有其他字符类。
最常使用的在这儿:
\d``(”d”表示”digit”)
数字:表示 0 到 9 之间的字符。
\s``(”s”表示”space”)
空格符号:包含空格、tab 和换行符。
\w``(”w”表示”word”)
“单词”字母:包含英文字母、数字和下划线。非英文字母(像斯拉夫字母或者北印度语)不属于 \w 这个范围之内。
例如,\d\s\w 表示一个数字后面跟一个空格,然后空格后面再跟一个单词,比如”1 Z“。
正则表达式里既可以使用常规符号,也可以使用字符类。
例如,CSS\d 匹配的是 CSS 后面再跟一个数字的字符串:
let str = 'CSS4 is cool';let reg = /CSS\d/;alert( str.match(reg) ); // ["CSS4"]
当然,一个正则表达式里可以同时使用多个字符类:
alert( 'I love HTML5!'.match(/\s\w\w\w\w\d/) ); // [" HTML5"]
每个字符类匹配结果里的一个字母:
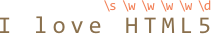
单词边界:\b
\b 是一个特别字符类。
它不代表一个字符,而是用来表示字符间的边界。
例如,\bJava\b 匹配字符串 Hello, Java! 里面的 Java。但是不会匹配 Hello, JavaScript! 里面的内容。
alert( 'Hello, Java'.match(/\bJava\b/) ); // ["Java"]alert( 'Hello, JavaScript!'.match(/\bJava\b/) ); // null
在某种意义上,边界具有”零宽度”,通常字符类表示结果中的字符(像一个单词或一个数字),但在本例中不是这样的。
边界是一个测试。
正则表达式做搜索时,会在字符串中移动,尝试去查找匹配项,每一个字符串索引位置都会查找。
当模式中包含 \b,它测试了字符串中符合下列条件之一的位置:
字符串开头,以及字符串第一个字符之间就是一个
\w。字符串的最后一个字符,和字符串结尾之间就是一个
\w。在字符串中,一边是
\w,另一边不是\w,那么这两边之间就是一个\w。
以 Hello, Java! 为例,\b 会匹配到下列的索引位置:
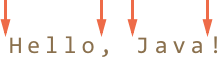
所以上面的字符串匹配 \bHello\b 和 \bJava\b,不会匹配 \bHell\b(因为在 l 之后并不存在一个字符边界)和 Java!\b(因为这个感叹号不是一个有效的单词字符),所以它之后没有边界了。
alert( 'Hello, Java!'.match(/\bHello\b/) ); // Helloalert( 'Hello, Java!'.match(/\bJava\b/) ); // Javaalert( 'Hello, Java!'.match(/\bHell\b/) ); // nullalert( 'Hello, Java!'.match(/\bJava!\b/) ); // null
再一次重申下,\b 让搜索引擎匹配字符边界,因此,Java\b 查找的 Java 之后必然是一个字符边界,但它并没有给结果添加一个字母。
通常我们会用 \b 查找单独的英文单词。比如我们想要使用 \bJava\b 在”JavaScript“精确查找 “Java“ 这个单词。
另外一个例子:正则表达式 \b\d\d\b 会查找单独的两位数字。换句话说,\d\d 前后不是一个 \w 符号(或是字符串的开头/结尾)。
alert( '1 23 456 78'.match(/\b\d\d\b/g) ); // ["23", "78"]
注意:字符边界对非英文字符无效
字符边界 \b 测试 \w 和其他字符的边界。但是 \w 意味着英文字符(或一个数字、下划线),所以这个检测对其他字符是无效的(像斯拉夫字母或者象形文字)。
反向类
对每一个字符类还存在一个”反向类”,用对应的大写字母表示。
“反向”意味着所有其他的字符,例如:
\D``
非数字:所有除了 \d 的字符,比如一个字母。
\S``
非空格:所有除了 \s 的字符,例如一个字符。
\W
非单词字符:所有除了 \w 之外的字符。
\B
非边界:所有除了 \b 之外的字符。
在本章开始时,我们看法了怎样从 +7(903)-123-45-67 中找到所有数字。让我们先得到一个”纯正”的电话号码:
let str = '+7(903)-123-45-67'alert( str.match(/\d/g).join('') ); // 79031234567
一个可选的从字符串里查找非数字的方式是:
let str = '+7(903)-123-45-67'alert( str.replace(/\D/g, '') ); // 79031234567
空格和常规字符
注意,正则表达式里可以包含空格,它们也会被当前常规字符看待。
我们很少关注空格。对我们来说,1-5 和 1 - 5 是不一样的。
但是如果正则表达式里没有将空格计算在内,就不能正常工作。
下面我们来查找经连字符连接的数字:
alert( '1 - 5'.match(/\d-\d/) ); // null 无匹配项
下面我们通过向正则表达式里添加空格来修复这个问题:
alert( '1 - 5'.match(/\d - \d/) ) // ["1 - 5"]
当然,空格只有在我们查找它们的时候才需要加入,额外的空格(就像其他任何字符)还会阻止匹配。
alert( "1-5".match(/\d - \d/) ); // null 因为 1-5 之间没有空格
换句话说,在正则表达式中,所有字符都有地位,空格也是。
“.”表示任意字符
“.“是一个特殊字符类,匹配 除换行符之外的任意字符。
例如:
alert( 'Z'.match(/./) ); // Z
或在正则表达式中间使用:
let reg = /CS.4/;alert( 'CSS4'.match(reg) ); // CSS4alert( 'CS-4'.match(reg) ); // CS-4alert( 'CS 4'.match(reg) ); // CS 4(空格也是一个有效字符啊)
请注意,点表示”任何字符”,但不是”缺少字符”,必须有一个字符来匹配它:
alert( 'CS4'.match(/CS.4/) ); // null
总结
我们覆盖讲述了下列字符类:
\d—— 数字,\D—— 非数字,\s—— 空格,tab 或者换行符,\S—— 所有除了\s之外的字符,\w—— 英文字母,数字和下划线”_“,\W—— 所有除了\w的字符,‘
.‘ —— 除了换行符之外的任意字符。
如果我们想要搜索的,就是一个具有特殊含义的字符,比如反斜杠(\)或圆点(.)。那么我们就需要用一个反斜杠转义:\.。
请注意,regexp 中也可以包含字符串特殊字符,比如换行符 \n。这与字符类没有冲突,因为它们用的是其他字母。
(完)

若有收获,就点个赞吧
0 人点赞
