tags: [知识追踪, EERNN/EKT]
categories: [知识追踪, EERNN/EKT]
本文首先提出了一种基于学生练习记录和相应练习文本内容的神经网络(general Exercise-Enhanced Recurrent Neural Network)框架。在EERNN中,作者简单地将每个学生的状态总结成一个集成的向量,并用递归神经网络进行跟踪,其中设计了一个双向LSTM,从每个练习的内容中学习每个练习的编码。为了做出最终预测,在EERNN的基础上设计了两种不同预测策略的实现,即具有马尔可夫性质的EERNNM和具有注意力机制的EERNNA。然后,为了显式跟踪学生在多个知识概念上的知识习得,研究者将EERNN扩展为一个可解释的练习感知知识追踪(EKT)框架,将学生的综合状态向量扩展为知识状态矩阵,并将该框架扩展为可解释的Exercise-aware Knowledge Tracing(EKT)框架。在EKT中,进一步开发了一个记忆网络,用于量化每个练习在练习过程中对学生掌握多种知识概念的影响程度。
1、EERNN: Exercise-Enhanced Recurrent Neural Network
EERNN是一个通用的框架,可以在其中根据不同的策略预测学生的表现。具体地说,如图3所示,我们提出了两种在EERNN下的实现,即具有马尔可夫性质的EERNNM和具有注意力机制的EERNNA。因此,这两个模型对学生锻炼记录的建模过程是相同的,但遵循不同的预测策略。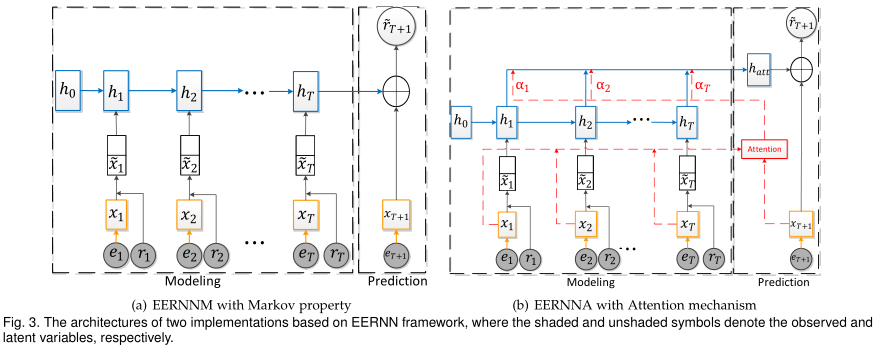
1.1 Modeling Process of EERNN
EERNN框架中建模过程的目标是对每个学生的练习顺序(使用输入符号s)进行建模。从图3可以看出,这个过程包含两个主要部分,即练习嵌入(标记为橙色)和学生嵌入(标记为蓝色)。
Exercise Embedding. 如图3所示,给定学生s={(e1,r1),(e2,r2),…,(et,rt)},练习嵌入从其文本内容ei自动学习每个练习的语义表示/编码xi。
图4显示了练习嵌入的详细技术。它是递归神经网络的一种实现,它的灵感来自于典型的被称为长时间短时记忆(LSTM)的神经网络[15],并进行了较小的修改。具体来说,给定练习内容为M个单词的序列ei={w1,w2,…,wm},首先利用Word2vec[31]将练习ei中的每个单词wi转换为d0维预训练单词嵌入向量, 。在初始化之后,练习嵌入使用公式中的先前隐藏状态vm-1更新每个第m个单词步长处的单词wm的隐藏状态
。在初始化之后,练习嵌入使用公式中的先前隐藏状态vm-1更新每个第m个单词步长处的单词wm的隐藏状态 ,如下所示:
,如下所示: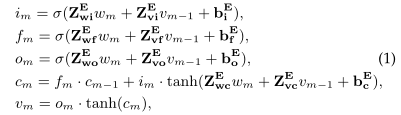
其中 分别表示三个门,即输入、遗忘、输出门。
分别表示三个门,即输入、遗忘、输出门。 是一种细胞记忆向量。σ(x)是非线性Sigmoid激活函数,·表示向量之间的元素乘积。此外,输入加权矩阵
是一种细胞记忆向量。σ(x)是非线性Sigmoid激活函数,·表示向量之间的元素乘积。此外,输入加权矩阵 、递归加权矩阵
、递归加权矩阵 和偏置加权向量
和偏置加权向量 都是练习嵌入的网络参数。
都是练习嵌入的网络参数。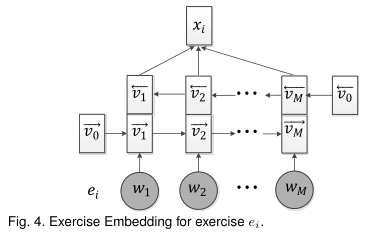
传统的LSTM模型通过单向网络学习每个单词的表示,并且不能利用来自未来单词标记的上下文文本[42]。为了充分利用每个练习的上下文单词信息,我们建立了一个双向LSTM,考虑了前后两个方向的单词序列。如图4所示,在每个单词步骤m,基于先前隐藏状态 和当前单词
和当前单词 两者计算具有隐藏字状态
两者计算具有隐藏字状态 的前向层;而后向层用未来隐藏状态
的前向层;而后向层用未来隐藏状态 和当前单词
和当前单词 更新隐藏字状态
更新隐藏字状态 。结果,每个单词的隐藏表示
。结果,每个单词的隐藏表示 可以用前向状态和后向状态的串联来计算:
可以用前向状态和后向状态的串联来计算: 。
。
然后,为了获得练习ei的完整语义表示,我们利用按元素最大池化操作将M个单词的上下文表示合并到全局嵌入 中,即
中,即 。
。
值得一提的是,Exercise Embedding直接从文本中学习每个练习的语义表示,而不需要任何专家编码。它还可以自动捕捉练习的特征(例如难度),并区分它们的个体差异。
Student Embedding. 学生嵌入是通过Exercise Embedding从文本内容ei中获得每个习题表征xi之后,再结合学生历史表现的影响,对学生的整个习题过程进行建模,学习学生在不同练习阶段的隐含表征,称为学生状态。如图3所示,EERNN假设学生的状态受到练习和她得到的相应分数的影响。
沿着这一思路,我们开发了一种用于学生嵌入的递归神经网络,该网络的输入为某一学生的练习过程s={(x1,r1),(x2,r2),.。。。,xt,rt)}。具体地说,在每个练习步骤t,网络的输入是具有练习嵌入xt和相应分数rt两者的组合编码。由于学生对同一练习的正确反应(即1分)和错误反应(即0分)实际上反映了他们的不同状态,因此我们需要找到一种适当的方法来区分这些对特定学生的不同影响。
Methodology-wise,我们首先将分值扩展为与练习嵌入xt具有相同2dv维度的特征向量0=(0,0,…,0),然后学习组合输入向量 :
: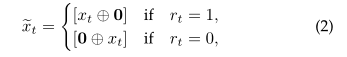
其中⊕表示两个向量的拼接操作。
学生的综合练习顺序 ,则基于递归公式中的当前输入
,则基于递归公式中的当前输入 和先前状态ht-1来更新在她的练习步骤t处的隐藏学生状态
和先前状态ht-1来更新在她的练习步骤t处的隐藏学生状态 为:
为: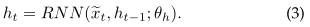
在文献中,有许多RNN形式的变体[6]、[15]。在本文中,考虑到学生练习序列的长度可以很长的事实,我们还通过复杂的lstm形式实现了Eq.(3),即ht=lstm(~xt,ht−1;θh),其可以在序列中保持更长期的依赖性,如下所示: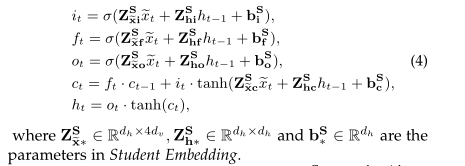
特别地,公式4中输入权重矩阵 可分为正
可分为正 和负
和负 两个部分,分别反映了特定学生在练习过程中正确反应和错误反应对练习炼的影响。基于这两种类型的参数,学生嵌入可以自然地模拟练习过程,通过整合练习内容和回答分数来获得学生状态。
两个部分,分别反映了特定学生在练习过程中正确反应和错误反应对练习炼的影响。基于这两种类型的参数,学生嵌入可以自然地模拟练习过程,通过整合练习内容和回答分数来获得学生状态。
1.2 Prediction Output of EERNN
在模拟了每个学生从练习步骤1到练习步骤T的练习过程之后,我们现在介绍预测每个学生在练习步骤T+1上表现的具体策略。心理学结果表明,学生的练习表现既取决于学生的状态,也取决于练习的特点[11]。根据这一发现,我们在EERNN框架下提出了两种预测策略的实现,即简单而有效的具有马尔可夫性质的EERNNM和更复杂的具有注意力机制的EERNNA,基于两种学习到的学生状态{h1,h2,…,hT}和练习嵌入{x1,x2,…,xT}。
EERNN with Markov Property. 对于一个典型的序列预测任务,马尔可夫性质是一个很好理解和广泛使用的理论,它假设下一个状态只取决于当前状态,而不取决于它之前的序列[37]。根据这一理论,如图3(a)所示,当在步骤T+1的练习eT+1被投递给学生时,EERNNM(1)假设该学生应用当前状态hT来解决该练习;(2)利用练习嵌入从练习文本eT+1中提取语义表示xT+1;(3)如下公式所示预测她在练习eT+1上的表现~rT+1: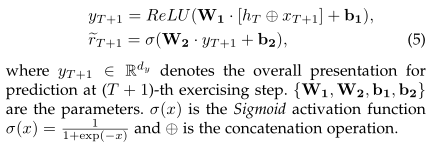
EERNNM为学生成绩预测提供了一种简单而有效的方法。然而,在大多数情况下,由于当前的学生状态hT是学生嵌入中基于LSTM的体系结构的最后一个隐藏状态,当序列太长时,它可能会丢弃一些重要信息,这被称为消失问题[18]。因此,EERNNM学习到的学生状态对于未来的表现预测可能有些不令人满意。为了解决这个问题,我们进一步提出了另一种复杂的预测策略,即具有注意力机制的EERNNA,以增强重要学生状态在预测练习过程中的效果。
EERNNA with Attention Mechanism. 在图1中,学生可能会在类似的练习中得到相似的分数,例如,学生1正确地回答了练习e1和e3,这可能是因为这两个练习因为相同的知识概念“函数”而相似。
根据这一观察,如图3(b)的红线所示,EERNNA假设第(T+ 1)个练习步骤的学生状态是所有历史学生状态的加权总和,基于练习eT+1和历史练习{e1, e2,…eT}。形式上,在下一步T+ 1中,我们定义学生的注意力状态向量 为:
为: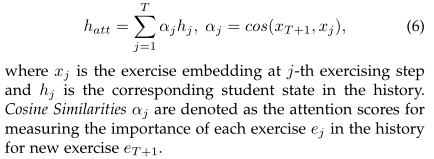
EERNNA在step T+ 1处获得注意力学生状态后,通过与Eq.(5)相似的运算,将hT替换为hatt,预测该学生在练习eT+1中的表现。
特别是,通过练习嵌入,我们的注意分数αj不仅从语法的角度衡量练习之间的相似性,还从语义的角度捕捉了练习之间的相关性(如难度相关性),有利于学生状态表征,用于学生成绩预测和模型解释。我们将对这种注意机制进行实验分析。
1.3 Model Learning
两种建议模型中需要更新的全部参数主要来自三个部分,即练习嵌入中参数 ,学生嵌入中的参数
,学生嵌入中的参数 和预测输出中的参数
和预测输出中的参数 。EERNN的目标函数是从步骤1到T观察到的学生练习过程序列的负对数似然率。形式上,在第t步,设
。EERNN的目标函数是从步骤1到T观察到的学生练习过程序列的负对数似然率。形式上,在第t步,设 为通过EERNN框架预测的练习et分数,rt是实际的二进制得分,从而定义某一学生的总损失为:
为通过EERNN框架预测的练习et分数,rt是实际的二进制得分,从而定义某一学生的总损失为: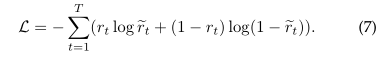
通过Adam优化器使目标函数最小化[22]。具体细节将在实验中详细说明。
2、EKT: Exercise-aware Knowledge Tracing
EERNN可以有效地处理预测学生在未来练习中的表现的问题。然而,在建模过程中,我们只是在一个集成的隐向量(即公式(4)中的ht)中总结和跟踪学生对所有概念的知识状态。这有时是不满意的,因为很难清楚地解释她掌握了多少特定的知识概念(例如,“函数”)。事实上,在某个学生的练习过程中,当给出一个习题时,她通常会运用自己的相关知识来解决它。相应地,她在练习中的表现,即她是否答对了,也可以反映她掌握了多少知识[7],[55]。例如,我们可以得出结论,图1中的学生已经很好地掌握了“函数”和“不等式”的概念,但需要把更多的精力放在不太熟悉的“概率”概念上。因此,如果我们能提醒她这一发现,以便她自己准备关于“概率”的目标训练,这是很有价值的。基于以上理解,在这一部分中,我们进一步探讨了在多个显性概念上跟踪学生知识获取的问题。我们对现有的EERNN进行了扩展,通过融合每个练习中存在的知识概念信息,提出了一个可解释的练习感知知识追踪(EKT)框架。
具体地说,我们将某个学生的知识状态从EERNN中的集成向量表示即 ,扩展到具有多个向量的矩阵即
,扩展到具有多个向量的矩阵即 ,其中每个向量表示她掌握了一个显式知识概念多大程度(例如,“函数”)。同时,在EKT中,我们假设学生的知识状态矩阵Ht随着时间的推移而变化,既受文本内容(即et)的影响,也受每个练习的知识概念(即kt)的影响。图5说明了EKT的总体架构。与EERNN(图3)相比,在建模过程中,除了练习嵌入模块外,还加入了另一个模块(标为绿色的模块),称为知识嵌入。有了这个附加功能,我们自然可以将所提出的预测策略EERNNM和EERNNA分别扩展到具有马尔可夫性的EKTM和具有注意力机制的EKTA。在本文中,我们首先介绍了知识嵌入模块的实现方法,然后详细介绍了EKTM和EKTA。
,其中每个向量表示她掌握了一个显式知识概念多大程度(例如,“函数”)。同时,在EKT中,我们假设学生的知识状态矩阵Ht随着时间的推移而变化,既受文本内容(即et)的影响,也受每个练习的知识概念(即kt)的影响。图5说明了EKT的总体架构。与EERNN(图3)相比,在建模过程中,除了练习嵌入模块外,还加入了另一个模块(标为绿色的模块),称为知识嵌入。有了这个附加功能,我们自然可以将所提出的预测策略EERNNM和EERNNA分别扩展到具有马尔可夫性的EKTM和具有注意力机制的EKTA。在本文中,我们首先介绍了知识嵌入模块的实现方法,然后详细介绍了EKTM和EKTA。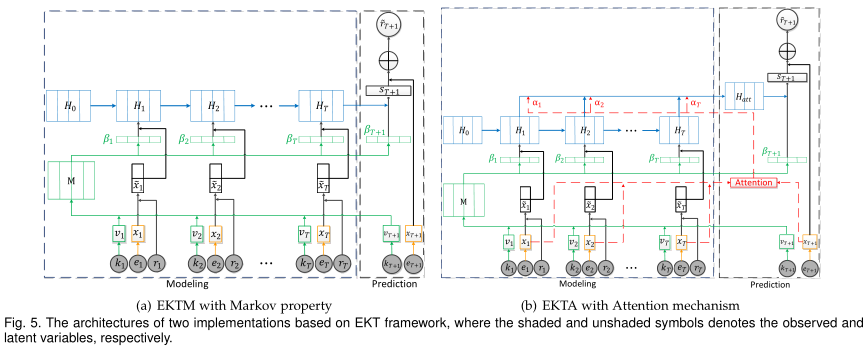
Knowledge Embedding. 给定学生的练习过程s={(k1,e1,r1),(k2,e2,r2),…,(kt,et,rt)},知识嵌入的目的是从该练习的知识概念kt中去探索每个练习对改善学生状态的影响,这个影响权重用βt表示。直观地说,在步骤t,如果这个练习与第i个概念有关,我们可以只考虑这个特定概念的影响,如果j=i,则βjt=1,否则βjt=0,0≤i,j≤k。然而,在教育心理学中,一些研究结果表明,在某个特定领域(如数学)中知识概念并不是孤立的,而是相互关联的[55]。因此,在我们的建模中,我们假设对于某个学生来说,学习一个概念也会影响其他概念的习得。因此,有必要对知识空间中所有K个概念之间的相关权重进行量化。
沿着这条线,如图5所示的模块(绿色标记),我们研究并提出了一个静态记忆网络来计算知识影响βt。具体来说,它是受记忆增强神经网络[16]、[41]的启发,该网络已成功应用于问答、语言建模、一次性学习等多个领域。它通常包含一个外部存储组件,可以存储稳定的信息。然后,在序列中,它可以读取每个输入,并从存储器中写入存储信息,以影响其长期依赖性。考虑到这一性质,我们建立了一个外部记忆矩阵 的存储模块,存储K个知识概念的dk维特征表示。
的存储模块,存储K个知识概念的dk维特征表示。
数学上,在每个练习步骤t,当一个练习et到来时,我们首先将它的知识概念设为one-hot编码 ,其维数等于所有概念的总数K。由于直观的一热表示对于建模来说过于稀疏[14],我们利用嵌入矩阵
,其维数等于所有概念的总数K。由于直观的一热表示对于建模来说过于稀疏[14],我们利用嵌入矩阵 将初始知识编码kt转移到具有连续值的低维向量
将初始知识编码kt转移到具有连续值的低维向量 中:
中: 。
。
之后,通过对给定的概念编码vt与记忆模块Mi中的每个知识记忆向量的内积再进行softmax运算,进一步计算练习et的知识概念kt对第i个概念的影响权重βit(1≤i≤K):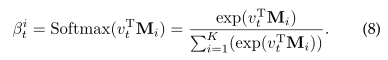
Student Embedding. 通过每个练习的知识影响βt,改进的Student Embedding将进一步指定某一学生在练习过程中的每个知识习得。因此,EKT可以自然地同时跟踪学生对多个概念的知识状态,有利于解释。
在方法上,在练习步骤t她回答了练习et后,我们也通过LSTM网络更新某一学生的特定知识状态中的一个, :
:
在对学生的历史练习过程进行建模之后,在EKT的预测部分,根据三种因素预测每个学生的表现,即她的历史知识状态{H1,H2,···,HT},她练习的嵌入{x1,x2,···,xT},以及候选练习的材料kT+1和eT+1。
EKTM with Markov property. 与EERNNM类似,EKTM遵循简单的马尔可夫性质,即假设学生在进一步练习中的表现只取决于她目前的知识状态HT。具体地说,如图5(a)所示,当练习eT+1发布时,EKTM首先将学生对此练习的掌握情况与其知识影响βT+1整合为: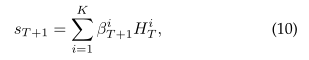
然后通过改变Eq.(5)中的类似运算来预测她的表现~rt +1: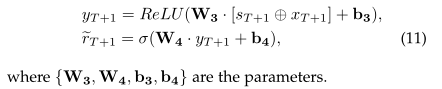
EKTA with Attention mechanism. EKTA也遵循复杂的注意机制,以增强历史中重要状态对预测学生未来表现的影响,如图5(b)所示。这里,与EERNNA相比,稍加修改的是,我们将Eq.(6)中学生的注意状态向量hatt扩展为矩阵Hatt,其中每个知识状态槽 可计算为:
可计算为: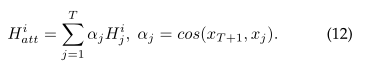
然后,通过将HT替换为Hatt,EKTA用Eq.(10)和Eq.(11)生成对练习eT+1的预测。
在此之后,我们可以通过最小化公式(7)中相同目标函数来训练EKT。请注意,在我们的建模过程中,EKT框架可以通过影响权重βt学习到矩阵Ht来提高可解释性,它可以告诉我们某个学生在练习步骤t时对每个概念的掌握程度,我们将在下一节讨论具体细节。
3、APPLICATION
在讨论了EERNN和EKT的训练阶段之后,我们提出了如何应用EERNN和EKT模型来实现两个激励目标,即学生成绩预测和知识获取跟踪。
Student Performance Prediction. 学生成绩预测作为智能教育的主要应用之一,学生成绩预测有助于为学生提供更好的主动服务,如个性化练习推荐[25]。EERNN和EKT都可以直接实现这一目标。
Knowledge Acquisition Tracking.
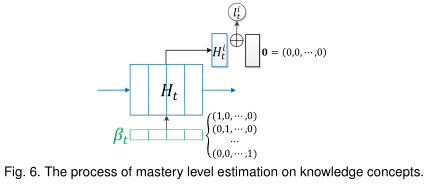
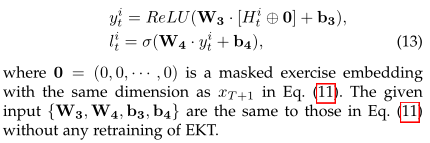
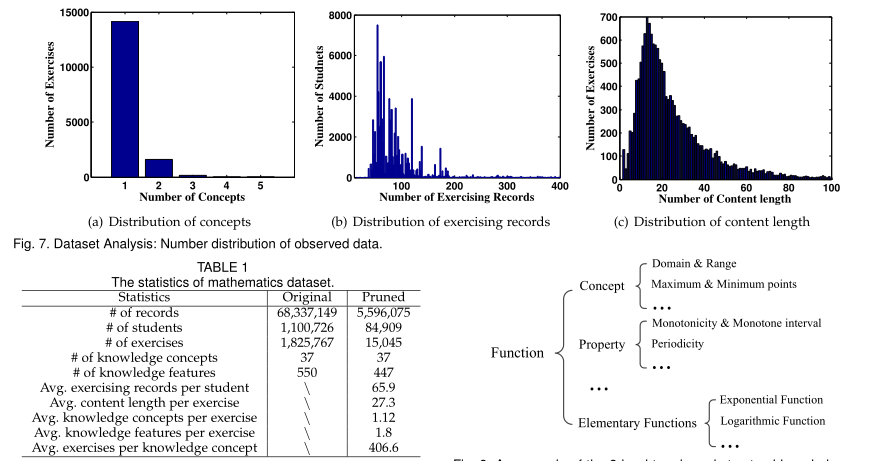
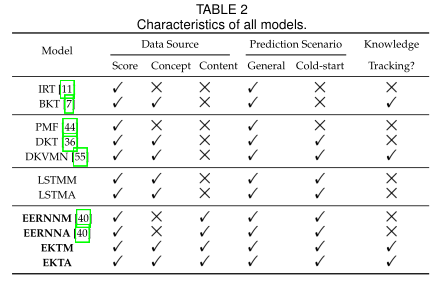
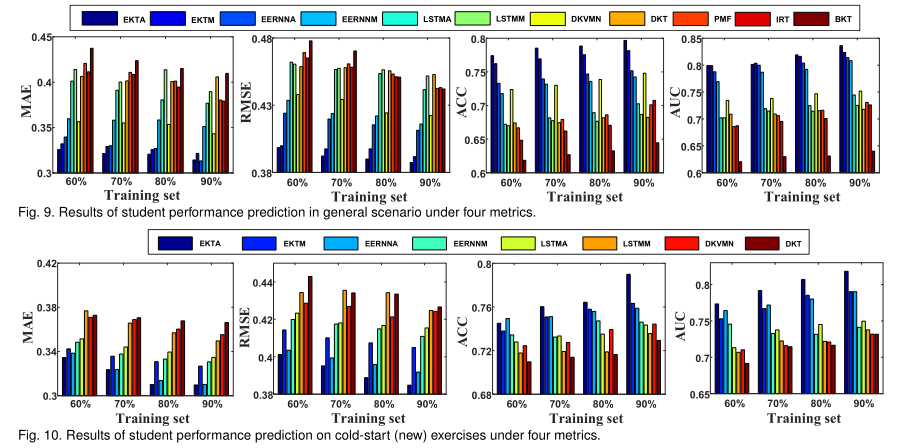
4、EXPERIMENTS

若有收获,就点个赞吧
0 人点赞
