原文链接:http://javascript.info/garbage-collection,translate with ❤️ by zhangbao.
内存管理在 JavaScript 中是自动执行的,对我们是不可见的。我们创建的原始类型值,对象,函数……所有都是要占据内存的。
但是当这些值都不再需要的话,会怎么处理?JavaScript 引擎怎么发现并且清除它们呢?
可达性
在 JavaScript 的内存管理中中有一个主要概念,称为可达性。
简言之,“可达的”值是那些可以访问或使用的值。它们被保证存储在内存中。
- 有一些天生可达的值,由于显而易见的原因,不能删除它们。
例如:
当前函数里的局部变量和参数。
当前嵌套调用链上的其他函数的变量和参数。
全局变量。
(也有一些内部的)
这些值称为根值。
- 任何其他值都可以被认为是可到达的,如果它是被根值通过引用或引用链到达的。
例如,如果在局部变量中有一个对象,并且该对象的一个属性引用了另一个对象,那么该对象就被认为是可到达的。它所引用的也可以到达,详细的示例见下:
JavaScript 引擎中有一个称为垃圾收集器的后台进程,它监视所有对象,并删除那些已无法访问的对象。
简单的例子
这里举了一个最简单的例子:
// 变量 user 引用了一个对象let user = {name: "John"};
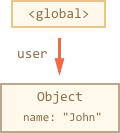
这里的箭头用来描述对象的引用。全局变量 “user” 引用了对象 {name: “john”}(为了简洁,我们称之为 John)。John 的 name 属性存储了一个原始类型值,所以它被画在了对象里。
如果 user 的值被重写了,引用就会丢失:
user = null;
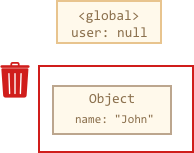
现在 John 变为不可访问的了,没有法访问它,因为没有任何引用指向它。垃圾收集器会丢弃数据并且释放内存。
两个引用
现在我们假设使用两个引用 user 和 admin 来指向同一个对象。
// user 是指向对象的饮用let user = {name: "John"};// admin 也是let admin = user;
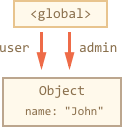
现在,我们做了同样的事:
user = null;
因为对象依然可以通过全局变量 admin 访问到,所以它还在内存。如果我们也重写了 admin,对象就会被删除了。
相互关联的对象
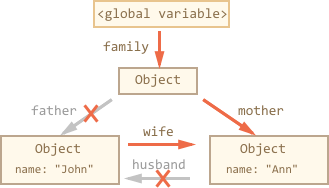
现在举一个更加复杂的例子,family:
function marry(man, woman) {woman.husband = man;man.wife = woman;return {father: man,mother: woman}}let family = marry({name: "John"}, {name: "Ann"});
函数 marry“结合”了0两个对象,让它们相互引用,并返回一个包含它们的新对象。
执行后,内存结果如下:
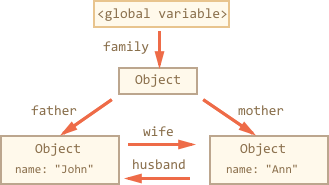
现在为止,所有对象都是可访问的。
现在我们删除两个引用:
delete family.father;delete family.mother.husband;
如果我们只删除这两者之中的一个是不够的,所有的对象依旧是可访问的。
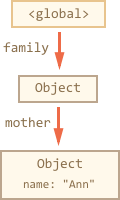
但是如果我们删除了这两个引用,就发现已经没有引用指向 John 了:

输出的引用并不重要。只有连入的引用才让对象可访问。因此,现在 John 是不可访问的了,
就会从内存中连带它的数据删除掉,变为不可访问的了。
在垃圾收集器清理之后:
不可访问的孤岛
一个在内部有相互关联的大对象,有可能是不能访问的,也会从内存中删除。
就拿上面的那个源对象来说:
family = null;
现在内存分布图是这样的了:
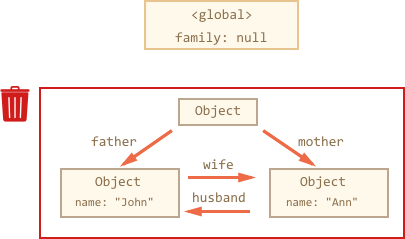
这个例子说明了掌握可访问性这个概念是多么的重要。
显而易见,John 和 Ann 还是彼此关联的,两者都包含连入的引用,但并不足够。
前者 “family” 对象没有再被根值关联,即没有任何引用指向它,所以整个对象变成了孤岛,变得不可访问,并会从内存中删除。
内部算法
基本的垃圾收集算法称为“标记清除”。
下面的“垃圾收集”步骤经常执行:
垃圾收集器找到根值并且“标记”(记住)它们。
然后开始访问和“标记”它们指向的引用。
……然后访问标记对象,标记这些对象指向的引用。所有的访问对象都会被记忆,因此,在未来不会发生同一件对象访问两次的结果。
所有没有被标记的对象都会被删除。
例如,我们的对象结构看起来是这样的:
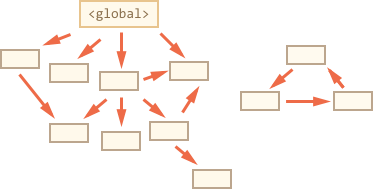
我们可以很清楚地看见右边“不可访问的孤岛”。现在我们来看“标记清除”的垃圾收集算法是怎么工作的。
第一步标记根值:
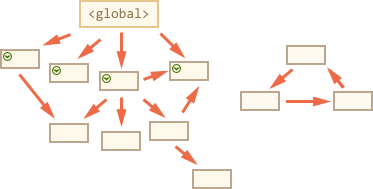
然后它们的引用也会被标记:
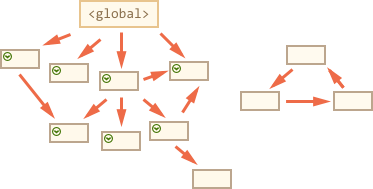
然后是引用的引用……如果可能的话:
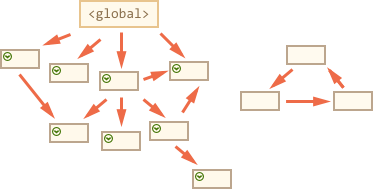
现在在这个过程中,不能被访问的对象被认为是不可访问的,就会被删除:
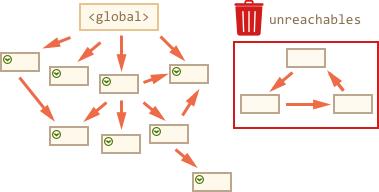
这就是垃圾收集器的工作原理。
JavaScript 引擎会做很多优化,保证更快运行,不影响代码上的执行。
下面是一些优化方式:
分代收集:对象被分成两个集合:“新值”和“旧值”。很多对象出现后,完成工作后就立即销毁了,它们可以被很好地清理。存在的时间稍微久的,就变成“旧值”了,检查的次数也少。
增量收集:如果有很多对象,我们尝试一次遍历并标记整个对象,可能需要一些时间,并在执行过程中引入可见的延迟。因此,引擎试图将垃圾收集分解成碎片。然后,这些碎片分别被一个接一个地执行。这就需要在它们之间进行一些额外的簿记工作,以跟踪变化,但是我们有许多微小的延迟,而不是一个大的延迟。
空闲时间收集:垃圾收集器试图在 CPU 空闲时运行,以减少对执行的可能影响。
垃圾收集算法还有其他的优化和味道。尽管我想在这里描述它们,但我必须推迟,因为不同的引擎会实现不同的调整和技术。更重要的是,随着引擎的发展,事情会发生变化,因此,在没有真正需要的情况下,“提前”进行更深入的研究可能是不值得的。当然,除非这是一个纯粹的兴趣问题,否则下面会有一些链接。
总结
要知道的主要事情是:
垃圾收集是自动执行的,我们不能强迫或阻止它。
对象在可访问的时候被保留在内存中。
被引用与可访问的(来自根值)是不一样的:一组相互关联的对象可以成为不可访问的整体。
现代引擎实现了垃圾收集的高级算法。
一本名为《The Garbage Collection Handbook: The Art of Automatic Memory Management》(R. Jones 等著)的书涵盖了其中的一些内容。
如果您熟悉底层编程,那么关于 V8 垃圾收集器的更详细的信息在文章《A tour of V8: Garbage Collection》可看到。
V8 博客也会不时地发布关于内存管理变化的文章。很自然地,为了学习垃圾收集,您最好通过了解V8的内部原理,并阅读 Vyacheslav Egorov 的博客,他是 V8 的工程师之一。我说的是:“V8”,因为它最好覆盖在互联网上的文章。对于其他引擎,许多方法是相似的,但是垃圾收集在许多方面有所不同。
当您需要低层次的优化时,对引擎的深入了解是好的。明智的做法是,在你熟悉这门语言之后,把它作为下一步计划。
(完)

若有收获,就点个赞吧
0 人点赞
