tags: [知识追踪, SAKT]
categories: [知识追踪, SAKT]
ABSTRACT 摘要
知识追踪是指当每个学生参与一系列学习活动时,对知识概念(KCs)的掌握情况进行建模的任务。每个学生的知识是通过评估学生在学习活动中的表现来建模的。为学生提供个性化的学习平台是一个重要的研究领域。近年来,基于递归神经网络(RNN)的方法,如深度知识追踪(DKT)和动态键值记忆网络(DKVMN),由于能够捕获人类学习的复杂表示,因而优于所有传统方法。然而,这些方法在处理稀疏数据时面临的问题是不能很好地泛化【研究问题】,这是真实世界数据的情况下,学生与很少的KCs交互。为了解决这个问题,我们开发了一种方法,从学生过去的活动中识别与给定KC相关的KC,并根据选择的相对较少的KC预测他/她的掌握情况。由于预测是基于相对较少的过去活动,它处理数据稀疏性问题比基于RNN的方法更好。为了识别KCs之间的相关性,我们提出了一种基于自我注意的方法——自我注意知识追踪(SAKT)。在各种真实世界数据集上的广泛实验表明,我们的模型在知识追踪方面优于最先进的模型,平均提高了4.43%的AUC。
1. INTRODUCTION 引言
学生关于他们知识概念(KC)的学习轨迹有海量数据集是可用的,其中KC可以是一种练习,一种技能或一个概念,吸引了数据挖掘者开发工具来预测学生的表现并给予适当的反馈[8]。在开发这种个人化学习平台的过程中,知识追踪(knowledge tracing, KT)被认为是一项重要的任务,它被定义为基于学生过去的学习活动对其知识状态进行追踪,这种知识状态代表了学生对KCs的掌握程度。KT任务可以被形式化为一个监督序列学习任务-给定学生过去的练习互动X = (x1,x2,…,xt),预测他/她下次互动(回答)xt+1的某个方面。在问答平台上,交互用xt= (et, rt)表示,其中et是学生在时间戳t上尝试的练习,rt是学生答案的正确性。KT旨在预测学生是否能够正确回答下一个练习,即预测p(rt+1= 1|et+1,X)。
最近,深度知识追踪(DKT)[6]及其变体[10]等深度学习模型使用递归神经网络(RNN)在一个总结的隐向量中对学生的知识状态进行建模。动态键值记忆网络(DKVMN)[11]为KT开发了记忆扩充神经网络[7]。它使用Key和Value两个矩阵,分别学习练习与潜在的KC和学生知识状态之间的关系。DKT模型面临参数无法解释的问题[4]。DKVMN比DKT更易于解释,因为它显式地维护KC表示矩阵(密钥)和知识状态表示矩阵(值)。然而,由于所有这些深度学习模型都是基于RNN的,它们在处理稀疏数据时都面临着不能泛化的问题[3]。
在本文中,我们建议使用一种纯粹基于注意机制的方法,即转换器(Transformer)[9]。在KT任务中,学生在经历一系列学习活动时所获得的技能是相互关联的,在特定练习中的表现取决于他在过去与该练习相关的练习中的表现。例如,在图1中,一个学生要解决属于知识概念“方程”的“二次方程”的练习(练习5),他需要知道如何找到“平方根”(练习3)和“线性方程”(练习4)。本文提出的SAKT首先从过去的互动中识别出相关的知识概念,然后根据学生在这些知识概念上的表现来预测学生的表现。为了预测学生在练习中的表现,我们使用练习作为KC。正如我们稍后所展示的,SAKT为前面回答的练习分配权重,同时预测学生在特定练习中的表现。在所有数据集上,SAKT方法的性能明显优于现有的KT方法,在AUC上的性能平均提高了4.43%。此外,SAKT的主要成分(自我注意)适合于并行性,从而使我们的模型比基于RNN的模型快了一个数量级【SAKT优势】。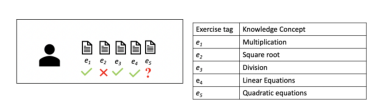
图1:左下图显示了学生尝试的练习顺序,右下图显示了每个练习所属的知识概念。
2. PROPOSED METHOD 建议的方法
我们的模型根据一个学生之前的交互序列X = x1,x2,…xt,预测他是否能够回答下一个练习et+1。如图2所示,我们可以将问题转换为顺序建模问题。考虑输入为x1,x2,…xt且前面一个位置的练习序列e2, e3,…,et且输出为对练习响应的正确性r2, r3,…rt的模型是方便的。交互元组xt= (et, rt)在模型中表示为数字yt= et+ rt× E,其中E为练习总数。因此,交互序列中的元素可以接受的总值是2E,而练习序列中的元素可以接受E个可能的值。
现在我们来描述我们体系结构的不同层。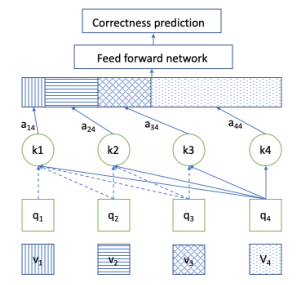

(a)SAKT网络。在每个时间戳上,仅为先前元素中的每一个估计关注度权重。从如下所示的嵌入层中提取键、值和查询。当第j个元素为查询且第i个元素为关键时,关注权重为ai,j。
(b)嵌入层嵌入学生正在尝试的当前练习及其过去的交互。在每个时间戳t+1处,使用练习嵌入将当前问题et+1嵌入到查询空间中,并且使用交互嵌入将过去交互xt的元素嵌入到键和值空间中。
图2:显示SAKT体系结构的示意图。
嵌入层:对得到的输入序列y=(y1,y2,…,yt)转化为s=(s1,s2,…,sn),其中n是模型可以处理的最大长度。由于该模型可以处理固定长度序列的输入,当序列长度t小于n时,我们在序列的左边重复添加一个问答对填充。然而,如果t大于n,则我们将序列划分为长度为n的子序列。具体地说,当t大于n时,yt被划分为t/n个子序列,每个子序列的长度为n。所有这些子序列都用作模型的输入。我们训练一个交互嵌入矩阵M∈R×d,其中d是潜在维数。该矩阵用于获得序列中每个元素si的嵌入Msi。同样,我们训练练习嵌入矩阵E∈R×d,使得集合ei中的每个练习嵌入到第i行。
位置编码:位置编码是自注意神经网络中用来对位置进行编码的那一层,这样我们就可以像卷积网络和递归神经网络一样对序列的顺序进行编码。这一层在知识追踪问题中尤为重要,因为学生的知识状态会随着时间的推移而逐渐稳定地演变。在某个特定时间实例的知识状态不应显示波状转变[10]。为了整合这一点,我们使用了一个参数,位置嵌入,P∈R×d,它是在训练时学习的。然后将第i行位置嵌入矩阵Pi加入到交互序列的第i个元素的交互嵌入向量。
嵌入层的输出是嵌入交互输入矩阵Mˆ和嵌入练习矩阵Eˆ: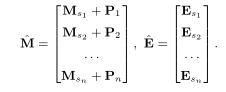
自我注意层:在我们的模型中,我们使用了按比例缩放的点积注意机制[9]。这一层找出与每个先前求解的练习相对应的相对权重,以预测当前练习的正确性。
我们使用以下公式获得查询和键-值对: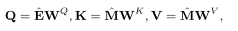
其中W、W、W∈R×d分别表示查询、关键字和值投影矩阵,它们将各自的向量线性投影到不同的空间[9]。使用注意力权重来确定先前的每个交互与当前练习的相关性。为了计算关注度权重,我们使用缩放的点积[9],定义如下: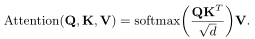
多头:为了共同处理来自不同代表性子空间的信息,我们使用不同的投影矩阵对查询、键和值进行线性投影h次。
其中 和W∈R×d。
和W∈R×d。
因果关系:在我们的模型中,在预测第(t+1)次练习的结果时,我们应该只考虑前t次交互作用。因此,对于查询Qi,不应考虑使得j>i的键Kj。我们使用因果层来掩蔽从未来交互关键字学习到的权重。
前馈层:上面描述的自我注意层的结果是前面交互的值Vi的加权和。然而,从多头层获得的矩阵的行 仍然是先前交互的值Vi的线性组合。为了在模型中加入非线性,并考虑不同潜在维度之间的相互作用,我们使用了前馈网络。
仍然是先前交互的值Vi的线性组合。为了在模型中加入非线性,并考虑不同潜在维度之间的相互作用,我们使用了前馈网络。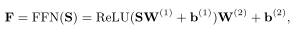
其中W∈R×d,W∈R×d,b∈R,b∈R是在训练过程中学习到的参数。
残差连接:残差连接[2]用于将较低层的特征传播到较高层。因此,如果低层特征对预测很重要,残差连接将有助于将它们传播到执行预测的最终层。在KT的背景下,学生尝试用属于特定概念的练习来强化该概念。因此,残差连接可以帮助将最近求解的练习的嵌入传播到最后一层,使得模型更容易利用低层信息。在自我注意层和前馈层之后都应用了残差连接。
层归一化:文献[1]表明,归一化跨特征的输入有助于稳定和加速神经网络。出于同样的目的,我们在我们的体系结构中使用了层归一化。在自我注意层和前馈层也进行了层归一化。
预测层:最后,将得到的矩阵Fi值的每一行通过Sigmoid激活函数的全连接网络对学生的表现进行预测。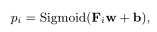
其中pi是标量,表示学生对练习ei正确回答的概率,Fi是F的第i行,Sigmoid(Z)=1/(1+e−z)
网络训练:训练的目标是最小化模型下观察到的学生反应序列的负对数似然率。通过最小化pt和rt之间的交叉熵损失来学习参数。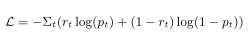
3. EXPERIMENTAL SETTINGS 实验环境
3.1 Datasets 数据集
Synthetic:该数据集是通过模拟4000名虚拟学生的答题轨迹得到的。每个学生回答相同顺序的50个练习,这些练习取自5个难度不同的虚拟概念。
ASSISTment 2009(ASSIST2009):此数据集由ASSISTment在线辅导平台提供,广泛用于KT任务。我们在更新后的“技能构建者”数据集上进行了实验。该数据集是稀疏的,因为该数据集的密度为0.06,如表2所示。
ASSISTment 2015(ASSIST2015):ASSISTment 2015包含学生对百项技能的回答。共有19917名学生和708631个互动。虽然此数据集中的记录数量多于ASSISTment 2009,但每个学生的平均记录数量较少,因为学生数量较多。此数据集是所有可用数据集中最稀疏的,密度为0.05。
ASSISTment Challenges(ASSISTChall):此数据来自ASSISTment 2017大赛。就互动次数而言,它是最丰富的数据集,有942,816个互动,686名学生和102个技能。此数据集是所有可用数据集中密度最高的数据集,因为其密度为0.81。
所有数据集的完整统计信息可以在表2中找到。
STATICS2011(Statics):此数据集包含工程静力学课程的交互,包含189,927个交互、333名学生和1223个技能标签。我们采用了文献[11]中经过处理的数据。它也是一个密度为0.31的密集数据集。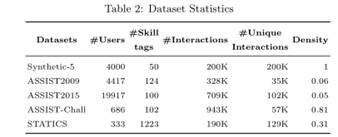
与#Users, #Skill tags和#Interactions对应的列分别代表学生数量、练习标签总数和记录数量。列密度Density表示每个数据集的密度,即, Density = #Unique Interactions/(#Users ×#Skill tags) 密度=#唯一交互/(#用户×#技能标签))。
3.2 Evaluation Methodology 评价方法
Metrics度量:预测任务在二进制分类设置中考虑,即正确或不正确地回答练习。因此,我们使用曲线下面积(AUC)度量来比较性能。
Approaches 方法:我们将我们的模型与最先进的KT方法DKT[6]、DKT+[10]和DKVMN[11]进行比较。这些方法在引言中有介绍。
Model Training and parameter selection 模型训练和参数选择:我们用80%的数据集对模型进行训练,并在剩余的数据集上进行测试。对于所有的方法,我们尝试了隐藏状态维数d={50,100,150,200}。对于相互竞争比较的方法,我们使用了与它们各自的论文中报告的相同的超参数。对于权重的初始化和优化,我们使用了与[10]类似的过程。我们使用TensorFlow实现了SAKT,并使用了学习率为0.001的ADAM[5]优化器。我们对ASSISTChall数据集使用批处理大小256,对其他数据集使用批处理大小128。对于记录数量较多的数据集,例如ASSISTChall和ASSIST2015,我们使用的dropout rate(丢弃率)为0.2,而对于其余数据集,我们使用的dropout rate为0.2。【论文中对于不同数据集使用的dropout rate描述似乎有错误】我们设置序列的最大长度,n与每个学生的平均练习标签大致成正比。对于ASSISTChall和Statics数据集,我们使用n=500;对于ASSIST2009,n=100;对于合成数据集和ASSIST2015数据集,n设置为50。
4. RESULTS AND DISCUSSION 结果与讨论
Student Performance Prediction 学生表现预测:表3显示了SAKT与当前最先进方法的性能比较。在合成数据集上,SAKT的表现优于竞争对手的方法,AUC值为0.832,而DKT+的AUC值为0.824。尽管合成数据集是密度最高的数据集,但SAKT的性能优于基于RNN的方法,这是因为生成合成数据所使用的方法。对于此数据集,每个单独的练习仅派生自一个概念。使用项目反应理论[8]确定学生正确回答该数据集中习题的概率为: ,其中c表示正确猜测的概率,α和β是随机选择的数字,分别表示概念能力和练习难度。 因此,在此数据集中,属于同一概念的练习具有很强的相关性。与其他基准不同,SAKT直接尝试识别属于同一概念的练习,因此比其他方法执行得更好。在ASSIST2009上,SAKT的性能好于被用来比较的其他方法,比第二好的方法获得了3.16%的性能提升。对于ASSIST2015数据集,SAKT显示出15.87%的令人印象深刻的改进。我们将这一收益归因于这样一个事实,即SAKT利用的注意力机制即使在数据集稀疏的情况下也能很好地学习和概括,ASSIST2015就是这种情况,因为它的密度是其他数据集中最小的。对于STATICS2011,与DKT+相比,我们的方法获得了2.16%的性能提升。对于ASSISTChall,我们的方法的性能与DKT相当。这可以归因于ASSISTChall是所有实际数据集中密度最高的数据集。
,其中c表示正确猜测的概率,α和β是随机选择的数字,分别表示概念能力和练习难度。 因此,在此数据集中,属于同一概念的练习具有很强的相关性。与其他基准不同,SAKT直接尝试识别属于同一概念的练习,因此比其他方法执行得更好。在ASSIST2009上,SAKT的性能好于被用来比较的其他方法,比第二好的方法获得了3.16%的性能提升。对于ASSIST2015数据集,SAKT显示出15.87%的令人印象深刻的改进。我们将这一收益归因于这样一个事实,即SAKT利用的注意力机制即使在数据集稀疏的情况下也能很好地学习和概括,ASSIST2015就是这种情况,因为它的密度是其他数据集中最小的。对于STATICS2011,与DKT+相比,我们的方法获得了2.16%的性能提升。对于ASSISTChall,我们的方法的性能与DKT相当。这可以归因于ASSISTChall是所有实际数据集中密度最高的数据集。
1、粗体数字是最佳性能。2、通过对每个数据集分别进行最佳超参数选择来获得报告结果。
Attention weights visualization 注意权重可视化:可视化过去交互的要素(用作键)和学生接下来要解决的练习(用作查询)之间的注意权重可以帮助理解过去的交互中的哪些练习与查询练习相关。以此动机为基础,我们可以计算所有运动对(e1,e2)在所有序列中的注意权重之和,其中e1作为查询,与运动e2的交互作为键。然后,我们对注意力权重进行归一化,以使每个查询的权重之和为1。这将产生一个相关矩阵,其中每个元素(e1,e2)表示e2对e1的影响。我们对Synthetic进行分析,因为此数据集是用已知的隐藏概念生成的,因此关于不同练习的相关性的基本事实对我们来说是已知的。图3a显示了与Synthetic中练习的相关性矩阵相对应的热图。对于合成,所有序列均由相同的序列(从1到50)中的所有运动标签组成。
为了构建练习标签之间的影响图,如图3b所示,我们使用相关性矩阵。首先,我们提取出属于每个隐含概念的序列中的第一个练习,并访问关联矩阵的每一行,并将该行对应的练习与按边权重排序的前两个练习相关联,边权重与两个练习之间的注意力权重成正比。我们可以看到,在注意力权重的基础上,我们能够实现基于隐含概念的运动标签的完美聚类。一个有趣的观察是,两个在序列中相隔很远但属于同一个概念的练习可以被SAKT识别出来。例如,如图3b所示,对练习22的查询将大部分权重分配给练习5的键,即使它们在序列中出现的距离很远。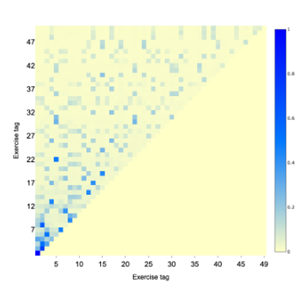

(a)每组练习之间的注意权重热图。注意,分配给pair (i, j)的权重,其中j > i总是0,因为所有的序列都由相同的顺序的练习组成
(b)描绘练习之间相关性的图表。相关性是由使用SAKT在练习之间学习的注意力权重来确定的。我们观察到潜在概念的完美群集。
图3:可视化合成数据集的注意力权重。
两个相互关联的练习往往具有较高的注意力权重,因为其中一个练习的表现会影响另一个练习的表现。此外,在现实世界的场景中,按顺序发生的练习往往属于同一概念。因此,我们预计注意力权重偏向于交互序列中最近发生的练习。为了说明这一点,我们手动分析了ASSIST2009数据集,以可视化一些选定样本的注意力权重。表4显示了一些练习,以及过去的交互和分配给每个交互的注意力权重。
1、 与练习标签对应的列是指查询(即,我们必须预测学生的表现的练习),而过去的交互分别是指为该学生观察到的交互序列。
2、 右栏中的红色元素表示过去交互元素中最重要的元素。
Ablation Study 消融研究:表5显示了默认SAKT架构和所有数据集(d=200)上的所有变体的性能。
没有位置编码 No Positional Encoding (PE):在这个默认架构的变体中,我们删除了位置编码。因此,用于预测学生在某一特定练习中的表现的注意权重仅取决于交互嵌入,而不受其在序列中的位置的影响。在ASSIST2009和ASSIST2015中,数据集是稀疏的,因此与ASSISTChall和STATICS等密集数据集相比,去除PE的影响不太明显。
无残差连接 No Residual Connection (RC):RCs显示了低水平特征的重要性,即在进行预测时的交互嵌入。由于我们的架构不是很深入,RC对模型的性能贡献不大。事实上,对于ASSIST2015数据集,删除残差连接可以提供比默认设置更好的性能。
No Dropout 无丢弃层:在神经网络中引入Dropout,对模型进行正则化处理,使其具有更好的泛化能力。与模型参数数量相比,模型的过拟合问题对于记录数较少的数据集更为有效。因此,对于ASSIST2009数据集和STATICS数据集,Dropout的作用更为有效。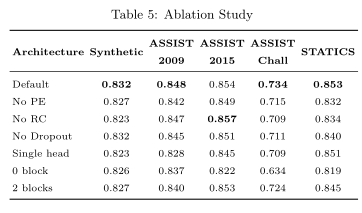
Single head 单头:我们尝试使用仅一个头的变体,而不是像默认体系结构那样使用5个头。多头有助于捕获不同子空间中的注意力权重。使用单头始终会降低SAKT在所有数据集上的性能。
No block 无注意力块:当不使用自我注意块时,对下一练习的预测仅取决于最后一次互动。可以看出,在没有注意阻塞的情况下,系统的性能比默认架构下的性能要差得多。
2 Blocks 2个注意力模块:增加自我关注块的数量会增加模型的参数数量。然而,在我们的例子中,这种参数的增加被证明对改进性能没有用处。这是因为预测学生在习题中的表现的一个重要方面取决于他在过去相关习题中的表现。再增加一块自我关注会使模型变得更加复杂。
Training efficiency 训练效率:图4根据训练阶段在GPU上的运行时间展示了各种方法的效率。对比计算效率,SAKT在一个epoch中只花费1.4秒,比DKT+(65秒/epoch)所花费的时间少46.42秒,比DKT(45秒/epoch)所花费的时间少32倍,比DKVMN(26秒/epoch)所花费的时间少17.33倍。我们在单个NVIDIA Titan V型的GPU上进行了实验。
5. CONCLUSION AND FUTURE WORK 结论与未来工作
在本研究中,我们提出了一个基于自我注意的知识追踪模型——SAKT。它模拟学生的交互历史(不使用任何RNN),并通过考虑学生过去交互的相关练习来预测他在下一个练习中的表现。在各种真实世界的数据集上进行的大量实验表明,我们的模型可以优于最先进的方法,并且比基于rnn的方法快一个数量级。
6. REFERENCES 参考文献
……

若有收获,就点个赞吧
0 人点赞
