tags: [知识追踪, GASKT]
categories: [知识追踪, GASKT]
知识跟踪(KT)是为学生定制个性化学习路径的基本工具,使他们能够掌握自己的学习节奏。KT的主要任务是对学生的学习状态进行建模,但过程相当复杂。首先,由于现实教育数据的稀疏性,以往的KT模型忽略了问题-技能中的高阶信息;其次,在处理长期依赖时,长序列的学生互动对KT模型提出了苛刻的挑战,最后,由于遗忘机制的复杂性。为了解决这些问题,本文提出了一种基于图的注意力知识搜索模型(GASKT)。该模型将问题和技能分为两类节点,利用R-GCN通过嵌入传播将问题-技能的相关性充分融入其中,降低了稀疏数据的影响。此外,它还采用改进的注意机制来解决长期依赖问题。对于问题间的注意力权重分数,在使用缩放点积的基础上,充分考虑了遗忘机制。我们在几个真实的基准数据集上进行了广泛的实验,我们的GASKT要优于最先进的KT模型,AUC至少提高了1%。
一、研究背景/目的
首先,由于现实教育数据的稀疏性,以往的KT模型忽略了问题-技能中的高阶信息;其次,在处理长期依赖时,长序列的学生互动对KT模型提出了苛刻的挑战(RNN缺点),最后,由于遗忘机制的复杂性。
二、解决方案
为了解决现有KT模型中存在的问题,在DKT-Forget[4]、EERNN[5]和GIKT[6]的启发下,我们提出的基于图的注意力知识搜索模型(GASKT)结合了记忆机制和高阶嵌入的优点。具体地说,与使用双向LSTM编码文本信息的EERNN不同,我们利用图神经网络来获得练习的嵌入。此外,注意到问题和技巧属于两种不同类型的节点,我们将它们之间的关系转化为一个异构图,并利用关系图卷积网络(R-GCN)[8]代替GCN(在GIKT中)来提取高阶信息。在使用LSTM对学生的知识状态进行建模的基础上,应用注意机制进一步增强了模型捕捉长期依赖的能力,并将其与遗忘行为有机地结合在一起。
三、主要贡献
1、我们使用R-GCN来提取问题和技能的高阶信息,并将问题和技能分为两类节点,然后构造相应的异构图。
2、我们充分考虑了遗忘机制,并采用修改后的注意机制来评价学生的未来表现。基于缩放的点积计算的相似度,我们在问题之间的注意力权重得分中加入了另外两个特征:时间距离和过去的试验次数。
3、在三个基准数据集上进行了实验,实验结果表明,GASKT与现有的解决方案相比,具有更好的性能和更高的可解释性。
四、问题定义&符号介绍

五、The GASKT Method
本节将详细说明我们的框架。GASKT由嵌入模块、知识演化模块、知识搜索模块和响应预测模块四个部分组成。图1显示了模型的整体框架。
5.1 Embedding Module
学生对新问题的回答是否正确,很大程度上取决于他们对类似问题和技能的掌握情况。因此,问题和技能之间的特征嵌入就显得尤为重要。然而,现有教育数据的稀缺性给KT的预测带来了严峻的挑战。在该模型中,为了迎接挑战,我们使用R-GCN[8]来完全提取问题-技能关联。
R-GCN[8]是GCN[7]的扩展,旨在处理大规模多关系数据。它们之间的关键区别在于,GCN包含相同类型的节点和边,因此它们共享相同的权重参数;而R-GCN具有不同类型的节点和边,只有属于相同类型的节点和边才会共享相同的参数。显然,问题和技巧属于不同类型的节点,因此我们选择R-GCN以异构图的形式表示它们之间的关系图。
我们构造了一个有向标签多图G=(V,E,R),其中节点v_i∈V,标签边(关系)(v_i,r,v_j)∈ε,r∈R是关系类型。在该模型中,有问题节点和技能节点两种类型的节点;两种类型的边,即(Problem,Container,Skill),(Skill,Conclude−by,Problem)。
the maximum number of the sampling layers L is set to 3 . multi-skilled problems are repeated multiple times, with each corresponding to a skill.
空间演化
R-GCN的计算包括以下两个步骤。首先,它计算并聚合每个关系的消息,其次,它聚合来自多个关系的结果。节点vi的l级的R-GCN公式可以表示如下:
5.2 Knowledge Evolution Module
交互嵌入

时间演化

5.3 Knowledge Search Module
在知识演化模块中,我们使用LSTM[2]对学生的知识状态进行建模。然而,LSTM在处理长序列时捕获长期依赖项的能力有限。为了克服这一局限性,我们应用修改后的注意力机制来增强模型的信息捕获能力。
问题嵌入作为Q、K,知识演化模块中LSTM层输出的ht作为K



5.4 Response Prediction Module

六、Experimental
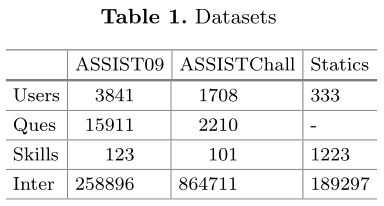
6.1 Datasets
6.2 Baseline & Overall Performance

6.3 Ablation Studies
R-GCN层的效果。表3列出了GASKT在L变化时的性能。特别地,当l=0时,节点嵌入被随机初始化。
修改后的注意力机制的效果。为了验证这两个遗忘因素的有效性,我们进行了以下实验。实验的详细结果可以在表4中找到。

七、结论
在本文中,我们提出了GASKT模型,该模型侧重于预测学习者对当前练习的掌握程度。该方法通过R-GCN提取问题和技能之间的高阶信息,并将注意力机制与LSTM相结合,深入挖掘当前练习和之前练习之间的依赖关系。此外,为了考虑遗忘机制,我们加入了两个遗忘因素,时间距离和过去的试验次数。实验结果表明,我们的方法在三个基准数据集上的性能优于最新的KT模型,并且表现出出色的可解释性。

若有收获,就点个赞吧
0 人点赞
