- Python 标识符
- 关键字
- 基础数据类型
- python中的数学运算
- 字符串
- 单引号(‘ ‘)、双引号(“ “)、三引号(“”” “””)
- 字符串的拼接
- 字符串修改
- 字符串转换为大写
- 字符串转换为小写
- 第一个单词首字母大写
- 转换为英文标题模式,单词首字母大写
- 剪切掉字符串首尾出现的最长字符,默认剪切掉首尾的空格
- 后面的字符串替换前面的字符串。符号替换的时候,不一定是一对一,可以是多对一,一对多,多对多
- zfill() Pad a numeric string with zeros on the left, to fill a field of the given width.
- ljust() 返回长度和宽度为左对齐的字符串。
- rjust() 返回长度和宽度为右对齐的字符串。
- center() 返回在左右两端填充指定字符(默认空格)到达一定长度的字符串
- count() 返回指定字符串的个数
- isupper() 判断字符串中的字符是否全部都是大写字母
- islower()小判断字符串中的字符是否全部都是写字母
- index() 返回指定字符串出现的位置。若没有找到直接报错。
- find() 返回指定字符串出现的位置。返回-1若没有找到。
- len() 字符串的长度
- string.ascii_letters
- string.digits
- join()
- 字符与编码的转换
- 字符串也可以使用十六进制表示
- str转化为 bytes encode() decode()
- 字符串的格式化表示
- 切片查询
- 数字与字符的判断
- 小练习
- list
- dict
- tuple
- set
- 流程判断语句
Python 标识符
- 在python里,标识符由字母、数字、下划线组成。
- 以下划线开头的标识符是由特殊意义的。以单下划线开头_foo的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用from xxx import * 而导入。
以双下划线开头的foo代表类的私有成员,以双下划线开头和结尾的foo代表python里特殊方法专用的标识,如init__()代表的初始化函数(C++的构造函数)。
关键字
基础词
is,None,global,not,with,as,or,yield,assert,import,in
流程词
True,False,try,finally,except,continue,for,if,elif,else,break,raise
函数词
-
对象词
-
基础数据类型
分为 int、 float、string三种。
a = 1 # 强类型 动态类型——变量本身类型不固定
python中的数学运算
- + - * / 与数学中的运算方式相同
- // -> 除法运算,取商
6 // 5 # 结果是 1
- % -> 取模运算 除法运算取余数
6 % 5 -> # 结果是1
数学计算库
四舍五入
round(3.8) # 结果是 4round(3.1) # 结果是 3
返回当前最大的整数
math.floor(3.9) # 3math.floor(-3.9) # -4
pi
math.pi # 3.141592653589793
欧式距离 ( Return the Euclidean distance, sqrt(x*x + y*y).)
math.hypot(3,4) # 5
pow()
math.pow(3,2) # 93 ** 2 # 9
e
math.e # 2.718281828459045
exp() (Return e raised to the power of x.
)
math.exp(2)
log
math.log(math.e) # 1.0
log2
math.log2(8) # 3.0
运算符与他们的用法
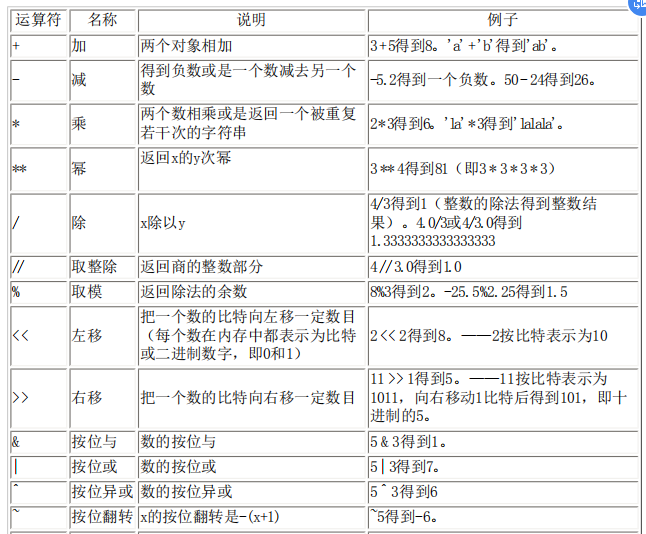
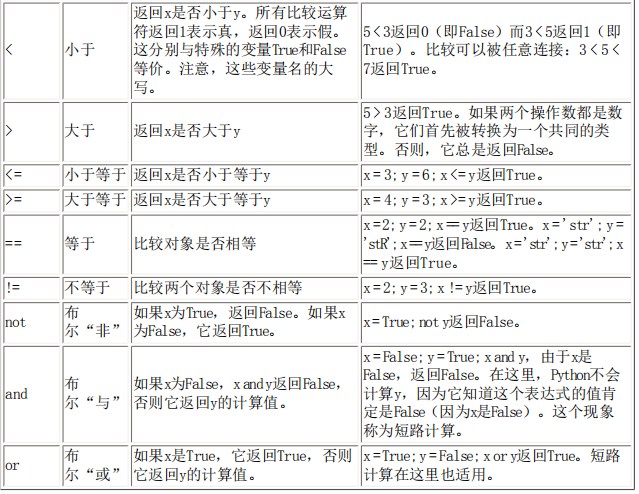
运算符优先级(由低到高)
- and 逻辑与 or 逻辑或 遵循 短路运算,返回最后一个可以判断真假的值。
字符串
单引号(‘ ‘)、双引号(“ “)、三引号(“”” “””)
- 三引号中可以在字符串中换行。字符串可以使用连接符 \ 将第n行和n-1行的字符连接在一起。
- 三种引号可以嵌套使用。

字符串的拼接
"8" * 5 # '88888'str1 = "str1"str2 = "str2"str3 = str1 + str2print(str3) # str1str2str1 = "str1"str2 = "str2"str3 = 'str1:%s , str2:%s' %(str1,str2)print(str3) # str1:str1 , str2:str2str1 = "str1"str2 = "str2"str3 = 'str1:{} , str2:{}'.format(str1,str2)print(str3) #str1:str1 , str2:str2str1 = "str1"str2 = "str2"str3 = 'str1:{strA} , str2:{strB}'.format(strA = str1,strB = str2)print(str3) # str1:str1 , str2:str2str1 = "str1"str2 = "str2"str3 = f'str1:{str1} , str2:{str2}'print(str3) # str1:str1 , str2:str2
字符串修改
字符串转换为大写
str1 = "abc"print(str1.upper()) # ABC
字符串转换为小写
str1 = "aBc"
print(str1.lower()) # abc
第一个单词首字母大写
str1 = "abc bd"
print(str1.capitalize()) # Abc bd
转换为英文标题模式,单词首字母大写
str1 = "abc bd"
print(str1.title()) # Abc Bd
剪切掉字符串首尾出现的最长字符,默认剪切掉首尾的空格
str1 = "ene + twe"
print(str1.strip("we")) # ne + t
后面的字符串替换前面的字符串。符号替换的时候,不一定是一对一,可以是多对一,一对多,多对多
str1 = "str1"
print(str1.replace("1","2")) # str2
zfill() Pad a numeric string with zeros on the left, to fill a field of the given width.
str1 = "str1"
print(str1.zfill(30)) # 00000000000000000000000000str1
ljust() 返回长度和宽度为左对齐的字符串。
str1 = "str1"
print(str1.ljust(30,"@")) # str1@@@@@@@@@@@@@@@@@@@@@@@@@@
rjust() 返回长度和宽度为右对齐的字符串。
str1 = "str1"
print(str1.rjust(30,"@")) # @@@@@@@@@@@@@@@@@@@@@@@@@@str1
center() 返回在左右两端填充指定字符(默认空格)到达一定长度的字符串
str1 = "str1"
print(str1.center(7,"@")) # @@str1@
count() 返回指定字符串的个数
str1 = "str1"
print( str1.count("st")) # 1
isupper() 判断字符串中的字符是否全部都是大写字母
str1 = "str1"
print(str1.isupper()) # False
islower()小判断字符串中的字符是否全部都是写字母
str1 = "str1"
print(str1.islower()) # True
index() 返回指定字符串出现的位置。若没有找到直接报错。
str1 = "str1"
print( str1.index("tr"))# 1
find() 返回指定字符串出现的位置。返回-1若没有找到。
str1 = "str1"
print(str1.find("t")) # 1
print(str1.find("d")) # -1
len() 字符串的长度
str1 = "str1"
print(len(str1)) # 4
string.ascii_letters
print(string.ascii_letters) # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
string.digits
import string
print(string.digits) # 0123456789
join()
print("".join(["sd","sds","121"])) #sdsds121
字符与编码的转换
- 对于单个字符的编码,Python提供了ord()函数获取字符的编码表示,chr()函数把编码转换为对应的字符:
a = ord("A")
b = chr(66)

字符串也可以使用十六进制表示
a = '\u4e2d\u6587'

str转化为 bytes encode() decode()
- 由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
- Python对bytes类型的数据用带b前缀的单引号或双引号表示。
a = b'haha'
b= type(a)
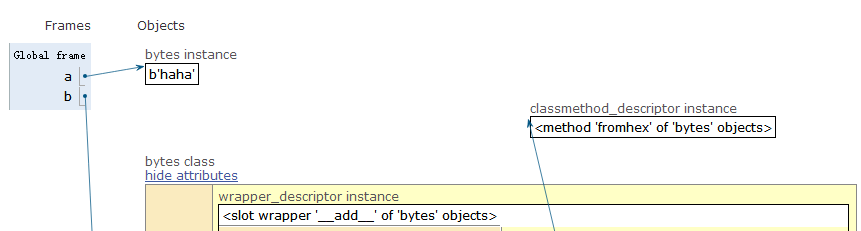
- 以Unicode表示的str通过encode()方法可以编码为指定的bytes
a = "ABC".encode("ascii")
b = "中文".encode("utf-8")
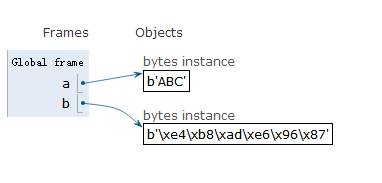
- 如果我们从网络上或者磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法。
c = b'\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8")
d= b"ABC".decode("ascii")

len() 计算的是str的字符数,如果是bytes,则计算的是字节数
a = len("中文")
b = len(b"ABC")
c = len("中文".encode("utf-8"))

字符串的格式化表示
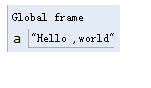
a = "Hello ,%s"%"world"
%是使用%进行转义的,即 %%表示%。
切片查询
str[start:end:step]
str[开始的索引(不写,从0开始;可以为负值,意味着字符串倒数):结束的索引(不写,到字符串的末尾;可以为负值,意味着字符串倒数):每次获取数据移动的步长(不写,默认为1;可以为负值,意味着字符串倒数时的步长)]
str[::-1] # 字符串反转
数字与字符的判断
isalpha() Return True if the string is an alphabetic string, False otherwise.
str1 = "abcdefg"
print(str1.isalpha()) # True
判断数字
- isnumeric(能数数的 包括汉字) > isdigit(数字) > isdecimal(十进制)
小练习
打印九九乘法表
dic = {
1:"一",
2:"二",
3:"三",
4:"四",
5:"五",
6:"六",
7:"七",
8:"八",
9:"九",
0:"十"
}
for i in range(9,0,-1):
for j in range(1,i+1):
left = dic.get((i * j)//10)
if not left or left == "十":
left = " "
right = dic.get((i * j)%10)
print(f"{dic.get(j)} * {dic.get(i)} = {left}{right} ",end="")
print()
token生成器
import string
import random
alternative = string.ascii_letters + string.digits
count = 10
print("".join([random.choice(alternative) for _ in range(count)]))
list
list1 = []
list2 = list()
list3 = [1,2,3]
list3 = list([1,2,3])
list5 = list((1,2,3))
list1 = ["a"*3]
list2 = [["b"]*3]
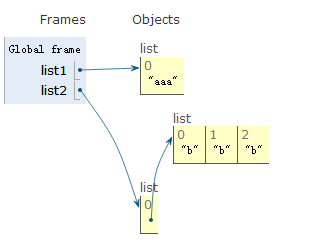
list 嵌套
list1 = [1,2,3,[4,5,6]]
增加数据
list1 = [1,2,3,[4,5,6]]
list1.append("a") # 在列表后面追加

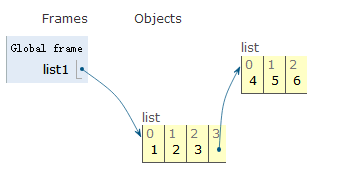
list1 = [1,2,3]
list1.insert(1,4)
切片操作
获取指定元素的个数
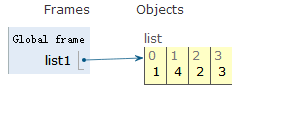
list1 = [1,2,3,1]
a = list1.count(1)
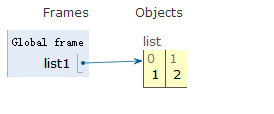
列表逆序
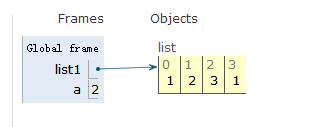
list1 = [1,2,3]
a = list1.reverse()
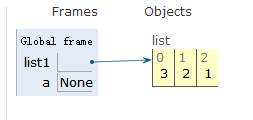
列表移除数据
list1 = [1,2,3]
list1.pop(1)
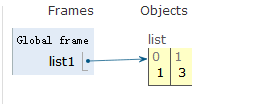
list1 = [1,2,3]
list1.pop() # 默认移除最后面的数据
dict
初始化
dict1 = {1:"a",2:"b"}

获取dict中的值
dict1 = {1:"a",2:"b"}
a = dict1.get(1) # 若key值不存在,程序会返回None
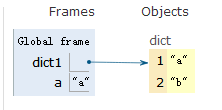
dict1 = {1:"a",2:"b"}
a = dict1[1] # 若key值不存在,程序会报错——KeyError
dict增加值
dict1 = {1:"a",2:"b"}
dict1[3]="c"

dict移除数据
dict1 = {1:"a",2:"b"}
del dict1[1] # 若key值不存在,程序会报错——KeyError

获取dict的key值
dict1 = {1:"a",2:"b"}
a = dict1.keys()
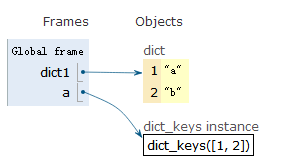
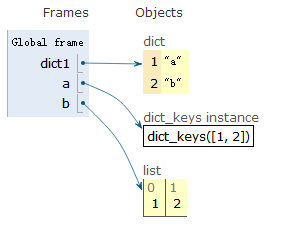
使用key值
dict1 = {1:"a",2:"b"}
a = dict1.keys()
b = [i for i in a]
获取dict的value值
dict1 = {1:"a",2:"b"}
a = dict1.values()
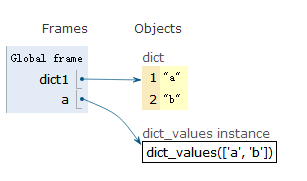
使用value值
dict1 = {1:"a",2:"b"}
a = dict1.values()
b = [i for i in a]
同时获取key value值
dict1 = {1:"a",2:"b"}
a = dict1.items()
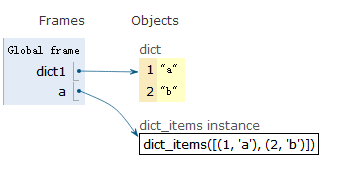
同时成对获取key value 值
dict1 = {1:"a",2:"b"}
a = dict1.items()
b = [i for i in a]
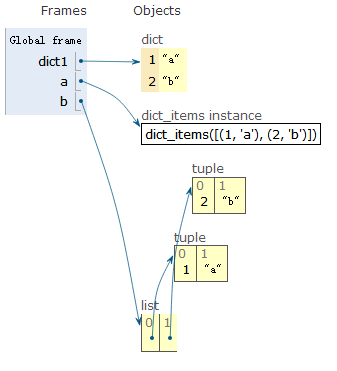
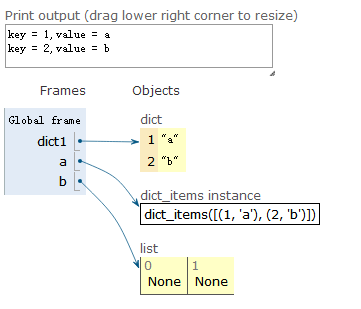
分别获取key与value值
dict1 = {1:"a",2:"b"}
a = dict1.items()
b = [print(f"key = {k},value = {v}") for k,v in a]
dict 与 list的对比
- 和list比较,dict有一下几个特点:
- 1.查找和插入的速度极快,不会随着key的增加而变慢
- 2.需要占用大量的内存,内存浪费多
- 而list相反:
- 1.查找和插入的时间随着元素的增加而增加
- 2.占用空间小,浪费内存很少
- 所以,dict是用空间来换取时间的一种方法。
- dict 中这个通过key计算位置的算法成为哈希算法(Hash)
tuple
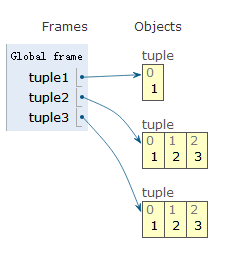
初始化
tuple1 = (1,) # 如果元组只有一个元素,定义的时候必须加一个逗号,来消除歧义。
tuple2 = (1,2,3)
tuple3 = tuple([1,2,3])
tuple4 = ()
可变的“tuple”
t = ("a","b",["A","B"])
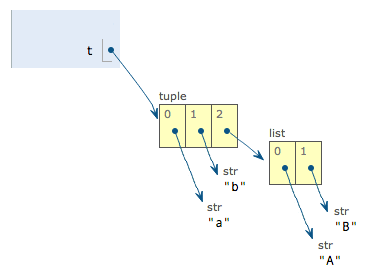
接下来执行下面的语句
t[2][0] = "X"
t[2][1]="Y"
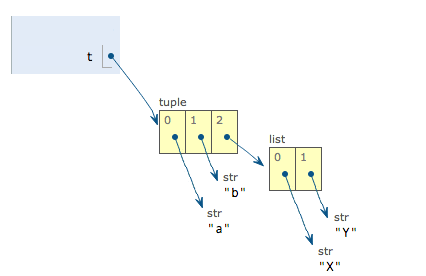
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改变成为别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向“a”,就不能指向“b”,指向一个list,就不能改为指向其他的对象,但指向的这个list本身是可变的。
那若要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
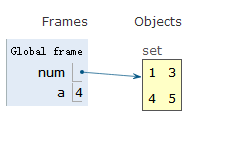
set
- set集合里面的数据不可以重复
num = {1,1,3,4,5}
a= len(num) # 请注意个数
流程判断语句
if
if 条件:
pass
elif 条件:
pass
else :
pass
for
for i in 集合:
pass
else: # 当for循环完了所有元素,才走else
pass
while
while 条件:
pass
else: # 与for的使用方法一样
pass

若有收获,就点个赞吧
0 人点赞
