二维
我们的数据将会是值 x_1,_x_2,…,_x__m, 而我们的标签将会是值 y_1,_y_2,…,_y__n. 我们将权重记为 w_1, 和 _w_2. 因此,我们的预测是 _y__i^=w_1_x__i+w_2. 平均平方误差是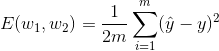
我们需要最小化误差函数。因此, _m_1 可以被忽略。现在替换 _y^, 值,我们得到
修正:上方公式中第一行缺少一个1/2。
现在,为了最小化这一误差函数,我们需要将 w_1 和 _w_1 的导数设置为 0.
使用链式规则,我们得到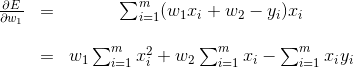
和
将以上两则公式设置为 0 ,我们得到一下两则公式和两个变量 (这里变量是 _w_1 和 _w_2)。
修正:上方第二行公式中最后的x_i应更改为y_i。
我们可以用任何方法来求解 2 个方程和 2 个变量。 例如,如果我们将第二个方程乘以 ∑_i=1mxi, 第一个乘以 m, 两者相减得到值 _w_1, 然后在第一个方程中替换该值,我们得到如下结果:
这是我们理想的答案。
n-维度
当我们的数据有n 个维度时,而不只是 2个,我们需要介绍一下的表示法。我们的矩阵 X 包含的数据如接下来所示,每一行都是我们的 datapoint, 在此 x_0(_i)=1 表示偏差。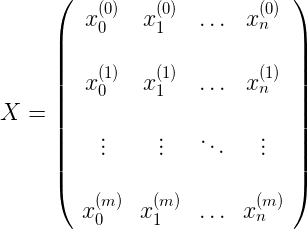
我们的标签是向量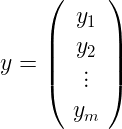
而我们的权重矩阵如下所示: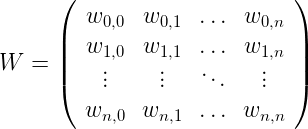
所以,平均平方误差的方程可写成如下矩阵乘积:
E(W)=m_1((_XW)T−y__T)(XW−y).
因为我们需要最小化平均平方误差,我们可以先忘记 m_1, 展开公式,我们得到
_E(W)=WTXTXW−(XW)T__y−y__T(XW)+yTy.
注意在上面的总和中,第二和第三项是相同的,因为它是两个向量的内积,这意味着它是它的坐标乘积之和。 因此,
E(W)=WTXTXW−2(XW)T__y+yTy.
为了最小化,我们需要对矩阵中的所有值采取导数 W.使用上方我们使用的链式规则,我们得到以下结果: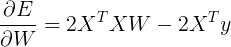
为了将这个设置为0,我们需要
XTXW−XTy=0, 或者等同于,
W=(XTX)−1XTy.


若有收获,就点个赞吧
0 人点赞
