tags: [笔记, Sklearn]
categories: [笔记, Sklearn]
reward: true
相关配置
import sklearn
sklearn.datasets使用
sklearn的数据集库datasets提供很多不同的数据集,主要包含以下几大类:
- 玩具数据集
- 真实世界中的数据集
- 样本生成器
- 样本图片
- svmlight或libsvm格式的数据
- 从http://openml.org下载的数据
- 从外部加载的数据
用的比较多的就是1和3,这里进行主要介绍,其他的会进行简单介绍,但是不建议使用。
样本生成器
scikit-learn 包括各种随机样本的生成器,可以用来建立可控制的大小和复杂性人工数据集。
用于分类和聚类的生成器
(一) 簇 datasets.make_blobs()
1.n_samples:样本数 2.n_features:特征数(维度)3.centers:中心数,也可以是中心的坐标 4.cluster_std:簇的方差
from sklearn import datasetscenters = [[2,2],[8,2],[2,8],[8,8]]x, y = datasets.make_blobs(n_samples=1000, n_features=2, centers=4,cluster_std=1)print(x.shape)y.shape
(1000, 2)(1000,)
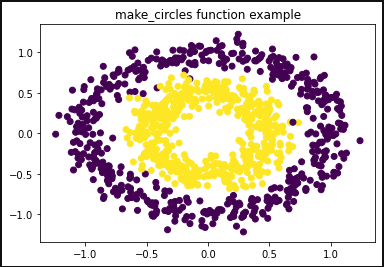
(二) 同心圆 sklearn.datasets.make_circles
- noise:在数据中加入高斯噪声的标准差。
- factor:内圆与外圆之间的比例因子,在(0,1)范围内。
from sklearn.datasets import make_circlesimport matplotlib.pyplot as pltimport numpy as npfig=plt.figure(1)x1,y1=make_circles(n_samples=1000,factor=0.5,noise=0.1)# datasets.make_circles()专门用来生成圆圈形状的二维样本.factor表示里圈和外圈的距离之比.每圈共有n_samples/2个点,# 里圈代表一个类,外圈也代表一个类.noise表示有0.1的点是异常点plt.title('make_circles function example')plt.scatter(x1[:,0],x1[:,1],marker='o',c=y1)

若有收获,就点个赞吧
0 人点赞
