tags: [知识追踪, HawkesKT]
categories: [知识追踪, HawkesKT]
Utilize Hawkes process to model temporal cross-effects in knowledge tracing (KT)
针对连续时间域上的异步事件序列建模问题,时序点过程(temporal point process)已经成为一种重要的解决方法,时序点过程的发展可以分为两个方向:传统统计点过程(解释性强,样本数量依赖较小)和深度点过程(模型数据拟合能力强,预测精度高,但可解释性不高)。时序点过程等价于一个计数过程,形式化为N(t),表示时刻t之前发生的事件数量。时序点过程的核心是其条件强度函数,有时可以简称为强度函数,用 表示。
表示。
基于时间序列的序列模型:马尔科夫链,隐马尔可夫模型,向量自回归模型等等

应用:事件预测、异步序列聚类、因果关联发现、删失/截断数据、事件缺失属性复原
参考资料:时序点过程发展https://zhuanlan.zhihu.com/p/65086715
ABSTRACT
知识追踪(Knowledge tracing, KT)旨在根据学生的历史表现来模拟学生的知识水平,在计算机辅助教育和适应性学习中起着重要的作用。最近的研究试图把过去交互的时间影响考虑进去,比如遗忘行为。然而,现有的工作主要依赖于时间相关特征或全局衰减函数来模拟时间敏感效应。不同交叉技能影响的细粒度时间动态还没有得到很好的研究(称为时间交叉效应)。例如,某些困难技能的交叉影响可能会迅速下降,而由不同的先前交互作用引起的影响也可能有不同的时间演变,这无法以全局方式捕捉。
在这项工作中,我们研究了KT中不同技能之间的细粒度时间交叉效应。我们首先通过实证研究验证现实世界数据集中时间交叉效应的存在。然后,提出了一个新的模型HawkesKT来明确建模受点过程启发的时间交叉效应,其中每个先前的交互将对目标技能的掌握产生不同的时间敏感影响。HawkesKT采用两个分量来模拟时间交叉效应:1)互激励表示交叉效应的程度;2)核函数控制自适应时间演化。据我们所知,我们是第一个引入霍克斯过程(Hawkes process)来模拟KT中的时间交叉效应的人。对三个基准数据集的广泛实验表明,HawkesKT优于最先进的KT方法。值得注意的是,我们的方法还具有出色的可解释性,并且在训练效率方面显示出显着优势,这使其更适用于现实世界的大规模教育环境。
KEYWORDS:Educational data mining, Knowledge tracing, Temporal cross-effects, Hawkes process, Collaborative filtering
1 INTRODUCTION
当今,计算机辅助学习(CAL)已经成为教育方法的重要组成部分。越来越多的学生可以在各种智能辅导平台上学习。此外,CAL系统中丰富的学习日志可以通过分析学生的学习历史数据,提供个性化的学习轨迹。那些过于困难或已经掌握的技能可以被识别出来,并且只提供最适合的学习材料。
学习者数据分析的一个关键问题是对学生知识状态的评价。知识追踪(KT)是根据过去在教育应用领域的互动([6])预测学生未来的表现(对评价题的回答)的任务。这是一个具有挑战性的过程,因为学习过程涉及许多因素,如一个人获取知识的能力,时间动态,和人类认知[29]。一些传统的方法使用隐马尔可夫模型来捕捉学生知识的演化过程,其中最流行的方法是贝叶斯知识追踪(Bayesian knowledge Tracing, BKT)[6,15]。另一项工作围绕着项目反应理论(IRT)展开,该理论旨在学习共同因素来概括观察结果[3,16,27]。最近,随着深度学习的快速发展,一些基于rnn的方法被提出[24,29],用来建模交互之间的长依赖关系。
在本研究中,我们希望阐明学习是一个动态过程,并且在KT中存在时间交叉效应。一方面,掌握一种技能不仅会受到之前相同技能的交互影响,还会受到其他技能的影响(交叉效应)。另一方面,不同的跨技能效应的时间演化也可能不同。如图1所示,前面的每个交互都将对目标技能产生不同的直接影响。此外,这些效应虽然都随时间衰减,但衰减速率不同,本文称之为时间交叉效应。有些技能可能太容易忘记,而以前不同的交互作用造成的影响也可能有不同的时间演变。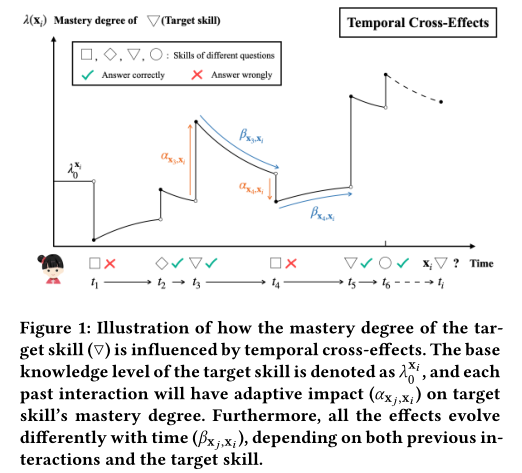
最近有一些研究开始部分探讨KT中的上述时间因素[11,14,24,30,37]。这些方法主要集中在离散时间到槽或提取手工特征。一些研究更进一步,使用全局衰减函数来控制遗忘行为[11,14]。然而,如上所述,学习是一个适应和动态的过程。之前的每个交互作用都将在不同的时间动态下生效。KT的时间交叉效应可能依赖于先前的交互作用和目标技能,这不能完全以全局方式捕获。
在本文中,我们首先通过实证研究验证了KT存在时间交叉效应。通过对现实世界数据中学生交互对之间互信息的分析,我们发现不同的交叉技能效应在时间上的演化确实是不同的。然后,我们引入点过程对KT中的时间交叉效应进行自适应建模。受Hawkes过程的启发,提出了一种新的模型HawkesKT,Hawkes过程是点过程的变体,它利用强度函数来模拟时间局域事件之间的互激励。在KT场景中,基本事件依赖于每个交互的技能和响应。具体地说,为了预测一个人对目标技能的知识状态,历史互动的累积效应及其随时间的演变都自然地由设计的强度函数来表征。此外,这种交叉效应和时间演变对于不同的历史互动和目标技能是独特的。这里还使用了协同过滤来降低计算所有技能对参数的高度复杂性。与基于深度学习的最先进方法不同,该模型中的参数具有高度的可解释性,可用于自动发现技能之间的潜在关系。实际上,HawkesKT揭示了KT方法的一个全新分支,它不同于现有的各种方法。这项工作的主要贡献可以概括为:
- 我们通过对现实世界数据集的实证研究来展示KT中的时间交叉效应。应考虑不同跨技能效应的细粒度时间演变。
- 我们提出了一种新的基于点过程的KT模型HawkesKT来解决KT中的时间交叉效应问题。据我们所知,我们是第一个将霍克斯过程引入这一领域的。
- 在三个真实数据集上的对比实验表明了HawkesKT的有效性。我们的方法也表现出很好的可解释性,在训练效率方面有明显的优势。
2 RELATED WORK
2.1 Knowledge Tracing
传统上,关于KT有两种工作方式。一些研究是基于隐马尔可夫模型的。最具代表性的方法是BKT[6],它用一个二元变量来描述学生的知识状态。另一项工作是基于因子分析。IRT[12]倾向于在观察测试反应的基础上假设和修改受试者的潜在特质。AFM[3]和PFA[27]是基于不同先前信息预测表现的Logistic回归模型。此外,最近提出的KTM[34]利用因子分解机器(Factorization Machines)对特征之间的成对交互进行建模,并被证明包含了上述所有因子分析模型。
随着深度学习在一系列领域中的快速发展,RNN被用来捕获交互之间的复杂依赖关系。DKT[29]利用RNN在每一步的隐含状态来表示学生的知识状态,总体上取得了较好的效果。随后,许多研究效仿DKT来扩展其能力[5,17,32],也有一些研究试图探索其他模型结构(如记忆网络,自我注意)以获得更高的表现力[2,25,39]。然而,上述方法都忽略了时间信息的重要性。因此,在给定交互序列的情况下,他们不能准确估计学生在不同时间变化的知识状态。
2.2 Temporal Dynamics in Knowledge Tracing
通常,KT中存在大量时间信息,并且时间动态对预测未来响应的影响逐渐出现。许多研究集中在学习过程中的遗忘行为。早期探索主要将滞后时间因子纳入BKT或PFA[28,30]。DKT-t[20]和DKTForgeting[24]将不同的基于时间的特征引入DKT。DKT遗忘考虑了重复和序列时间间隔,以及过去的试验次数,这是一种具有时间信息的最先进方法。最近,一些工作利用衰减函数来控制遗忘行为[11,14],假设最近发生的相互作用具有更大的影响。
然而,这些研究要么依赖于手工制作的特征,要么用全局衰减率模拟不断变化的影响。不同的是,我们的HawkesKT明确地对先前每个交互的时间交叉效应进行建模,它可以捕捉不同交叉技能效应的不同时间趋势。
2.3 Hawkes Process
众所周知,点过程擅长对时间局部的顺序事件进行建模[7]。点过程有很多应用,包括地震预测[21],用户在社交网络中的影响[33,40]和论文被引次数[38]。在点过程的变体中,霍克斯过程[13]明确地建模了序列事件的自激励和互激励特征,并且相应的时间趋势由强度函数中的核函数控制。最近,霍克斯过程越来越受到关注,并在各个领域显示出巨大的效果,如在线活动预测和个性化推荐[8,22,35]。
3 EMPIRICAL STUDY
在这一部分中,我们首先正式定义了知识跟踪任务,并介绍了本文中使用的符号。然后,我们验证了真实教育数据集中是否存在时间交叉效应。
3.1 Knowledge Tracing Task Setup
定义3.1(知识追踪任务):给定学生的互动序列 ,知识追踪(KT)旨在预测他/她在下一次互动中是否能正确回答问题
,知识追踪(KT)旨在预测他/她在下一次互动中是否能正确回答问题 。
。
在这项研究中,一个交互 被定义为元组
被定义为元组 , 包括该学生在时间戳
, 包括该学生在时间戳 尝试回答的问题
尝试回答的问题 和相应的反应
和相应的反应 (答案的正确性,1表示正确)。序列按时间升序排序,即对于任何
(答案的正确性,1表示正确)。序列按时间升序排序,即对于任何 ,
, 。 此外,为了确定每个问题所涉及的技能,我们有一个从问题到技能的映射函数
。 此外,为了确定每个问题所涉及的技能,我们有一个从问题到技能的映射函数 ,可以得到问题
,可以得到问题 相应的技能id
相应的技能id 。 给定
。 给定 和
和 ,
, 是要预测的目标。
是要预测的目标。
3.2 Dataset Description
这里我们使用一个真实世界的基准数据集ASSISTments 12-13来进行实证研究。ASSISTments是一个在线辅导系统,在数学方面教授和评估学生,这一系列的数据集经常被用于相关的研究[10]。数据集中总共有270万个互动,涉及265种技能。更详细的信息可以在第5.1.1节中找到。
为了便于理解,我们将主要展示关于频率最高的前10项技能的分析结果。表1显示了数据集中这些技能的名称。请注意,这些技能id将在整篇文章中使用。
3.3 Temporal Cross-Effects
为了验证是否存在时间交叉效应,我们首先定义了学生交互对之间的条件互信息(CMI),这将在接下来的分析中使用。
定义3.2(条件互信息):给定一个限制条件c,我们可以在每个学生的交互序列中找到满足c的所有交互对 。如果我们将交互前和交互后的响应
。如果我们将交互前和交互后的响应 分别视为随机变量,则条件互信息定义为
分别视为随机变量,则条件互信息定义为
这里的条件c可以是交互前和交互后的特定技能,或者是两次交互之间的时间间隔。定义中的概率可以通过计算所有满足交互对中的频率得到。实际上,CMI反映了限制条件下互动前后的依赖程度。
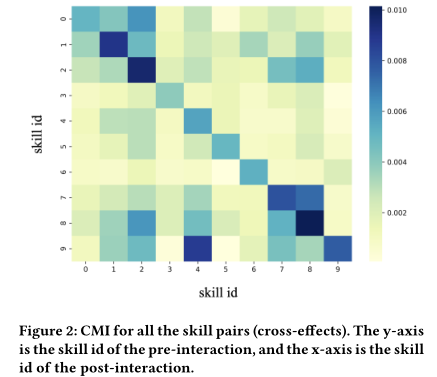
首先,我们对前后互动的技能进行了限制,以验证技能之间的交叉效应。请注意,如果两个技能完全独立,则相应的CMI应为0。图2显示了所有技能对组合的CMI。Y轴是交互前的技能ID,x轴是交互后的技能ID。我们可以看到,对于相同技能(对角线)的交互,效果通常是最大的。但是,不同技能之间存在着明显的交叉效应,如前交互和后交互分别为9和4的情况。在{0,1,2}和{7,8,9}技能组中,依赖关系很高,这是有道理的,因为这些技能通常被认为是相关的。因此,当预测目标技能的掌握程度时,重要的是不仅要关注之前与同一技能的互动,还要关注其他相关技能的互动。
其次,我们进一步研究了不同交叉效应的时间演化。除了像之前对前后交互的技能进行限制外,我们还根据两次交互之间的对数时间间隔对交互对进行了进一步的分组。图3显示了全局趋势和一些具有代表性的技能对。对数转换后的时间间隔从2开始,一些网格被屏蔽,因为在这些条件下没有足够的交互对(小于50)。从整体上看,由于遗忘行为,整体的时间演化呈现出衰减的形式,这与前人的研究一致[24]。然而,值得注意的是,对于不同的技能对,衰减率明显不同,我们称之为时间交叉效应。例如,当前后互动分别为8和7时,短期内的CMI很大,因为它们高度相关,但随着时间的推移,CMI迅速衰减。另一方面,8和2之间的CMI更小,衰减更慢,这是合理的,因为技能2相对容易,这两个技能没有直接关联。请注意,还有许多其他技能对在时间演化方面显示出显著的差异,在这种情况下,以前的工作中一个全局衰减函数是不够的。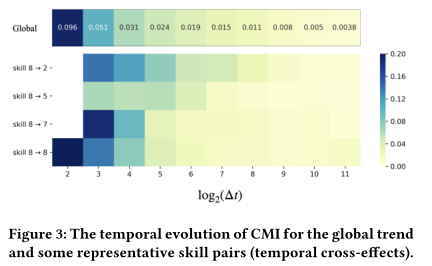
因此,为了捕捉上述实证研究中显示的时间交叉效应,在KT中建立细粒度遗忘行为模型是很重要的,其中应该同时考虑跨技能效应和适应性衰减率。
4 METHODOLOGY
4.1 Preliminaries about Hawkes Process
从形式上看,时间点过程是一个随机过程,其实现由时间局部化的离散事件列表组成 ,时间
,时间 。在 KT 场景中,它代表了学生正确/错误地回答不同问题时的一系列时间戳,这些时间戳构成了时间点过程的基本事件。给定过去事件
。在 KT 场景中,它代表了学生正确/错误地回答不同问题时的一系列时间戳,这些时间戳构成了时间点过程的基本事件。给定过去事件 的历史时间,时间点过程引入了条件强度函数
的历史时间,时间点过程引入了条件强度函数  ,表示下一个事件时间的随机模型。为了简单起见,我们在后续部分省略条件符号,记为𝜆(𝑡)。然后, 在一个小的时间窗口[𝑡, 𝑡 + 𝑑𝑡]内发生新事件的概率可以表示为[1, 35]:
,表示下一个事件时间的随机模型。为了简单起见,我们在后续部分省略条件符号,记为𝜆(𝑡)。然后, 在一个小的时间窗口[𝑡, 𝑡 + 𝑑𝑡]内发生新事件的概率可以表示为[1, 35]:
至于强度函数𝜆(𝑡)的具体形式,各种模型都有所不同。作为一种流行的、强大的变体,Hawkes过程对事件之间的激发进行建模,其强度函数的形式为:
其中 𝜆0 是基础强度,每个历史事件都有一个成瘾效应 𝛼。这些影响随时间间隔而变化,触发核𝜅(·)控制相应的时间特征。
4.2 HawkesKT Model
受Hawkes Process中强度函数的启发,我们设计了  来表示学生在给定历史交互
来表示学生在给定历史交互  的情况下在
的情况下在 时正确回答问题
时正确回答问题 的可能性。 为了建模 KT 中的时间交叉效应,使用互激励
的可能性。 为了建模 KT 中的时间交叉效应,使用互激励 来捕获交叉技能效应,并且在设计的核函数
来捕获交叉技能效应,并且在设计的核函数 中处理细粒度的时间演化,从而得到如下形式的强度函数:
中处理细粒度的时间演化,从而得到如下形式的强度函数:
这里的总强度由基础强度 和时间交叉效应部分组成。 基础强度旨在捕捉目标问题本身的难度,而时间交叉效应则建模先前交互的自适应时变影响( adaptive time-varying impacts)。
和时间交叉效应部分组成。 基础强度旨在捕捉目标问题本身的难度,而时间交叉效应则建模先前交互的自适应时变影响( adaptive time-varying impacts)。
4.2.1 Base Intensity
我们注意到,以往的研究通常不考虑问题索引,这可能是由于数据稀疏性和它带来的大量参数造成的。在基于深度学习的模型中,给每个问题单独嵌入的成本太高了。因此,使用技巧来索引问题是避免过度拟合和过度参数化的有效方法。然而,在实践中,不同的问题有不同的困难程度,即使是相同的技能。缺乏问题的模型化会导致表现力和灵活性的降低。
这里我们利用基础强度来捕捉技能和问题两者的难度,其定义如下:
其中 和
和 分别是每个问题和技能的参数。在预测目标交互 x𝑖 的响应时,之前的每一次交互都会在这个代表了目标交互的固有特征的基础强度
分别是每个问题和技能的参数。在预测目标交互 x𝑖 的响应时,之前的每一次交互都会在这个代表了目标交互的固有特征的基础强度 的基础上生效。这样,每个问题只引入一个参数,在建模单个问题和避免过度参数化之间取得平衡。
的基础上生效。这样,每个问题只引入一个参数,在建模单个问题和避免过度参数化之间取得平衡。
4.2.2 Temporal Cross-Effects
如第3节所示,之前的事件对目标交互有不同的影响,并且这些影响会随着时间的推移而衰减。此外,衰减率彼此不同,这与历史交互和目标技能都有关。在这一部分中,我们重点对KT中的这种自适应时间交叉效应进行建模。这里主要有两个组成部分:(1)互激励  控制即时效应的程度,以及(2)核函数
控制即时效应的程度,以及(2)核函数 控制交叉效应的细粒度时间动态。
控制交叉效应的细粒度时间动态。
首先,我们使用 来建模之前的交互 x𝑗 会在多大程度上影响目标交互 x𝑖 中的反应。这里我们将技能-反应对
来建模之前的交互 x𝑗 会在多大程度上影响目标交互 x𝑖 中的反应。这里我们将技能-反应对  视为历史序列中的一个基本事件, 技能索引𝑠 (𝑞𝑖 ) 是将受到影响的目标2。这样,假设总共有|S|个技能,互激励
视为历史序列中的一个基本事件, 技能索引𝑠 (𝑞𝑖 ) 是将受到影响的目标2。这样,假设总共有|S|个技能,互激励 可以分解为形状为 2|S|×|S|的参数矩阵。第一个维度代表历史交互的状态,第二个维度代表要预测的目标技能。值得注意的是,互激励
可以分解为形状为 2|S|×|S|的参数矩阵。第一个维度代表历史交互的状态,第二个维度代表要预测的目标技能。值得注意的是,互激励 内在地包含了每个技能对之间的关系。
内在地包含了每个技能对之间的关系。
我们不将其设置为问题特定的,因为这将太细粒度,无法学习有意义的相互参数,而技能相对来说是更合适的级别。
2我们不将其设置为问题特定的,因为这将太细粒度,无法学习有意义的互参数,而技能相对来说是更合适的级别。
其次,为了模拟遗忘行为,我们选择指数函数作为核函数:
其中 是在不同情况下控制细粒度衰减率的另一个核心参数。具体来说,给定目标技能,具有不同技能和反应的历史事件的影响将具有自适应衰减率。至于核函数的形式,指数函数是逼近遗忘曲线的自然选择。它也被广泛应用于Hawkes过程的许多应用中,并且在大多数情况下被证明是有效的 [9, 23, 38]。此外,我们发现对时间间隔
是在不同情况下控制细粒度衰减率的另一个核心参数。具体来说,给定目标技能,具有不同技能和反应的历史事件的影响将具有自适应衰减率。至于核函数的形式,指数函数是逼近遗忘曲线的自然选择。它也被广泛应用于Hawkes过程的许多应用中,并且在大多数情况下被证明是有效的 [9, 23, 38]。此外,我们发现对时间间隔 应用对数变换很重要,因为时间间隔通常表现出长尾分布。在这个设置下,指数函数实际上变成了幂函数
应用对数变换很重要,因为时间间隔通常表现出长尾分布。在这个设置下,指数函数实际上变成了幂函数 。人们还可以设计其他函数形式以适应不同的实际应用场景。
。人们还可以设计其他函数形式以适应不同的实际应用场景。
随后,使用强度值𝜆(x𝑖),通过将 sigmoid 函数应用于强度值来预测在交互 x𝑖 中正确回答问题的概率:
4.3 Reparameterization Method
接下来,我们将重点介绍如何处理模型中的参数。除了基础强度,核心参数是 和
和 。通常,它们分别建模为Hawkes过程中的一个矩阵,其中每个条目(entry)表示特定历史和目标事件组合的参数:
。通常,它们分别建模为Hawkes过程中的一个矩阵,其中每个条目(entry)表示特定历史和目标事件组合的参数:
第一个维度代表技能-响应对(𝑠 (𝑞𝑗 ), 𝑎𝑗 ),第二个维度索引目标技能𝑠 (𝑞𝑖 ) 进行预测。
虽然直接优化参数矩阵是一个直观的解决方案,但存在两个主要问题。首先,与总共  种组合相比,数据集中存在的事件对通常是稀疏的。结果,只有少数参数会被更新,如果|S|,则参数的数量会很大。其次,不同对的参数是独立的,因此从数据中学到的时间交叉效应模式不能传播以及推广到看不见的情况。因此,我们引入矩阵分解作为重新参数化的方法,以利用协同过滤 [19] 并减少参数总数 [4, 36],这经常在推荐系统中使用。
种组合相比,数据集中存在的事件对通常是稀疏的。结果,只有少数参数会被更新,如果|S|,则参数的数量会很大。其次,不同对的参数是独立的,因此从数据中学到的时间交叉效应模式不能传播以及推广到看不见的情况。因此,我们引入矩阵分解作为重新参数化的方法,以利用协同过滤 [19] 并减少参数总数 [4, 36],这经常在推荐系统中使用。
协同过滤假设相似的历史事件对目标交互有相似的影响。我们可以将技能-反应对和目标技能编码到同一向量空间,并使用内积推导出每个组合的参数。这样,我们将为每组核心参数提供两个因子矩阵:
这里 𝐷 表示隐藏空间的维度。那么具体的 和
和 可以计算为:
可以计算为:
这样,考虑到𝐷≪|S|,参数的数量将从 减少到
减少到 。此外,得益于协同过滤,学习到的时间交叉效应模式被编码在每个维度的嵌入中。这将非常有助于对罕见交互对的时间交叉效应进行建模,并理解技能之间的潜在关系。
。此外,得益于协同过滤,学习到的时间交叉效应模式被编码在每个维度的嵌入中。这将非常有助于对罕见交互对的时间交叉效应进行建模,并理解技能之间的潜在关系。
4.4 Parameter Learning
综上所述,Hawkes KT中的参数是基础强度 、
、 和因子矩阵{P𝐴,Q𝐴, P𝐵,Q𝐵}。为了共同学习这些参数,我们优化了预测概率
和因子矩阵{P𝐴,Q𝐴, P𝐵,Q𝐵}。为了共同学习这些参数,我们优化了预测概率 和真实响应
和真实响应 之间的标准交叉熵损失:
之间的标准交叉熵损失:
由于ADAM算法[18]的成功,我们使用ADAM作为学习算法。我们还在因子矩阵上添加了权重衰减。
4.5 Prerequisite Score
除了预测未来的表现,HawkesKT 还能够根据有意义的参数自动发现潜在的技能关系。请注意,参数 本质上包含技能之间的相互影响。我们将
本质上包含技能之间的相互影响。我们将 表示为使用技能𝑠1 正确回答问题对目标技能𝑠2 造成的影响。同理,
表示为使用技能𝑠1 正确回答问题对目标技能𝑠2 造成的影响。同理, 表示𝑠1 不正确的情况。
表示𝑠1 不正确的情况。
直觉上,如果𝑠1是𝑠2的先决条件:(1)𝑠1的低知识水平会对𝑠2产生负面影响; (2) 对𝑠2 的高度掌握可能表明对𝑠1 很了解。相应地, 预期小,而
预期小,而 应该较大。因此,对于每个技能 𝑠𝑖 ,我们定义其先决条件分数
应该较大。因此,对于每个技能 𝑠𝑖 ,我们定义其先决条件分数 表示其他技能是 𝑠𝑖 的先决条件的可能性:
表示其他技能是 𝑠𝑖 的先决条件的可能性:
其中Softmax旨在使所有技能s之间的影响标准化(normalize)。然后,给定任何技能分数 ,我们可以根据先决条件分数
,我们可以根据先决条件分数 获得其最可能的先决条件。
获得其最可能的先决条件。
在目前的教育文献中,技能之间的关系通常是人工标注的,这需要大量的资源和时间。该方法可供教育专家参考和完善,这对在线教育场景和传统课堂教学都具有重要意义。技能关系发现的结果将在第5.5节中介绍。
5 Experiments
5.1 Experimental Settings
5.1.1 Datasets
我们使用三个真实世界的数据集来验证我们的模型的有效性。
- ASSISTments 09-10。[10]ASSISTments是一个在线辅导系统,教授和评估学生的数学知识。此数据集是公开可用的3。
- ASSISTments 12-13。此数据集来自与先前相同的系统,但时间跨度不同4。
- Slepemapy.cz.。[26]此数据集来自一个用于练习地理的在线系统,可公开获取5。我们使用place_asked作为技能标识符。每项技能将根据类型有两个问题:(1)在地图上找到给定的地点;(2)选择突出显示的地点的名称。Slepemapy.cz.。[26]此数据集来自一个用于练习地理的在线系统,可公开获取5。我们使用place_asked作为技能标识符。每项技能将根据类型有两个问题:(1)在地图上找到给定的地点;(2)选择突出显示的地点的名称。
3https://sites.google.com/site/assistmentsdata/home/assistment-2009-2010- data/skill-builder-data-2009-2010 4https://sites.google.com/site/assistmentsdata/home/2012-13-school-data-with- affect 5https://www.fi.muni.cz/adaptivelearning/?a=data
对于每个数据集,我们丢弃交互少于5次的无效用户,只考虑每个用户的前50个交互,因为当用户历史记录很少时,预测性能更重要。此外,ASSISTments 09-10中缺少每个交互的时间戳,因此我们假设用户以固定的时间间隔(1秒)连续回答问题。经过预处理后,表2显示了这三个数据集的统计数据。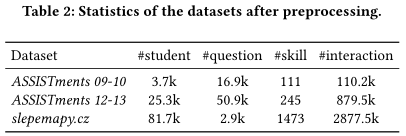
5.1.2 Evaluation Protocols
我们执行5折交叉验证来评估所有的模型,在这些模型中,折叠是基于用户进行分割的。通过从训练集中提取10%的用户来构建验证集,该验证集用于调整超参数和执行提前停止。对于每个序列,除第一个位置外的每个位置都将用于训练和评估。我们使用曲线下面积(AUC)作为评价指标。前人的许多研究也采用了上述设置[24,29]。
5.1.3 Baseline Methods
我们在不同的方面将我们的Hawkes KT模型与六种基线方法进行了比较。前三个基线不包含时间信息:
- IRT[16]。这是一种基于项目反应理论的传统方法,它用两组参数对项目和用户的特征进行建模。
- DKT[29]。DKT通过RNN的隐藏状态来表示学生的知识。每种技能都被编码成一个one-hot向量或一个低维嵌入。
- SAKT[25]。这是最近提出的一种基于自注意力机制的深度学习方法。
其余三个基线考虑了时变效应(time-varying effects):
- DKT-Forgetting[24]。这是一个基于DKT的模型,它将过去的尝试和时间间隔视为额外的特征。
- KTM[34]。该方法利用分解机器对特征之间的交互进行建模。这里我们使用的特征包括问题ID、技能ID、对不同技能的历史反应以及DKT-Forgetting中的时间特征。
- AKT-R[11]。这是一个基于注意力的神经网络模型,注意力权重是通过一个具有全局衰减率的距离感知指数衰减来计算的,这是一个具有时间信息的最先进的方法。
5.1.4 Parameter Settings
我们在 PyTorch 中实现了 HawkesKT 和其他基线(IRT 除外),并且代码是公开的6。为了公平比较,对于所有数据集上的不同模型,嵌入大小和隐藏大小固定为 64。如果验证集上的 AUC 在 5 个epochs没有增加,则应用提前停止。学习率在 {5𝑒−3, 1𝑒−3, 5𝑒−4, 1𝑒−4} 之间调整,l2 系数在 {1𝑒−3, 1𝑒−4, 1𝑒−5, 1𝑒−6, 0} 之间调整.所有模型参数通通常以0均值和0.01标准差进行初始化。
5.2 Overall Performance
表3显示了所有基线方法和我们的HawkesKT模型的性能。我们有以下观察所得: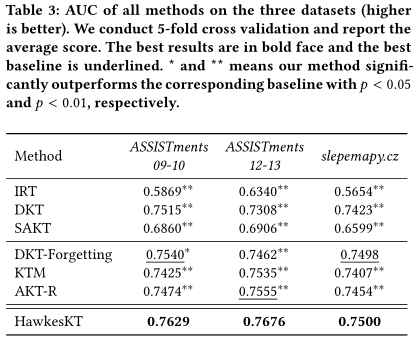
首先,不同类型的基线表现出明显的性能差距。作为基于 RNN 的模型,DKT 优于传统的 IRT。我们还发现 DKT 在所有数据集上都优于 SAKT,这与之前的工作 [11] 一致。 DKT-Forgetting 获得进一步改进,表明考虑时间因素的重要性。 KTM 可以灵活地结合问题级别和时间特征,因此有时比基于 DKT 的模型表现更好。大多数情况下,AKT-R 会取得显著的结果,因为它不仅对时间衰减进行建模,而且还通过基于 Rasch 模型的嵌入来包含问题级别信息。但是我们发现 KTM 和 AKT-R 由于模型容量大,在训练过程中容易出现过拟合现象。
其次,HawkesKT的表现始终好于所有基准。与DKT-Forgetting相比,HawkesKT自然考虑到了连续的时变效应,而不是仅仅依赖于同技能或相邻技能的互动。KTM能够扩展以包含时间特征,但是它需要手工制作的特征,并且不能捕捉每个先前交互的自适应时间交叉效应。至于AKT-R,虽然它结合了指数衰减来模拟遗忘行为,但是衰减率仍然是全局的。因此,它不能捕捉到本文所揭示的时间交叉效应,从而导致性能次优。相反,我们的HawkesKT模型通过互激励和自适应核函数来解决时间交叉效应,从而始终获得最好的结果。
第三,我们的HawkesKT模型能够扩展到不同的场景。这三个数据集涉及不同的主题,数据的大小从小到大不等。始终如一的改进/提升证明了HawkeKT的可伸缩性。请注意,我们的模型在数学数据集上获得了更大提升。而在地理数据集(slepemapy.cz)上,提升并不是很大(与DKT-Forgetting相比差异不大)。这是合理的,因为技能之间的时间交叉效应在数学上确实更有帮助。至于地理位置,一般只有周边国家才能帮助确定目标国家。技能之间的关系很简单,主要的时间动态是自我遗忘,这就解释了为什么DKT-Forgetting和AKT-R表现得很好。
5.3 Efficiency Analyses
作为一种新的方法分支,我们还研究了HawkesKT的效率问题。表4显示了两个代表性数据集上不同方法的每个epoch的训练时间和参数总数。我们确保所有方法都在相同的实验设置(批次大小、嵌入大小、最大序列长度)下进行评估。所有的实验都是在单个1080Ti GPU上进行的。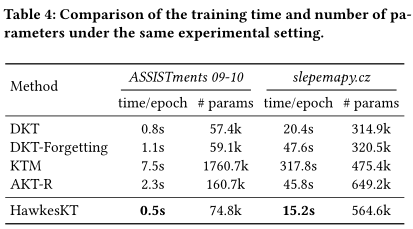
我们可以观察到,HawkesKT的训练时间比其他最先进的方法要少得多,甚至比DKT更快。如果数据集中有很多问题,KTM速度就会特别慢,因为需要大量的参数。AKT-R由于其复杂的模型结构,效率也不高。值得注意的是,与最近的工作相比,我们的HawkesKT不仅具有更少的参数,而且在获得最佳性能的同时,大大降低了训练成本。在真实的教育场景中,及时性也是一个重要因素。Hawkes KT在有效性和效率方面的显著优势将使其更适用于现实世界的大规模教育环境。
5.4 Ablation Study
为了验证时间交叉效应建模的影响,我们将HawkesKT和三种变体进行比较:
- \Temporal:该模型移除了核函数,因此不考虑遗忘行为,导致强度函数如下:

- \Cross:该模型使用全局参数 𝛽 来控制指数衰减:

- \CF:该模型不使用矩阵分解作为重新参数化方法,直接优化参数A、B,形状为2|S| × |S|。
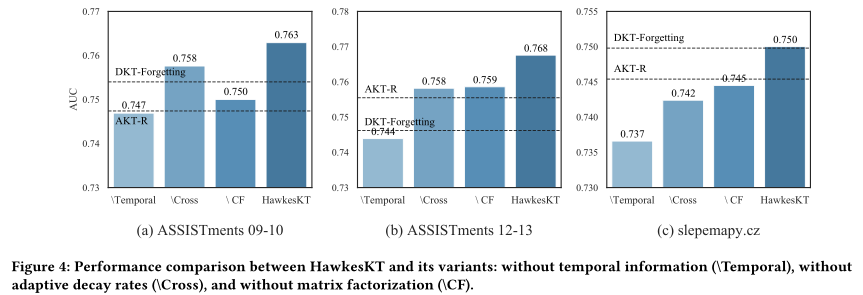
图4显示了HawkesKT及其变体在所有数据集上的AUC,以及用于比较的DKT-Forgetting和AKT-R。我们有以下主要观察结果:
首先,时间信息在KT中非常重要。\Temporal导致的性能损失最大,通常比DKT-Forgetting和AKT-R更差,这说明了对遗忘行为进行建模的必要性。
其次,建模具有不同衰减率的细粒度时间演化对于捕捉KT中的时间交叉效应非常重要。虽然\Cross的性能损失不是最大的,但值得注意的是,\Cross在所有数据集上都会导致更糟糕的结果。在没有时间交叉效应的情况下,\CROSS在ASSIST 12-13上产生与AKT-R相似的结果。这表明全局衰减率是不够的,我们模型中提出的自适应时间交叉效应确实是有帮助的。
第三,使用矩阵分解的重新参数化带来了稳定的性能增益。矩阵分解有助于利用协同过滤,这使学习到的模式能够通过嵌入传播,并在不同的情况下进行泛化。在不进行矩阵分解的情况下,所有数据集上的\CF性能都有一定的损失,这说明了点过程和协同过滤相结合的有效性。
5.5 Skill Relationships Discovery
这里我们想根据第4.5节中提出的先决条件分数来验证关系发现的性能。
首先,我们使用在ASSISTments 12-13上训练的具有前10个频率技能的参数作为案例研究。我们在图5中可视化了一些代表性技能之间的关系。圆圈代表技能,箭头代表技能之间的先决条件关系。计算出的先决条件分数也注释在箭头旁边(箭头越粗,关系越强)。带颜色的圆圈是我们关注的代表性技能,它的主要先觉条件以及它们之间的关系都被画出来了。该图表明,我们的模型确实发现了一些有意义的关系。例如,所有运算顺序(红色的6)取决于加法/减法(2)和乘法/除法(7,8)的技能。乘法/除法技能的先决条件分数较高,因为它们在确定运算顺序时更为重要。此外,乘法分数(7)是除法分数(蓝色为8)的有力前提,加减分数(2)也有一定的影响。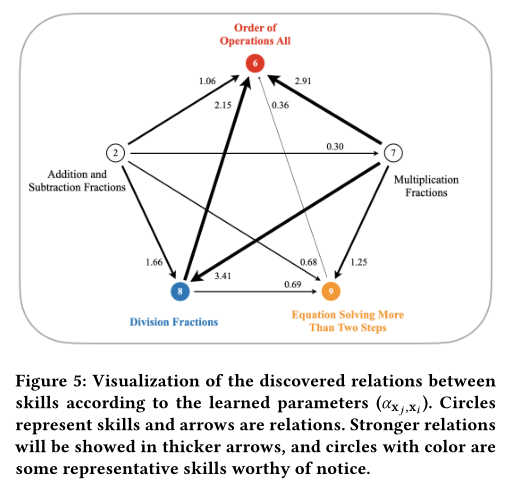
其次,我们进行了标注实验,对发现的关系进行了定量验证。我们在ASSISTments 12-13中选择了前20个频率技能,并请三位专家对每个技能对之间的 binary helpfulness 进行注释。注释的卡帕系数为0.52,说明其适用性。平均的注释结果被用作相关性的基本事实。然后,基于提议的先决条件分数生成每个技能的排名列表。该排名列表是根据注释的相关性来评估的,其平均NDCG为0.8267。这表明我们的模型确实可以自动发现与人类感知一致的技能之间的关系。
上述分析验证了我们的参数假设,并证明HawkesKT中的参数是高度可解释的。揭示的关系图可以作为教育专家的有效补充。这种方法还可以扩展到大量技能之间的关系,这在在线和传统教育场景中都很有帮助。
6 CONCLUSION AND FUTURE WORK
在本文中,我们提出了明确建模 KT 中的时间交叉效应,即不同交互之间的自适应时变效应。通过实证研究,我们验证了不同的跨技能效应具有不同的时间动态。基于数据表现出的时间交叉效应,提出了一种新的基于点过程的HawkesKT模型,它揭示了 KT 方法的一个新分支。在HawkesKT中,每次历史交互都会对目标技能产生不断变化的影响,并由相应的核函数控制。在不同场景下,HawkesKT在三个真实数据集上取得了比最先进的方法更好的性能。同样值得注意的是,我们的模型在训练效率和参数可解释性方面具有显著的优势。在此基础上,我们提出了先决条件分数,基于模型参数自动发现潜在技能关系,可作为教育专家的参考和补充。
未来,我们计划使HawkesKT具有可扩展的辅助信息,因为当前的模型不够灵活,无法考虑其他特征,如学校、问题类型等。我们还考虑结合技能之间的已知依赖关系,来提高预测性能。

若有收获,就点个赞吧
0 人点赞
