tags: [知识追踪, 跑实验]
categories: [知识追踪, 跑实验]
开始之前
查看知识追踪领域数据集的情况
知识追踪数据集中的数据通常以三行形式呈现,每三行代表一个学生的做题情况,第一行表示做题数,第二行表示学生所做题目的ID,第三行则表示学生的作答情况。如下方所示:
192
742 504 1731 1955 559 2015 2944 2170 2051 1153 1046 607
0 0 0 0 0 0 0 0 0 1 0 0
数据集问题总数以及不同的题数
import csvrows = csv.reader(open('./slepemapy/slepemapy/train_valid.csv'), delimiter=',')rows = [[int(e) for e in row if e != ''] for row in rows]# print(rows)q_num=0, count=0for subq_num in rows[0::3]:# print(subq_num[0])q_num+=subq_num[0]count+=1print("训练验证集样本数:",count,"训练验证集问题总数:",q_num)q_rows = []unique_qnum=0for q_row in rows[1::3]:# print(q_row)q_rows.extend(q_row)# print(subqnum)# unique_qnum+=subqnum# print(unique_qnum)print("训练验证集中不相同题目的数量:",len(set(q_rows)))
训练验证集样本数: 14535 训练验证集问题总数: 1060408训练验证集中不相同题目的数量: 1683
查看数据集的大致情况(前五行)
import numpy as npimport pandas as pd# 通过读取 csv 文件创建 DataFramedf = pd.read_csv('./train_valid.csv', header=None)# 查看所有行print(df)# 查看前 5 行print(df.head())print(df.head(5))# 查看后 5 行print(df.tail())print(df.tail(5))# 查看行标签(index),列标签(columns)和数据print(df.index)print(df.index.names)print(df.columns)print(df.values)# 查看基本统计信息print(df.info())print(df.describe())
conda常用的命令。
1)conda list 查看安装了哪些包。<br /> 2)conda env list 或 conda info -e 查看当前存在哪些虚拟环境<br /> 3)conda update conda 检查更新当前conda<br />使用 conda create -n your_env_name python=X.X(2.7、3.6等)命令创建python版本为X.X、名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。
shell脚本实例
!/bin/bash # ‘#!’是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
echo “Hello World !” # echo 命令用于向窗口输出文本。
运行 Shell 脚本有两种方法:
1、作为可执行程序
将上面的代码保存为 test.sh,并 cd 到相应目录:
chmod +x ./test.sh #使脚本具有执行权限./test.sh #执行脚本
2、作为解释器参数
这种运行方式是,直接运行解释器,其参数就是 shell 脚本的文件名,如:
/bin/sh test.sh # 执行shell脚本
后台运行命令
nohup ./test.sh > myout.log 2>&1 &
解释:
& 放在命令到结尾,表示后台运行,防止终端一直被某个进程占用,这样终端可以执行别到任务
nohup放在命令的开头,表示不挂起(no hang up),也即,关闭终端或者退出某个账号,进程也继续保持运行状态
0 表示stdin标准输入
1 表示stdout标准输出
2 表示stderr标准错误
2>&1 也就表示将错误重定向到标准输出上
Linux查看Nvidia显卡信息及使用情况
GPU与显存的关系类似于CPU与内存的关系
Nvidia自带一个命令行工具可以查看显存的使用情况:nvidia-smi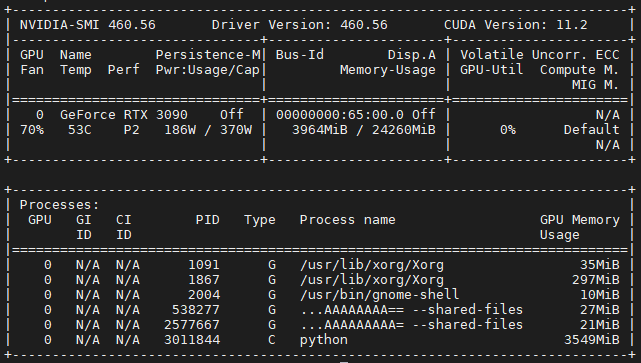

注:此图片来源于网络
表头释义:
Fan:显示风扇转速,数值在0到100%之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:能耗表示;上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
Bus-Id:涉及GPU总线的相关信息;格式为:domain:bus:device.function
Disp.A:是Display Active的意思,表示GPU的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的GPU利用率;
ECC:是否开启错误检查和纠正技术;0/DISABLED, 1/ENABLED
Compute M.:计算模式;0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED
下边的Processes显示每块GPU上每个进程所使用的显存情况。
注:显存占用和GPU占用是两个不一样的东西,显卡是由GPU和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
如果要周期性的输出显卡的使用情况,可以用watch指令实现:watch -n 10 nvidia-smi,命令行参数-n后边跟的是执行命令的周期,以s为单位。
脚本——并行跑几条命令
num=1for hs in 50 100 150 200;do{for bs in 32 64 128 256;do{for ds in assist2015 assist2017 slepemapy eanalyst;do{# echo "${num} ${ds}_hidden${hs}_batch${bs}"python SAKT.py --isServer 1 --train_dataset '${ds}' --state_size ${hs} --epoch 200 --batch_size ${bs} >${ds}_hidden${hs}_batch${bs}.log 2>&1 &if [ `expr ${num} % 2` == 0 ]thenecho "${num} 每两个停一下,并等待两秒!"sleep 2waitfinum=`expr ${num} + 1`}donewait}done}done

若有收获,就点个赞吧
0 人点赞
